Flink SQL如何实现数据流的Join
Flink是一个开源的流处理框架,可以用于实时处理和分析大规模的数据流。Flink提供了SQL接口,使得用户可以使用SQL语句来查询和分析数据流。在Flink SQL中,数据流的Join操作是非常重要的,它允许将多个数据流按照指定的条件进行关联,并生成一个新的数据流。
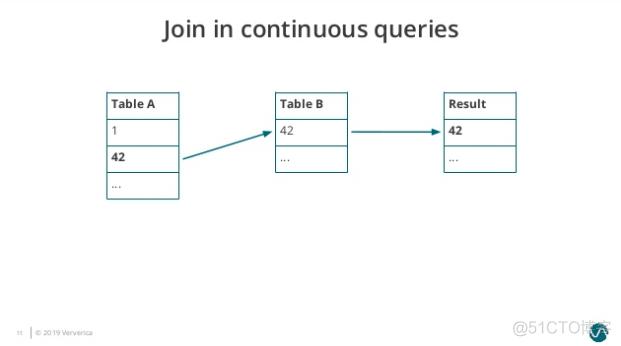
在Flink SQL中,数据流的Join操作可以通过使用JOIN关键字来实现。JOIN关键字用于将两个或多个数据流进行关联,关联的条件可以是相等性条件、不等条件或其他复杂的条件。Flink SQL支持多种类型的Join操作,包括内连接、外连接和半连接。
首先,我们来看一下内连接(Inner Join)操作。内连接是最常用的Join操作,它只返回那些在两个数据流中都存在的记录。在Flink SQL中,可以使用INNER JOIN关键字来执行内连接操作。例如,假设有两个数据流A和B,它们的结构如下所示:
数据流A:
id | name
---|-----
1 | Alice
2 | Bob
数据流B:
id | age
---|----
1 | 20
3 | 30
如果我们想要将数据流A和数据流B按照id字段进行内连接,可以使用以下的Flink SQL语句:
```sql
SELECT A.id, A.name, B.age
FROM A
INNER JOIN B ON A.id = B.id
```
执行上述语句后,将得到以下结果:
id | name | age
---|------|----
1 | Alice| 20
可以看到,只有在数据流A和数据流B中都存在的记录才会被返回。
除了内连接,Flink SQL还支持外连接(Outer Join)操作。外连接是一种更加灵活的Join操作,它可以返回那些在一个数据流中存在而在另一个数据流中不存在的记录。在Flink SQL中,可以使用LEFT OUTER JOIN或RIGHT OUTER JOIN关键字来执行外连接操作。例如,假设有两个数据流A和B,它们的结构如下所示:
如果我们想要将数据流A和数据流B按照id字段进行左外连接,可以使用以下的Flink SQL语句:
LEFT OUTER JOIN B ON A.id = B.id
2 | Bob | NULL
可以看到,所有在数据流A中存在的记录都会被返回,而在数据流B中不存在的记录的age字段将被设置为NULL。
最后,Flink SQL还支持半连接(Semi Join)操作。半连接是一种特殊的Join操作,它只返回那些在一个数据流中存在而在另一个数据流中不存在的记录的某些字段。在Flink SQL中,可以使用SEMI JOIN关键字来执行半连接操作。例如,假设有两个数据流A和B,它们的结构如下所示:
如果我们想要将数据流A和数据流B按照id字段进行半连接,可以使用以下的Flink SQL语句:
SELECT A.id, A.name
SEMI JOIN B ON A.id = B.id
id | name
---|------
可以看到,只有在数据流A中存在而在数据流B中不存在的记录会被返回。
综上所述,Flink SQL提供了丰富的Join操作来满足不同场景下的需求。通过使用JOIN关键字和指定合适的条件,用户可以轻松地实现数据流的Join操作。