

引言:大語言模型中的機器遺忘問題
在人工智能領域,大語言模型(LLMs)因其在文本生成、摘要、問答等任務中展現出的卓越能力而備受關注。然而,這些模型在訓練過程中可能會記住大量數據,包括敏感或不當的信息,從而引發倫理和安全問題。爲了解決這些問題,機器遺忘(Machine Unlearning,MU)技術應運而生,旨在從預訓練模型中移除不良數據的影響及其相關模型能力,同時保持對其他信息的完整知識生成,而不影響因果無關的信息。機器遺忘在大語言模型的生命周期管理中扮演着關鍵角色,它不僅有助于構建安全、可信賴的生成型AI,還能在不需要完全重新訓練的情況下提高資源效率。
論文标題:RETHINKING MACHINE UNLEARNING FOR LARGE LANGUAGE MODELS
公衆号「夕小瑤科技說」後台回複“機器遺忘”獲取論文pdf。
機器遺忘(MU)的定義與重要性
1. MU在大語言模型(LLM)中的應用
機器遺忘(Machine Unlearning, MU)是一種新興的技術,旨在從預訓練的大語言模型(LLM)中消除不良數據的影響,例如敏感或非法信息,同時保持對基礎知識生成的完整性,并且不影響與之無關的信息。在大語言模型中,MU的應用包括但不限于文本生成、摘要、句子完成、改寫和問答等生成性任務。例如,Eldan & Russinovich (2023) 使用MU策略來防止生成《哈利·波特》系列的版權材料。
2. 遺忘不良數據影響的必要性
大語言模型因其能夠記憶大量文本而備受關注,但這也可能導緻包括社會偏見、記憶個人和機密信息等道德和安全問題。因此,精确地遺忘這些不良數據對于确保LLM的安全性、可靠性和信任度至關重要。此外,考慮到LLM的訓練成本高昂且耗時,重新訓練以消除不良數據的影響通常是不切實際的,這使得MU成爲一種可行的替代方案。
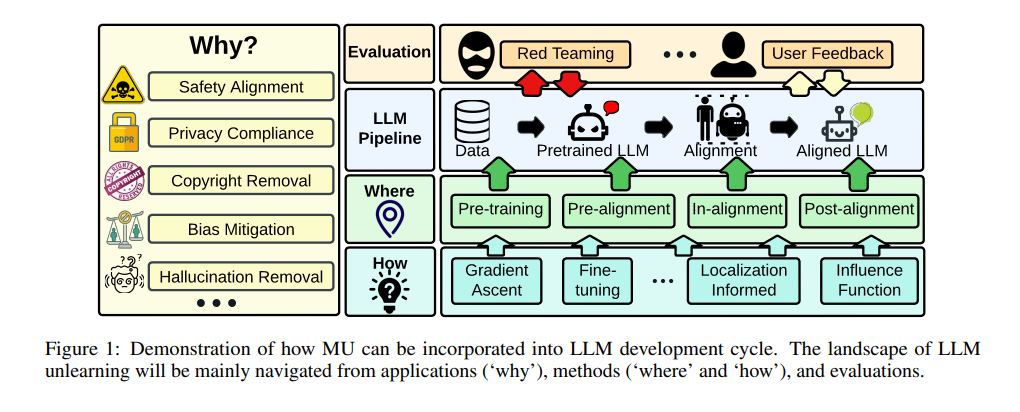
LLM遺忘的挑戰與現狀
1. 遺忘目标的界定問題
在LLM中精确定義和定位“遺忘目标”是一項挑戰,因爲這些目标可能是訓練集的子集或需要被移除的知識概念。當前的研究通常是上下文和任務依賴的,缺乏标準化的語料庫來進行LLM遺忘。
2. 數據與模型交互的複雜性
随着LLM的規模增長,開發可擴展和适應性強的MU技術變得更加複雜。這不僅影響性能評估,而且由于缺乏重新訓練作爲基準,評估的準确性也受到影響。例如,研究提出了上下文遺忘和虛構遺忘的方法,前者允許在黑盒模型上進行遺忘,後者提供了重新訓練的替代方案。
3. 遺忘效果的多面性評估
遺忘的範圍往往沒有明确規定,這與模型編輯中面臨的挑戰相似。有效的遺忘應确保LLM删除目标數據的知識,同時保持對該範圍之外數據的效用。此外,盡管LLM遺忘在多種應用中具有潛力,但目前缺乏全面和可靠的評估。
-
例如,最近的研究表明,即使在編輯模型以删除敏感信息的努力之後,這些信息仍可能從編輯後的模型中被逆向工程出來,這突顯了進行徹底和對抗性評估的必要性,以及設計更多機械性方法以保證遺忘的真實性。
遺忘方法的探索與評估
1. 模型基方法與輸入基方法
在探索大語言模型(LLMs)的遺忘方法時,研究者們主要集中在模型基方法和輸入基方法兩大類。
-
模型基方法涉及修改LLMs的權重或架構組件以實現遺忘目标,例如通過梯度上升或其變體來更新模型參數,使得模型對于遺忘集(Df)中的樣本産生誤預測的可能性最大化。

(圖爲基于模型的圖像編碼基本原理框架圖)
-
輸入基方法則設計輸入指令,如上下文示例或提示,來引導原始LLM(無需參數更新)達到遺忘目标。
2. 影響函數與梯度上升變體
影響函數是評估數據移除對模型性能影響的标準方法,但在LLM遺忘的背景下并不常用,主要是因爲涉及到求逆Hessian矩陣的計算複雜性,以及使用近似法導出影響函數時的準确性降低。
梯度上升(Gradient Ascent,GA)是一種直接的遺忘方法,通過最大化遺忘集Df中樣本的誤預測可能性來更新模型參數。GA的變體包括将其轉換爲梯度下降方法,目的是最小化重新标記遺忘數據上的預測可能性。
3. 本地化知識遺忘
本地化知識遺忘的目标是識别和定位對遺忘任務至關重要的模型單元(例如層、權重或神經元)。
-
例如,通過表示去噪或因果追蹤來完成模型層的本地化,或者使用基于梯度的顯著性來識别需要微調以實現遺忘目标的關鍵權重。
這種方法的目的是在保護模型對非遺忘目标數據的效用的同時,确保LLMs删除目标數據的知識。
遺忘效果的評估框架
1. 與重訓練的比較
在傳統的遺忘範式中,從頭開始重訓練模型并從原始訓練集中移除被遺忘的數據被視爲精确遺忘。然而,由于重訓練LLMs的可擴展性挑戰,很難建立評估LLM遺忘性能的上限。最近的解決方案是引入虛構數據(合成作者檔案)到模型訓練範式中,模拟在新引入的集合上的重訓練過程。
2. 魯棒性評估與“硬”範圍内的例子
遺忘的有效性指标之一是确保對于遺忘範圍内的例子,即使是那些與遺忘目标直接相關的“硬”例子,也能實現遺忘。評估“硬”範圍内的例子可以通過技術如改寫LLMs打算遺忘的内容或創建多跳問題來實現。
3. 訓練數據檢測與隐私保護
成員推斷攻擊(Membership Inference Attack,MIA)旨在檢測數據點是否是受害模型訓練集的一部分,這是評估機器遺忘方法的一個關鍵隐私揭示指标。在LLM遺忘的背景下,特别是當重訓練不是一個選項時,這一概念變得更加重要。
LLM遺忘的應用領域
1. 版權與隐私保護
在LLM遺忘的應用中,版權與隐私保護占據了重要的位置。
-
例如,機器遺忘(MU)被用于防止生成哈利波特系列的版權材料(Eldan & Russinovich, 2023)。

這一應用不僅涉及法律和倫理考量,還涉及到數據的合法使用。在美國,聯邦貿易委員會(FTC)要求一家公司徹底銷毀因未經合法同意而訓練的模型,這一做法被稱爲算法性吐露(algorithmic disgorgement)。LLM遺忘提供了一種可行的替代方法,可以通過移除非法數據的影響來避免完全銷毀模型。
版權保護内容的删除與确定訓練數據的确切來源需要删除的問題相關,這引發了數據歸屬問題。
-
例如,與哈利波特系列相關的洩露可能有多種原因,例如書籍被用于LLM的訓練數據,或者訓練數據包含與系列相關的在線讨論,或者LLM使用檢索增強生成(retrieval-augmented generation),可能導緻從搜索結果中洩露信息。
除了從訓練數據中删除版權信息外,還有防止LLM洩露用戶隐私的場景,特别是個人識别信息(PII)。這一關切與LLM記憶和訓練數據提取密切相關。
2. 社會技術傷害減少
LLM遺忘的另一個應用是對齊(alignment),旨在使LLM與人類指令對齊,并确保生成的文本符合人類價值觀。遺忘可以用來忘記有害行爲,如産生有毒、歧視性、非法或道德上不可取的輸出。遺忘作爲安全對齊工具,可以在LLM開發的不同階段進行。目前的研究主要集中在“預對齊”階段(Yao et al., 2023),但在其他階段可能存在未開發的機會。例如在對齊之前、期間或之後。
幻覺是LLM面臨的一個重大挑戰,它涉及生成虛假或不準确的内容,這些内容可能看起來是合理的。先前的研究表明,遺忘可以通過針對特定問題并遺忘事實上不正确的回應來減少LLM的幻覺(Yao et al., 2023)。由于幻覺可能由多個來源引起,可能的用途是遺忘作爲常見幻覺或誤解來源的事實上不正确的數據。
LLM也被認爲會産生偏見的決策和輸出。
-
在視覺領域,遺忘已被證明是減少歧視以實現公平決策的有效工具。
-
在語言領域,遺忘已被應用于減輕性别-職業偏見(Yu et al., 2023)和許多其他公平問題。
-
然而,更多的機會存在,例如遺忘訓練數據中的刻闆印象。
LLM也被認爲容易受到越獄攻擊(jailbreaking attacks),即,故意設計的提示導緻LLM生成不希望的輸出)以及投毒/後門攻擊。鑒于遺忘在其他領域作爲對抗攻擊防禦的成功,遺忘可以成爲這兩種類型攻擊的自然解決方案。
總結與未來展望
1. LLM遺忘的挑戰與機遇
LLM遺忘面臨的挑戰包括确保遺忘目标的普遍性、适應各種模型設置(包括白盒和黑盒場景)以及考慮遺忘方法的具體性。LLM遺忘應該專注于有效地移除數據影響和特定模型能力,以便在各種評估方法中,特别是在對抗性環境中驗證遺忘的真實性。LLM遺忘還應該精确地定義遺忘範圍,同時确保在這個遺忘範圍之外保持一般語言建模性能。
通過審視當前的技術水平,我們獲得了LLM遺忘未來發展的洞見。例如,基于定位的遺忘顯示出效率和效果的雙重優勢。有效的遺忘需要仔細考慮數據-模型影響和對手。盡管LLM遺忘和模型編輯在其制定和方法設計上存在相似之處,但它們在目标和方法上有所不同。此外,從LLM遺忘的研究中獲得的洞見可能會催生其他類型的基礎模型(例如,大型視覺-語言模型)的技術進步。
2. 從遺忘到編輯:LLM的新方向
LLM遺忘與模型編輯緊密相關,模型編輯關注的是局部改變預訓練模型的行爲,以引入新知識或糾正不希望的行爲。遺忘的目标有時與編輯的目标一緻,尤其是當編輯被引入以擦除信息時。像遺忘範圍一樣,編輯範圍也是确保在定義範圍之外不影響模型生成能力的關鍵。遺忘和模型編輯都可以使用“先定位,然後編輯/遺忘”的原則來處理。
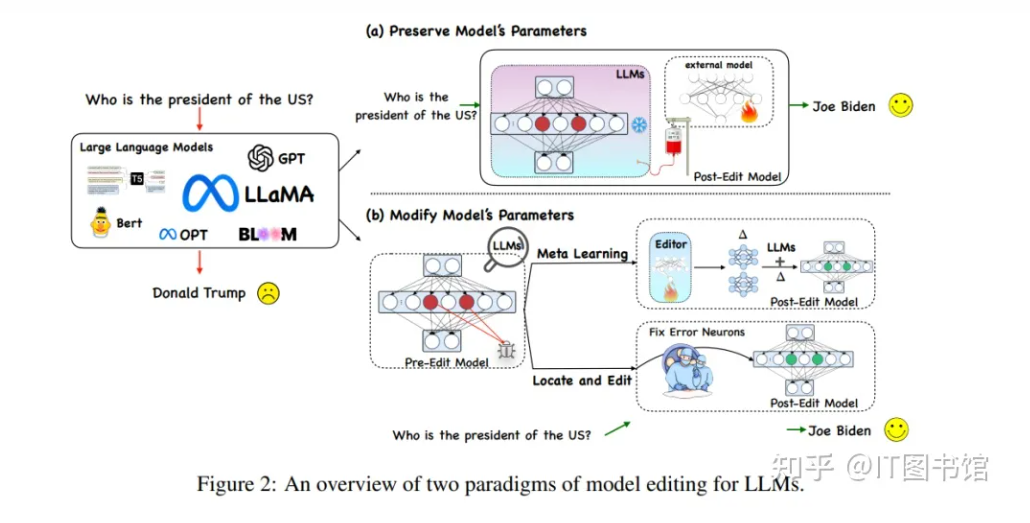
盡管存在上述聯系,LLM遺忘和編輯之間有明顯的區别。
-
首先,與編輯響應相比,遺忘響應有時是未知的。不正确或不當的遺忘響應的特定性可能被視爲遺忘後的LLM幻覺。
-
其次,盡管遺忘和模型編輯可能共享一些共同的算法基礎,但前者不創建新的答案映射。相反,其核心目标是全面消除歸因于特定知識或概念的影響。
-
第三,我們可以從“工作記憶”的角度區分模型編輯和遺忘。已知在LLM中,工作記憶是通過神經元激活而不是基于權重的長期記憶來維持的。
因此,現有的基于記憶的模型編輯技術專注于更新短期工作記憶,而不是改變模型權重中封裝的長期記憶。然而,研究者們認爲遺忘需要更機械化的方法來促進對預訓練LLM的“深層”修改。
論文的更廣泛影響
1. 倫理與社會影響的讨論
在探讨大語言模型(LLMs)的機器遺忘(MU)時,我們不得不面對一系列倫理和社會問題。這些模型因其能夠生成與人類創作内容極爲相似的文本而備受關注,但它們對大量語料的記憶能力也可能導緻倫理和安全問題。
例如,社會偏見、刻闆印象、敏感或非法内容的生成、以及可能被用于發展網絡攻擊或生物武器的風險。這些問題強調了根據不同安全背景,靈活且高效地調整預訓練LLMs的必要性,以滿足用戶和行業的特定需求。
機器遺忘作爲一種替代方案,旨在從預訓練模型中移除不良數據的影響及相關模型能力。例如,爲了防止生成《哈利·波特》系列的版權材料,研究人員使用了機器遺忘策略。這些讨論不僅關系到技術的發展,也觸及到如何在不損害模型整體知識生成能力的同時,确保數據隐私和版權的保護。
2. 機器遺忘在實際場景中的應用必要性
機器遺忘在實際應用中的必要性體現在多個方面。
-
首先,它有助于避免敏感或非法信息的傳播,并且在不影響與遺忘目标無關信息的前提下,維護模型的完整性。
-
其次,考慮到LLMs的昂貴和漫長的訓練周期,重新訓練模型以消除不良數據效應通常是不切實際的。
因此,機器遺忘成爲了一個可行的選擇。
在實際應用中,機器遺忘可以用于版權和隐私保護,例如避免生成版權受保護的内容,或防止洩露用戶的個人識别信息。此外,機器遺忘還可以用于社會技術性危害的減少,比如通過遺忘有害行爲來使LLMs與人類指令和價值觀保持一緻,或者減少由于錯誤信息源導緻的幻覺現象。
公衆号「夕小瑤科技說」後台回複“機器遺忘”獲取論文pdf。


-
-
-
-
-
-
-








