

前言
最近把李沐大神《动手学深度学习v2》的目标检测部分学完了,就想找一个项目练练手,学以致用嘛,觉着人脸口罩佩戴检测比较符合当下时代背景,所以就选择了这个项目,也是前几天刚刚完成的,写下这篇博客记录一下具体过程,废话不多说,现在开始吧。
文章目录
- 前言
- 一、数据集获取与介绍
- 二、数据预处理
- 三、下载YOLOv5代码
- 四、配置所需环境
- 五、模型训练
- 六、模型使用
- 总结
一、数据集获取与介绍
获取人脸口罩的数据集有两种方式:
第一种就是使用网络上现有的数据集
第二种就是使用labelimg工具创建自己的数据集,可以参考一下这位博主的文章:labelImg 使用教程 图像标定工具
注意!:无论哪种方式,都一定要弄清楚2点:
1、数据集里的类别总数量
2、每个类别的名称(名称用xml文件中标注好的就行,xml文件下面有介绍)
举例:这里是Kaggle上的一个人脸口罩数据集(链接): Face Mask Detection 数据集中包含了853张图片,类别有 3 类:
with_mask、without_mask 和 mask_weared_incorrect
打开上面提到的kaggle的数据集文件我们会发现里面有两个子目录:
其中images目录如下:
annotations目录如下,与图片同名的xml文件就是对应该图片的标注信息文件
打开第一个xml文件可以看到以下信息,without_mask、with_mask就是我们的标签名,都是xml文件里现成的。

二、数据预处理
虽然上面我们下载了数据集,但不能直接用,因为YOLO所需的格式为txt,而且YOLO对数据集存放路径有严格的规定,如下:
dataset ├─ images │ ├─ test # 下面放测试集图片(可选) │ ├─ train # 下面放训练集图片 │ └─ val # 下面放验证集图片 └─ labels ├─ test # 下面放测试集标签(可选) ├─ train # 下面放训练集标签 ├─ val # 下面放验证集标签数据集根目录下有images和labels两个子目录,它们两个都包含train和val两个同名目录,
其中images中的train里全是图片,而labels中的train则对应着images中train的标注信息。
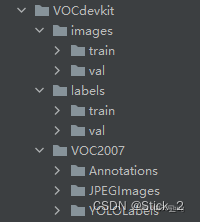
关于将xml格式转化为txt格式以及训练集和验证集划分可以参考这位博主的文章:目标检测—数据集格式转化及训练集和验证集划分 按照这篇文章一步步来之后,得到我们的数据集 VOCdevkit(dataset) 文件目录结构如下:
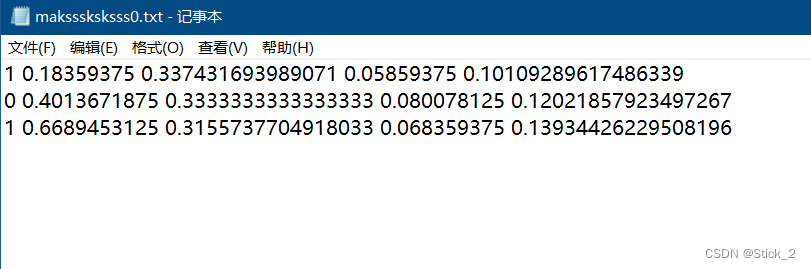
记得查看label里的txt文件是否为空,如果为空,则查看你的标签名是否写错了,如果txt里内容类似如下就说明数据集预处理成功了!其中每一行的5个参数从左到右分别是:
class、x_center、y_center、width、height
类号是从0开始的,后面接着的四个小数是边界框信息,小数是因为YOLO把坐标都划定在0-1范围内。
三、下载YOLOv5代码
这里给出2种获取方式。
(1)YOLOv5原作者的仓库地址在这:yolov5 (推荐大家去GitHub上阅读原作者所写的文档,有助于我们更好的理解)
(2)然后原作者的代码我也上传到百度网盘了:
链接:https://pan.baidu.com/s/1u01gf8Ck6seeRylJys9X9g
提取码:9tk9
四、配置所需环境
上面都准备完之后我们来开始创建我们所需要的环境,这里推荐大家一个免费GPU使用平台,中国移动的九天·毕昇平台(链接):九天 · 毕昇 一站式人工智能学习和实战平台 他们的GPU是Tesla v100,大家注册成功后创建环境流程步骤如下:
第一步:点击科研
第二步:点击模型训练
第三步:点击新建实例
第四步:填写实例名称,如:基于YOLOv5的人脸口罩佩戴检测
第五步:选择资源套餐
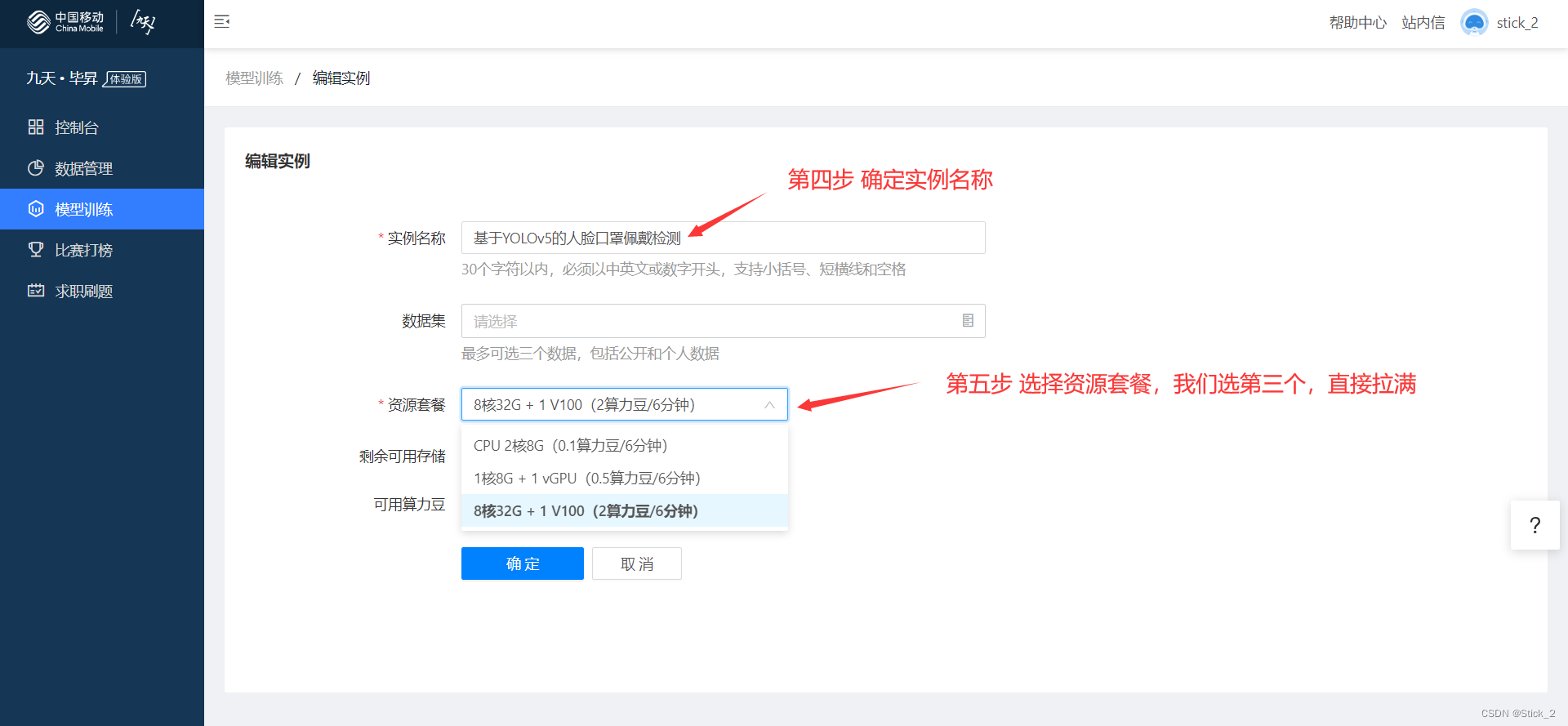
第六步:点击确定完成创建
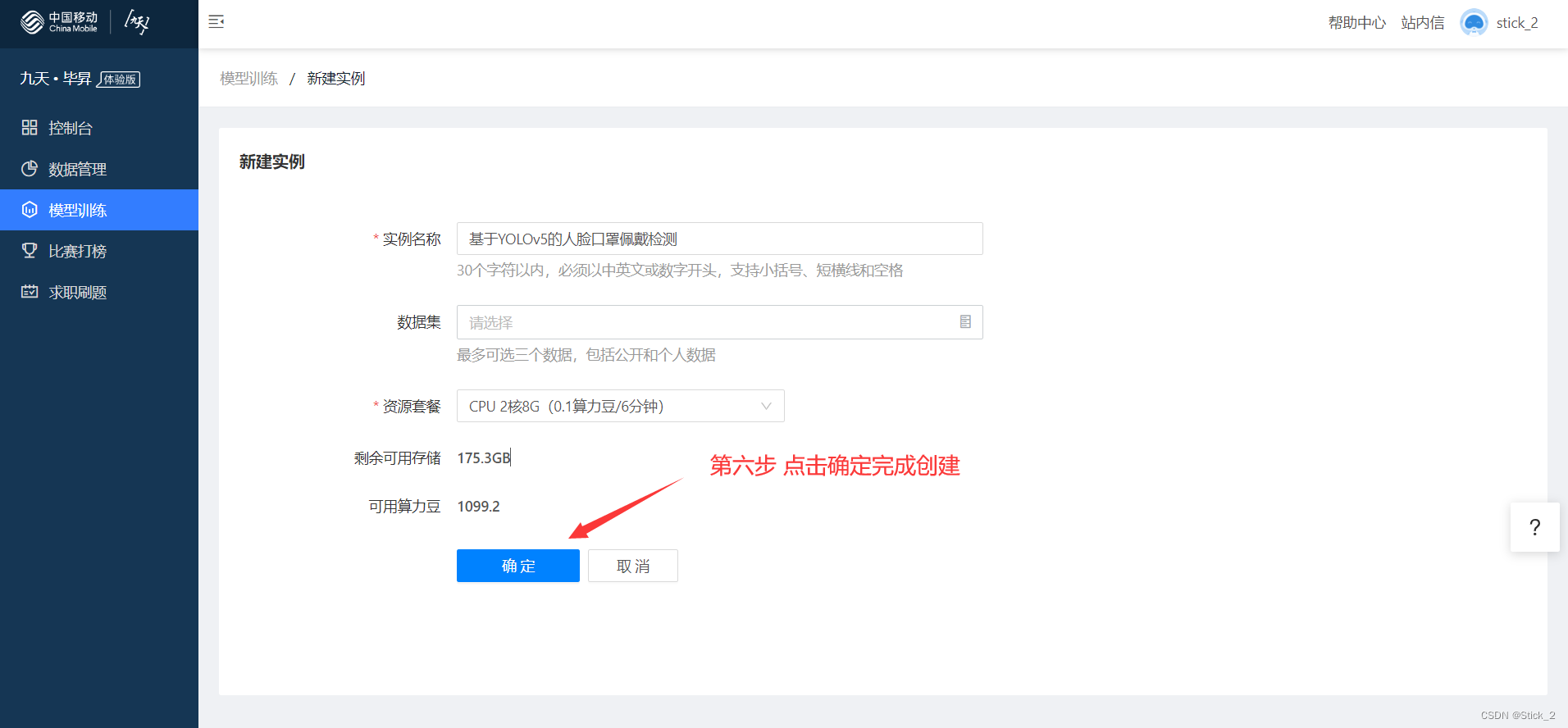
第七步:点击Jupyter进入工作环境
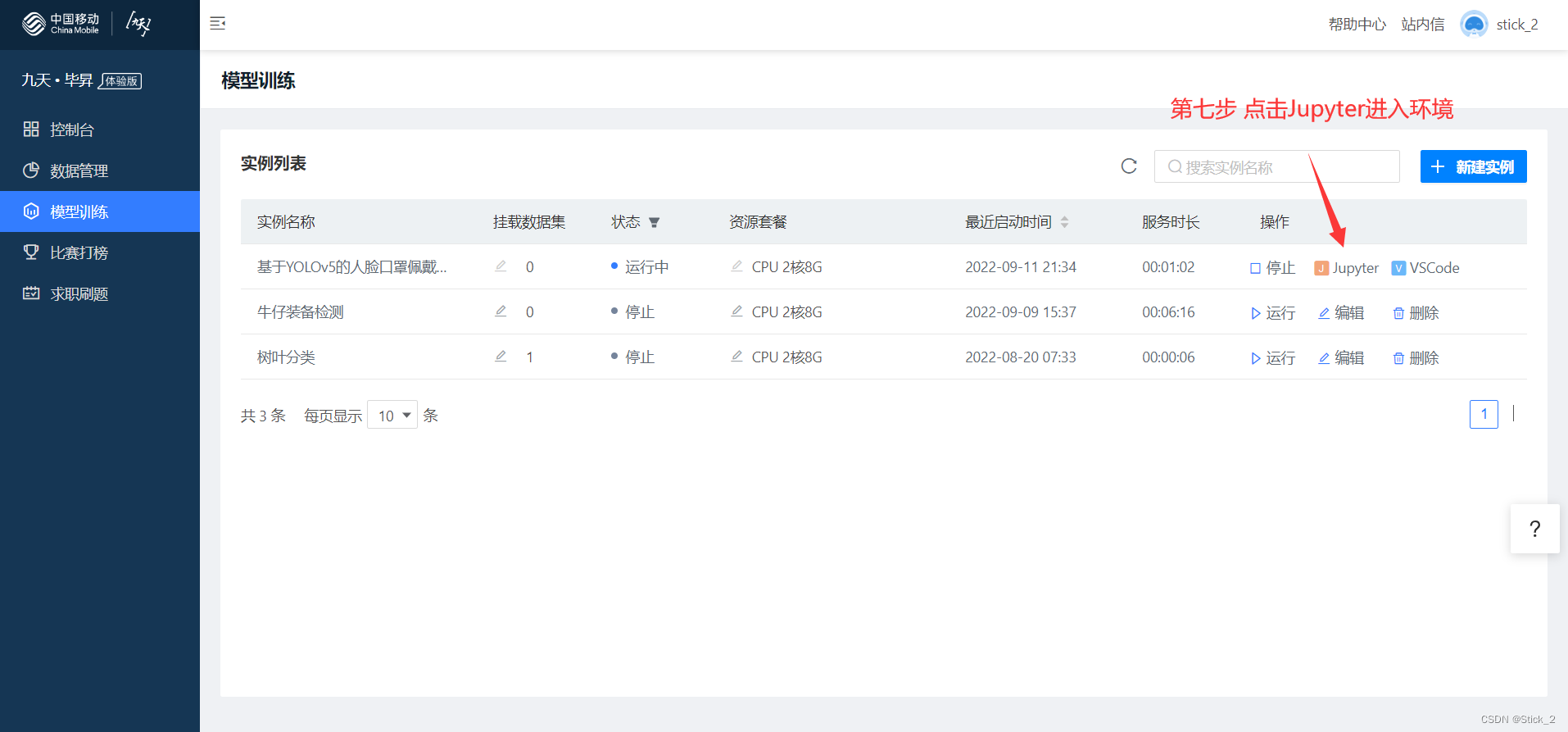
左边红框部分就是我们的根目录,直接把要上传的文件拖动到红框内就可以完成上传
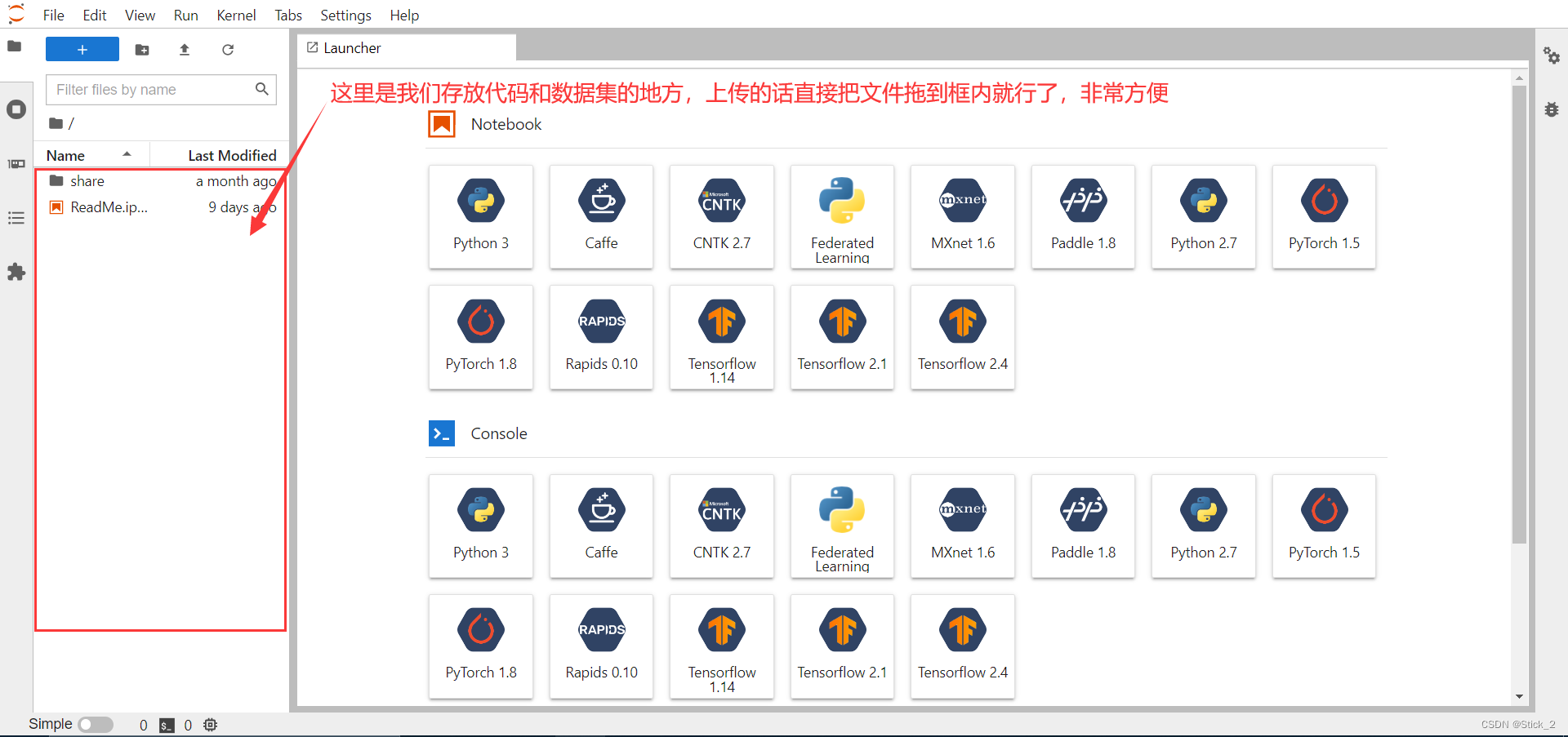
建议将数据集和代码都压缩后再上传。
注意!!!:数据集不能放在yolo代码的目录下,他是跟yolo同等级的
举例:yolov5-master 代码的路径如果是:/root/yolov5-master
那数据集 VOCdevkit 的路径就应该是:/root/VOCdevkit
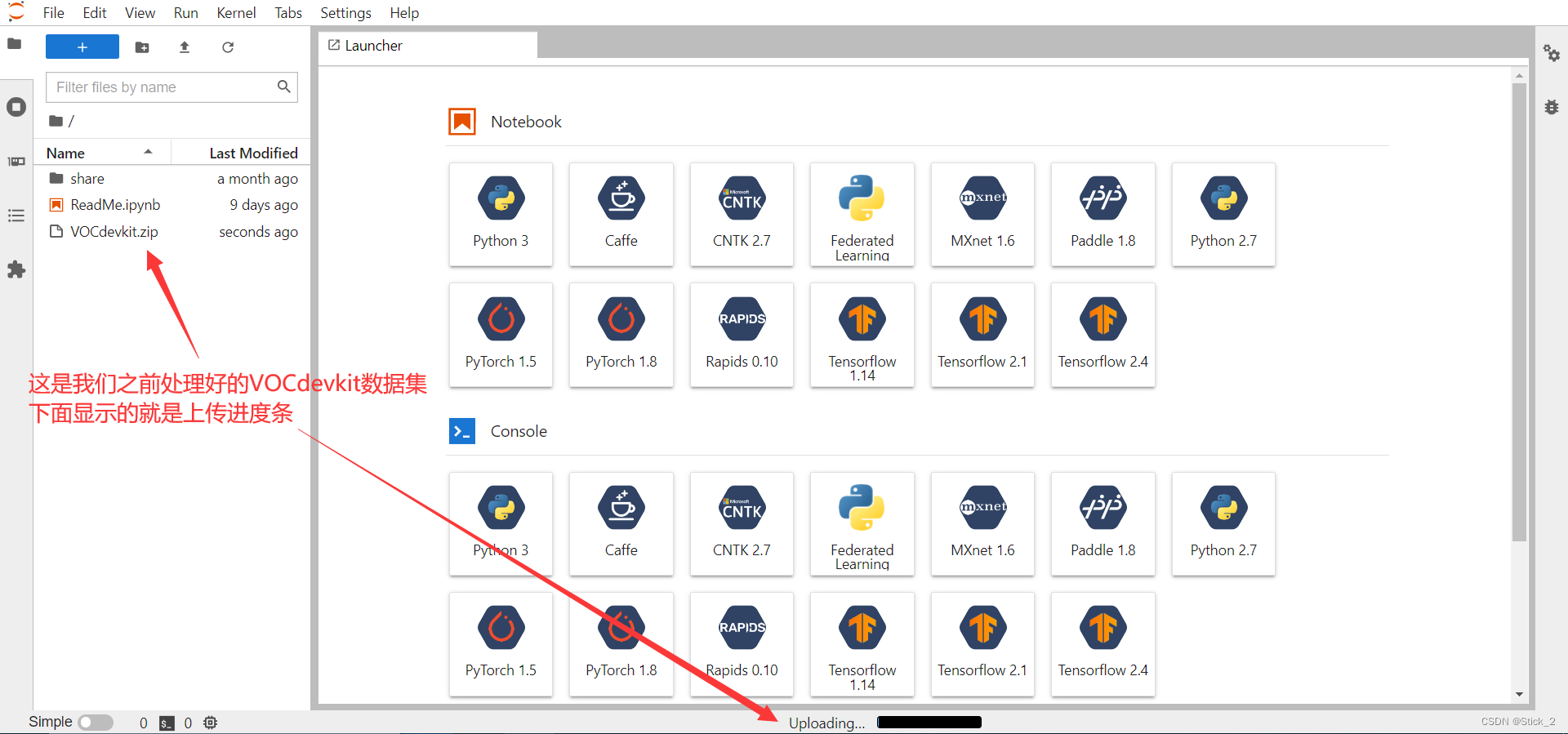
在将yolov5代码和数据集都上传之后,将鼠标往下滑
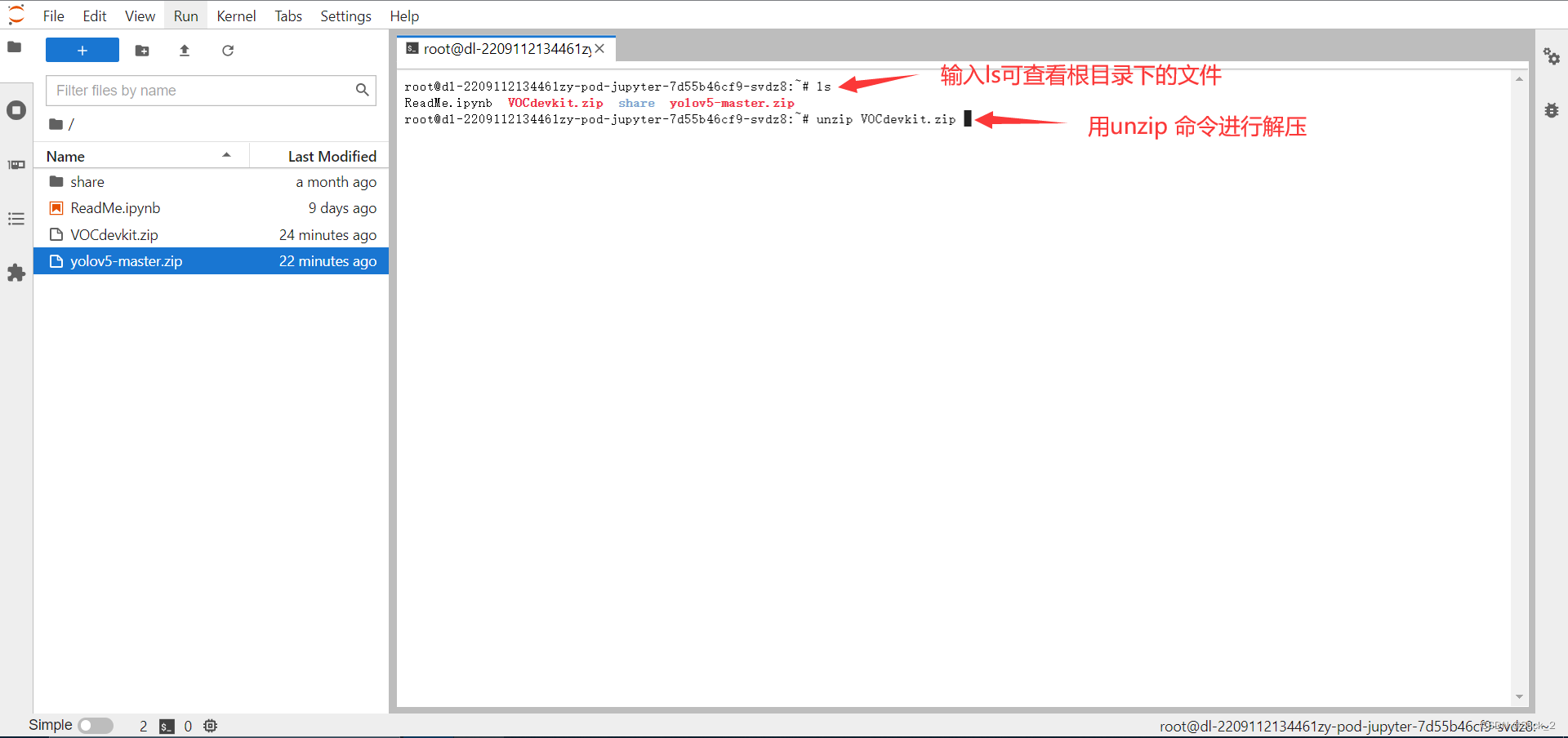
点击Terminal进入终端

使用unzip解压数据集和代码
解压后如下
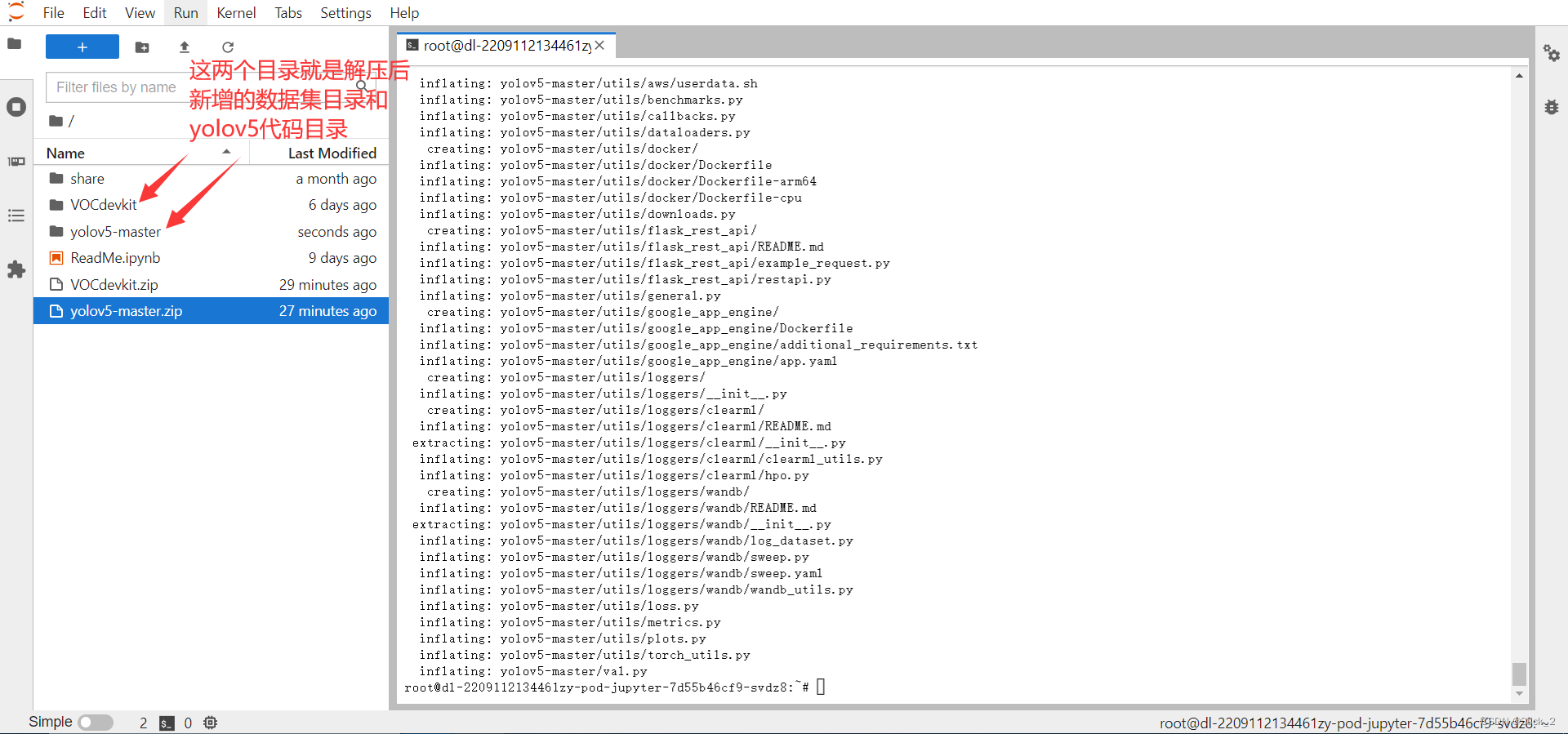
接着我们要创建python的虚拟环境,因为YOLOv5官方文档说python版本要大于等于3.7,我们直接创建python3.7的环境即可。
在终端输入:conda create -n yolo_py37 python=3.7 yolo_py37 就是我们环境的名称,你也可以自己定义。
接着等待下载即可。
下载完成之后在终端输入:conda info --env 查看已有的环境
然后再输入:conda activate yolo_py37 进入到我们刚才创建好的虚拟环境

输入:cd yolov5-master 进入到 yolov5 代码目录
输入:ls 查看yolov5-master目录下所有文件

其中 requirements.txt 文件就是我们要安装的包,
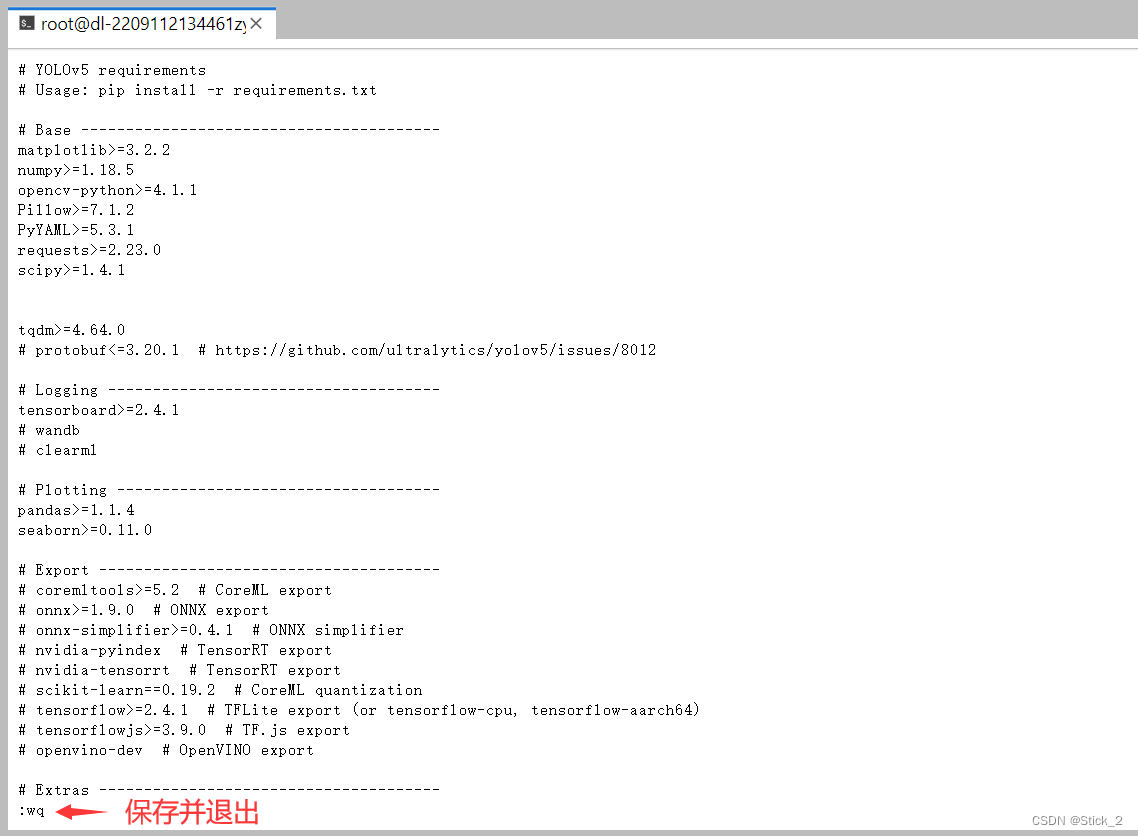
接着输入:vim requirements.txt 查看我们要装的包

进入requirements.txt这里之后,我们可以看到torch和torchvision两个包,但是它们两个都是cpu版本,所以我们先把这两行删除:
vim编辑器中键盘按下i即可进入编辑模式,然后用键盘上下左右键移动到目标位置进行删除
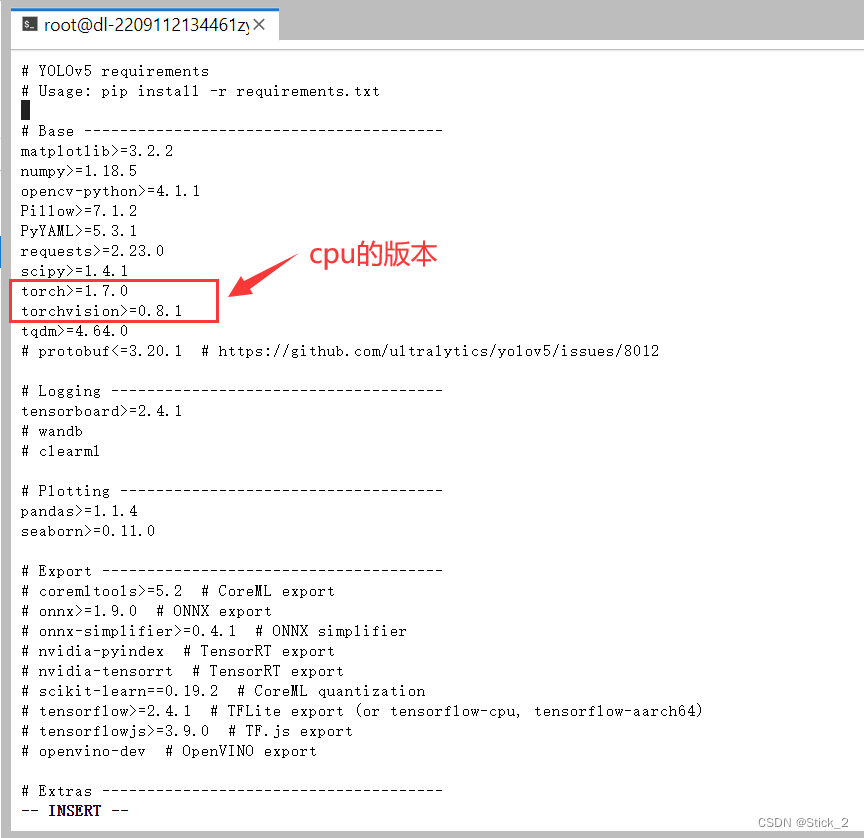
删除之后按ESC键后输入:wq,再敲下回车键,将文件保存并退出。
修改好之后在终端输入:pip install -r requirements.txt 来安装代码所需要的包
然后就是等待下载…

下面我们来装pytorch的GPU版本
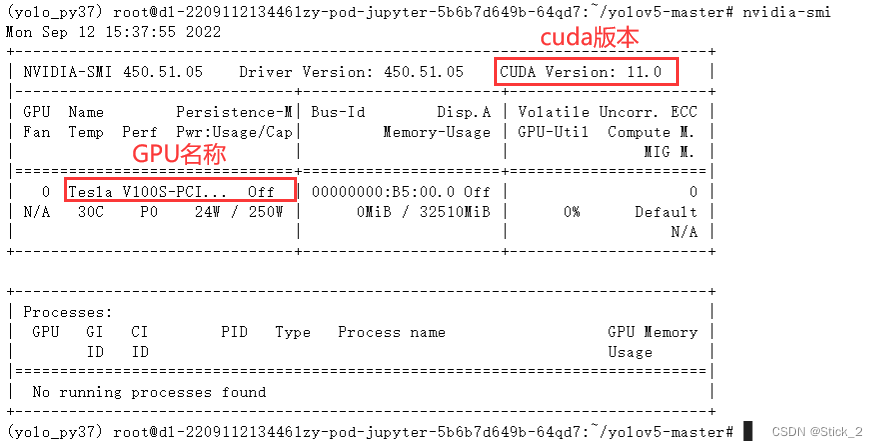
安装之前我们先要查看GPU的cuda版本,在终端输入:nvidia-smi可查看GPU信息,可以看到我这里的cuda版本是11.0。
然后我们去pytorch官网(链接):Pytorch官网
第一步:点击Install
第二步:根据我们的开发环境选择pytroch的安装命令行,不同的选项pip命令可能有所不同,根据九天·毕昇的开发环境选项设置如下:
PyTorch Build :点Stable
Your OS:点Linux
Package:点Pip
Language:点Python
Compute Platform:点CUDA11.3(我cuda版本为11.0,这里点11版本里与其最接近的)

选项设置好后,会出现我们的pip命令行如下:
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
第三步:将这段命令行复制后在终端输入:
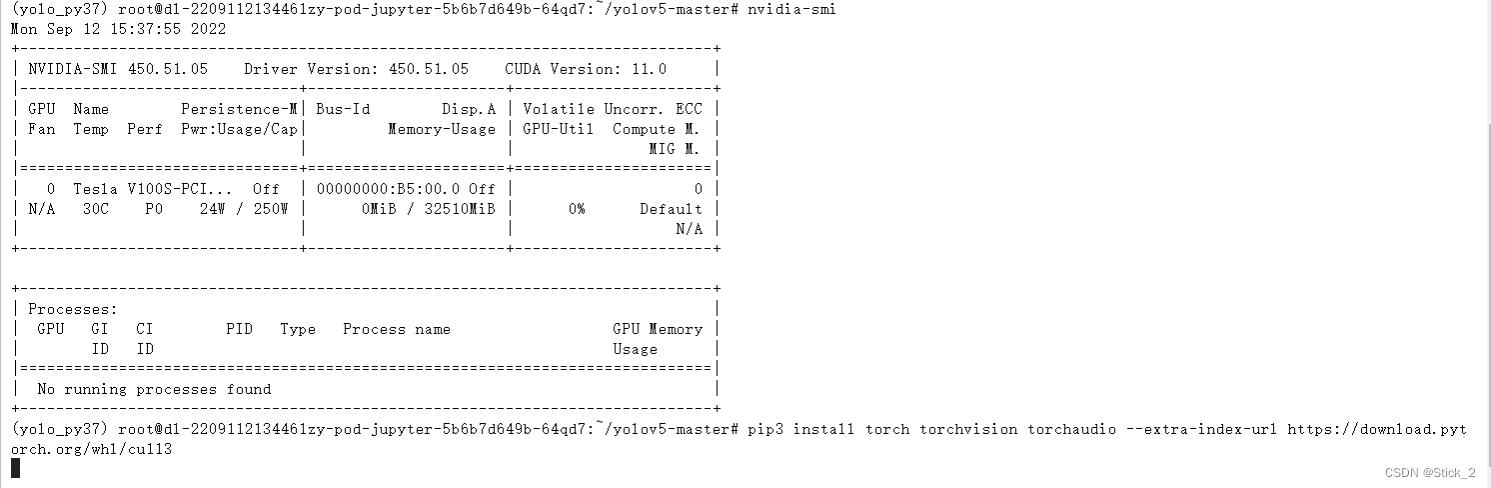
然后开始等待GPU版本的pytorch下载…
出现下面这段文字就说明安装成功了

接着我们来验证pytorch是否可用
第一步:点击+号
第二步:点击Python 3创建python文件

第三步:输入如下代码点击运行
import torch torch.cuda.is_available()
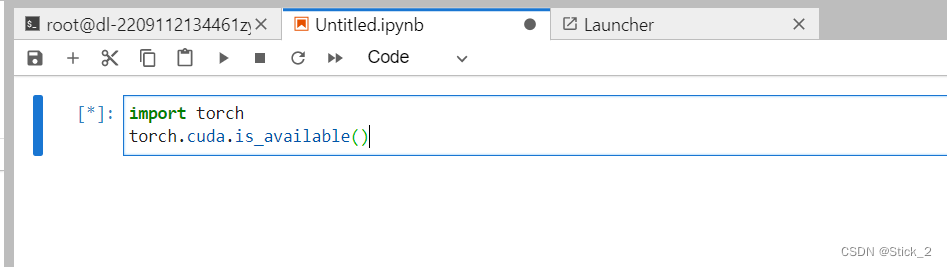
运行后,结果出现True则说明安装成功了。

到这里我们的环境就配置成功了!
五、模型训练
模型训练前我们需要做两件事
第一:配置数据文件。
在终端输入:vim data.yaml
把下面的内容复制到data.yaml文件内。
train: /root/VOCdevkit/images/train val: /root/VOCdevkit/images/val # number of classes nc: 3 # class names names: ["with_mask", "without_mask", "mask_weared_incorrect"]
这里的nc和names都是根据数据集内容来填写的,不同的数据集内容不一样,这也是为什么之前说要弄清楚数据集中类别数量和所有类别名称这两点。
第二:配置模型文件。
先cd到models目录下
再输入:vim yolov5s.yaml(这里我们选择了常用的yolov5s模型而不是yolov5n、yolov5m或者其它,是因为要同时考虑速度与精度,模型小,对应的推理速度快,目标检测时的帧率也会快,目标检测对帧率有要求的)
将yolov5s.yaml文件中的80改成3即可,这里的nc由我们的数据集而定,我们标签总数为3类,所以改成3就行了。记得保存再退出。

接着我们开始正式训练了!
先cd到yolo代码的根目录下,再在终端输入如下命令:
python train.py --weight yolov5s.pt --cfg models/yolov5s.yaml --data data.yaml --epochs 300 --batch-size 4 --device 0
如图:

然后开始漫长的等待…
运行后会自动print如下信息,这就是我们的模型每一层的信息
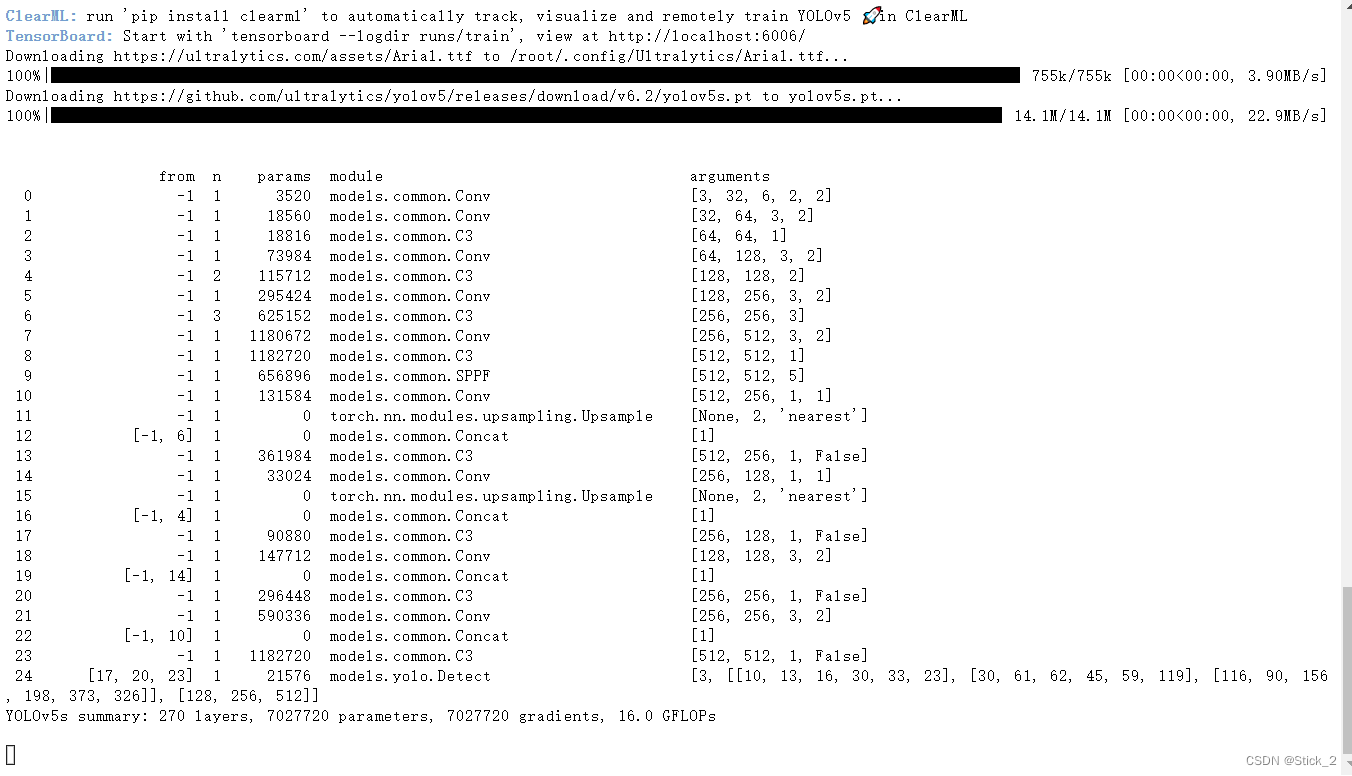
接着会print模型训练结果保存位置,然后模型就开始训练了。
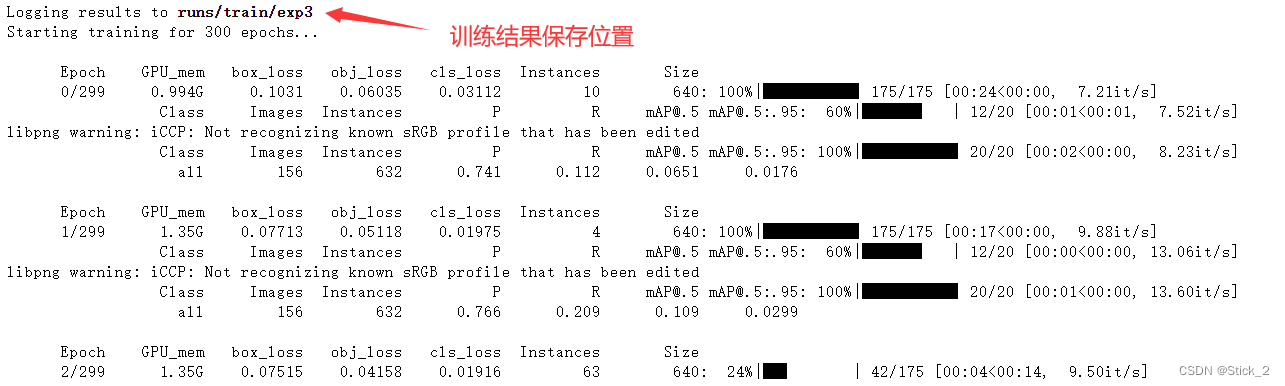
训练完成之后显示如下:

接着我们可以在 runs/train/exp3 目录下查看训练结果
路径: runs/train/exp3 下的 PR_curve.png 是关于准确率和召回率的曲线
准确率和召回率曲线如下:
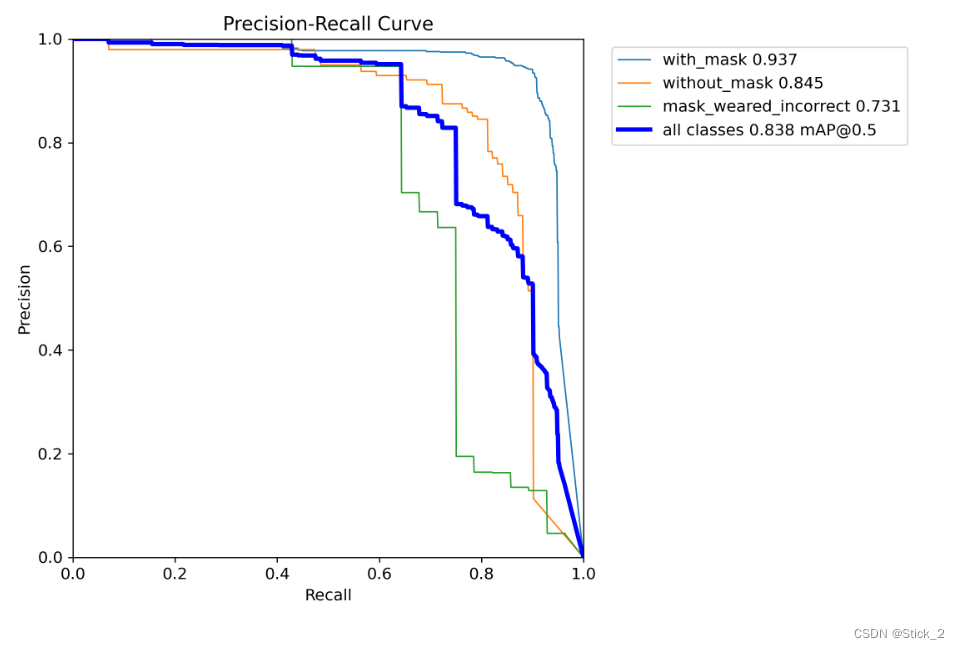
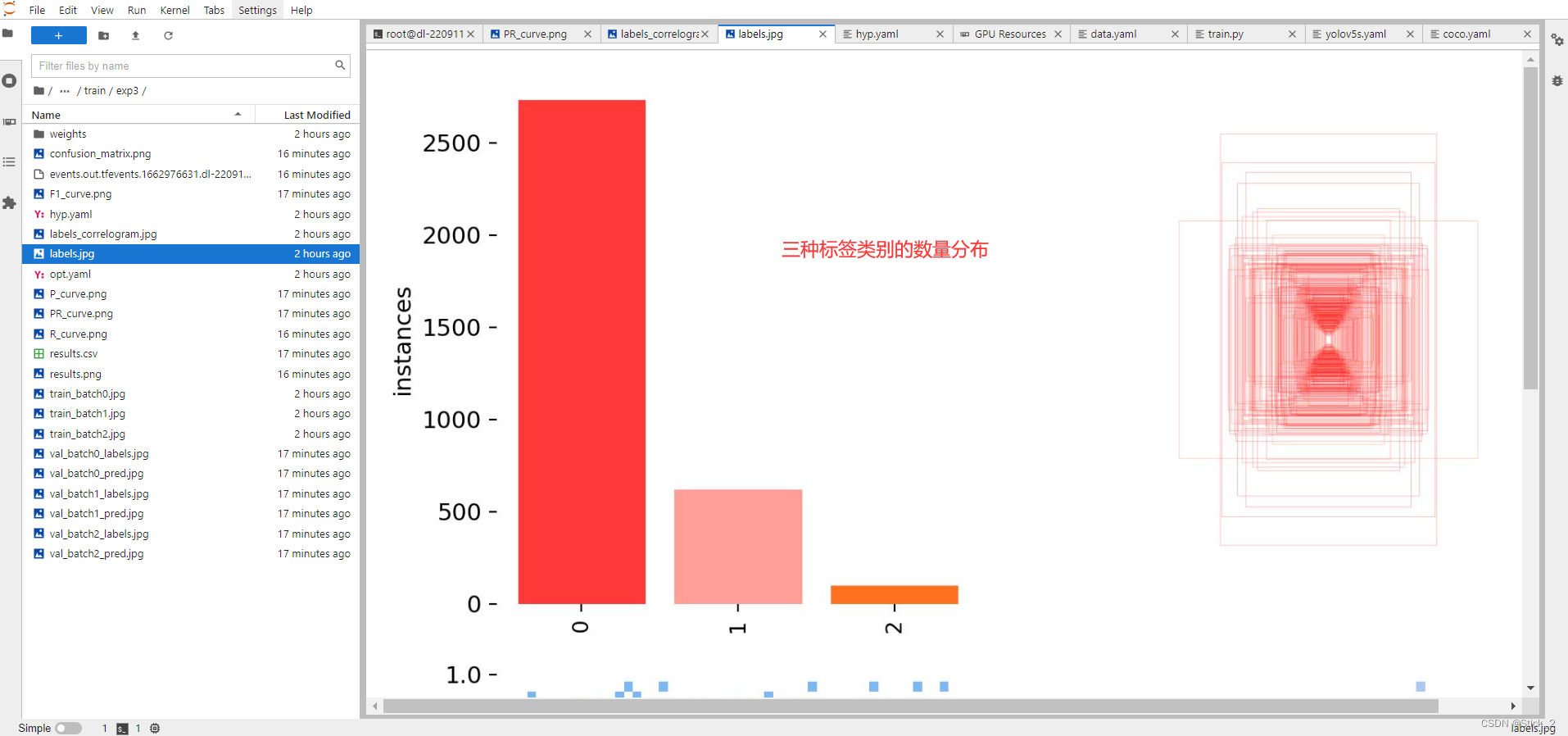
由上图我们可以看出所有三种类别的mAP为0.838,其中类别 with_mask 训练效果最好,without_mask 次之,mask_weared_incorrect 最差,其实yolov5已经做了图像增广了,但第三类也只有0.7几,没办法第三类标签数据实在太少了,打开labels.jpg可见数据中三类标签的数量分布如下,第三类少得可怜…
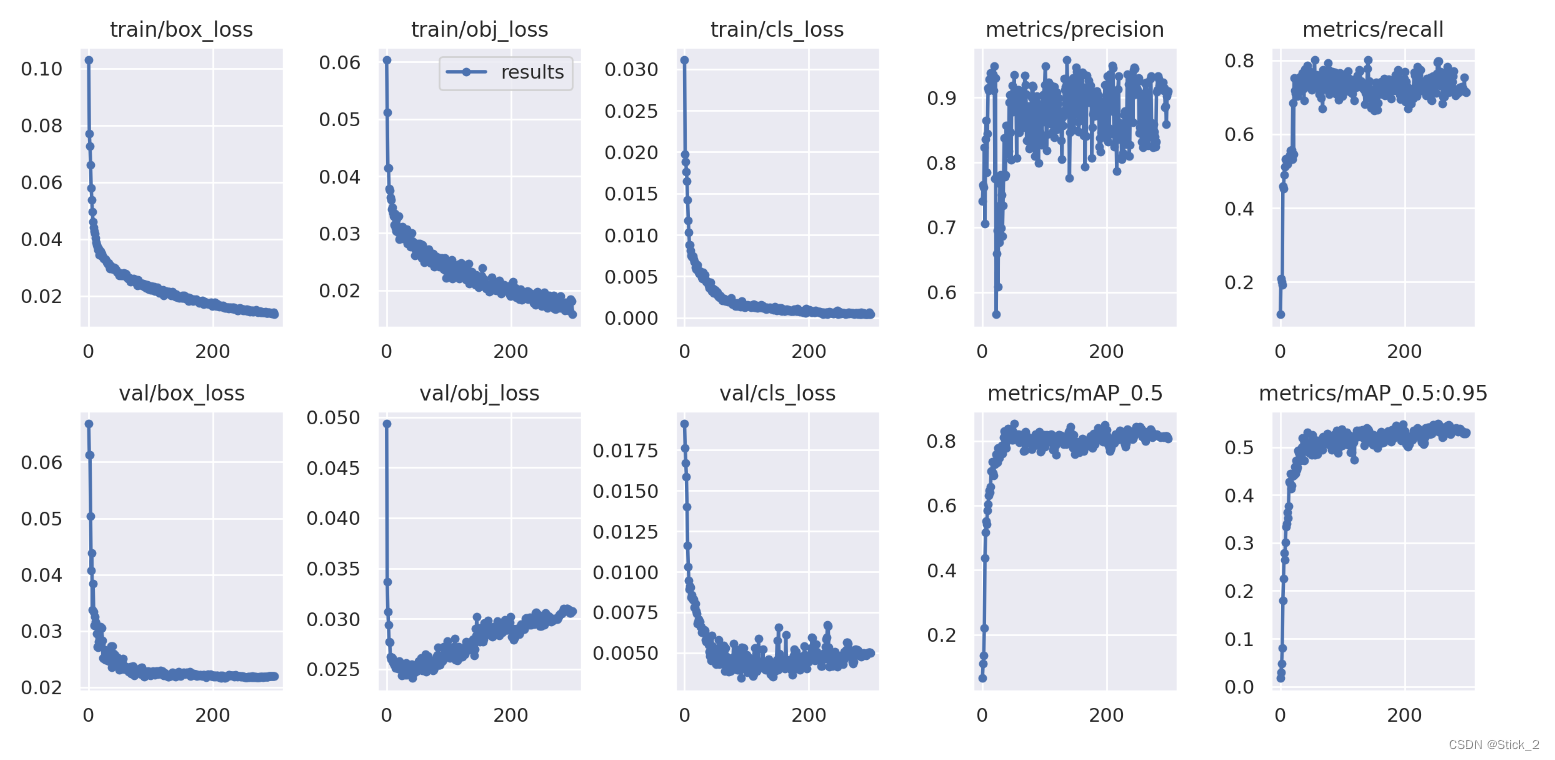
然后打开results.png,可见300个epoch的训练过程曲线图
路径:runs/train/exp3/weights/best.pt 存储的就是我们训练好的模型参数文件了
鼠标右键,然后点击Download可以将训练好的模型参数从服务器下载到我们自己电脑上,为后面模型在本地电脑上使用做准备。
六、模型使用
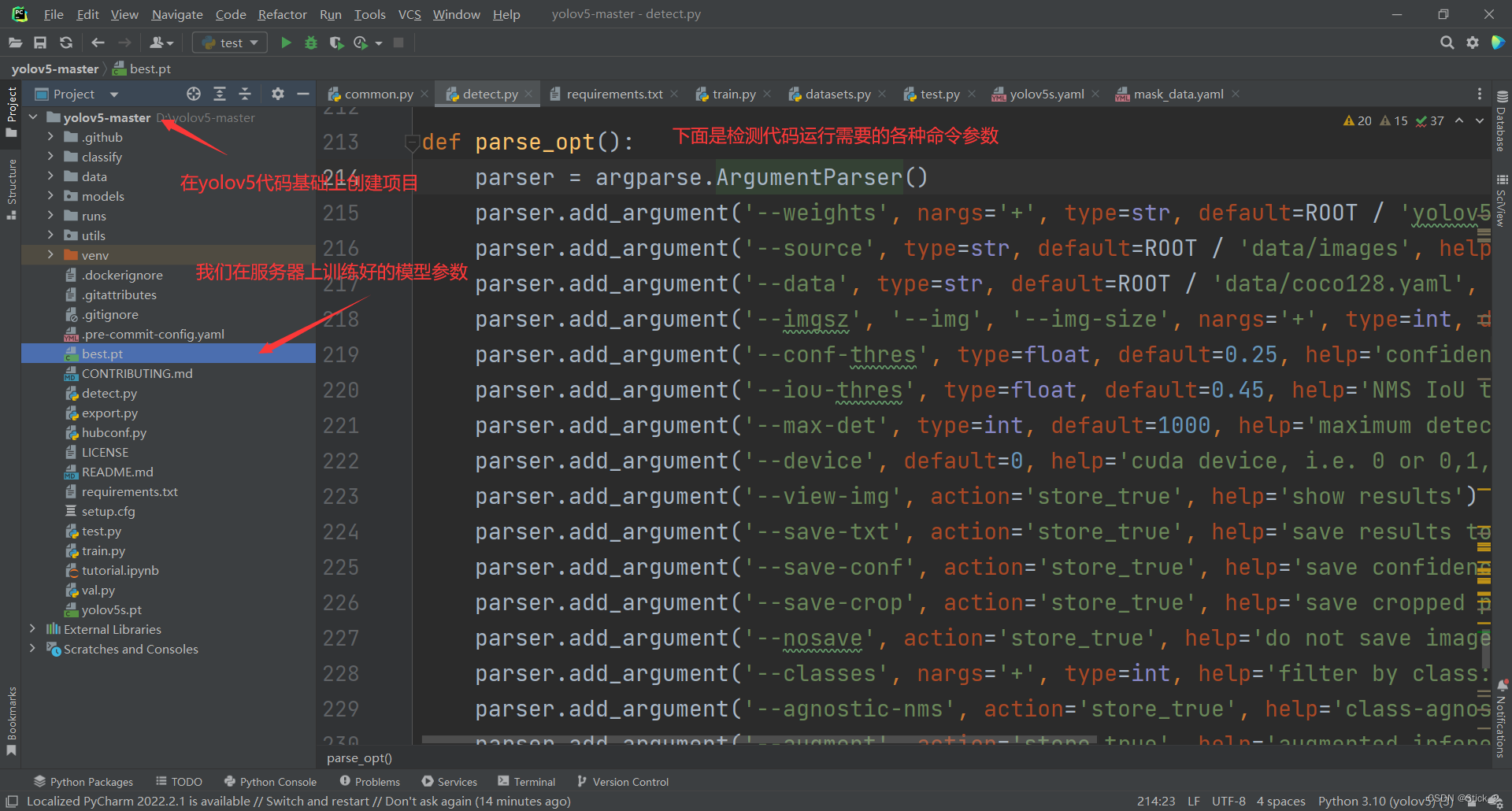
在自己电脑使用的话,我比较习惯用Pycharm,在pycharm配置python3.7以上环境,并且安装所需的包之后,把在服务器上训练好的best.pt复制到代码根目录下,之后打开detect.py,在213行之后是命令行的一些参数,比如:
–weights :选择模型参数具体路径
–source :选择检测方式,可以是图片路径,也可以是调用摄像头
–device :选择运行在cpu还是在gpu上。
等等…
举个使用的例子:
在终端输入如下命令
python detect.py --weights best.pt --source 0 --device 0
其中:
–weights best.pt: 就是之前训练好的模型参数文件,因为我放在yolo项目的根目录下,所以路径直接写文件名就行,
–source 0 :0表示数据来源于摄像头
–device 0:0表示在gpu上运行
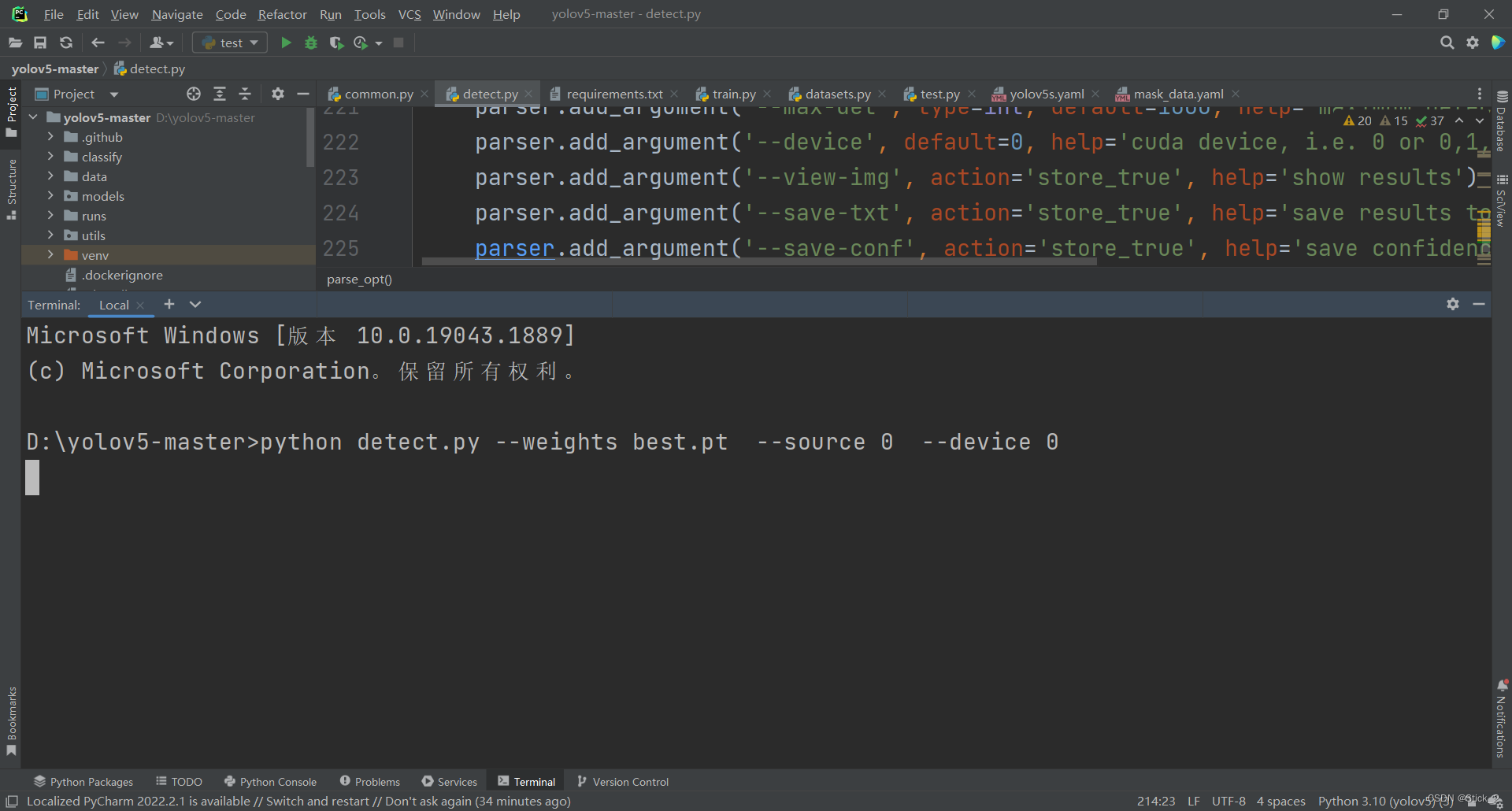
等待启动之后效果如下:
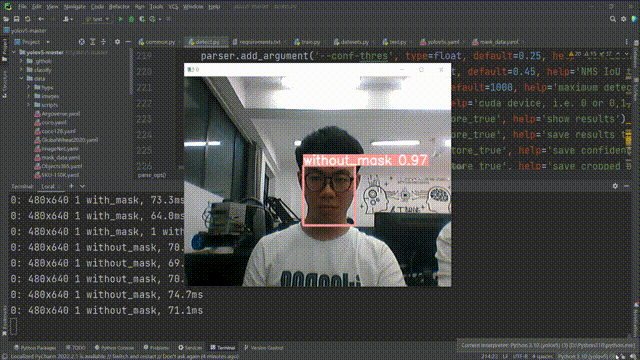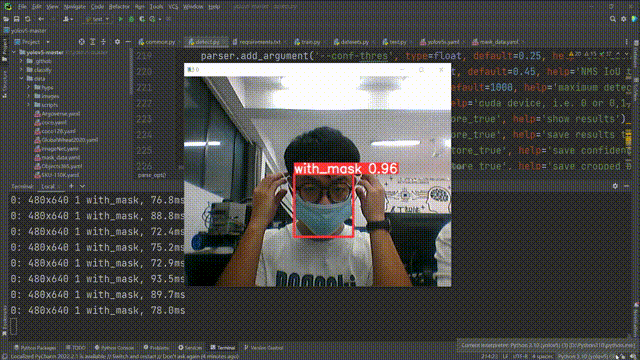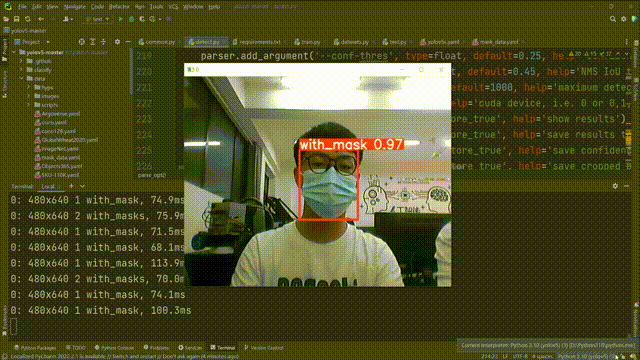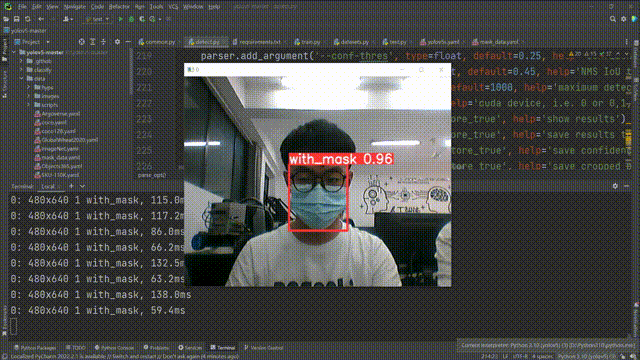
到这里我们的项目就算全部完成了。
总结
YOLOv5是很强大的one-stage目标检测模型,在使用它针对我们特定任务进行训练时,只需要做好下面4件事:
1:数据格式。标签labels需要txt格式
2:数据集结构。结构如下
dataset # (数据集根目录) ├─ images #(一级子目录) │ ├─ test # 下面放测试集图片(二级子目录,下同) │ ├─ train # 下面放训练集图片 │ └─ val # 下面放验证集图片 └─ labels #(一级子目录) ├─ test # 下面放测试集标签(二级子目录,下同) ├─ train # 下面放训练集标签 ├─ val # 下面放验证集标签3:配置数据文件如上文的data.yaml
4:配置模型文件如上文的yolov5s.yaml
之后便可以开始训练、测试、部署了,后面有时间我会试着在手机上完成部署。
最后觉得有帮助可以给笔者点赞、关注,谢谢!







