tranformers中的模型在使用之前需要进行分词和编码,每个模型都会自带分词器(tokenizer),熟悉分词器的使用将会提高模型构建的效率。
- string → tokens tokenize(text: str, **kwargs)
- tokens → string convert_tokens_to_string(tokens: List[token])
- tokens → ids convert_tokens_to_ids(tokens: List[token])
- ids → tokens convert_ids_to_tokens(ids: int or List[int], skip_special_tokens=False)
- string → ids encode(text, text_pair=None, add_special_tokens=True, padding=False, truncation=False, max_length=None, return_tensors=None)
text:str, List[str], List[int].
text_pair: str, List[str], List[int]
add_special_tokens: bool.是否添加特殊token([CLS]、[SEP])
max_length: int, None.
padding: bool. padding取True or 'longest"时, padding至batch中最长的句子长度; padding取’max_length’时, padding至max_length; padding取False or ‘do_not_pad’ (default), 不padding.
truncation: bool, str。只对输入为 sequence pair 有效。truncation取True or 'longest_first’时, token by token 的截断,哪一句长,截断哪一句的最后一个 token,相同长度就第二句。截至总token数等于 max_length; truncation取’only_first’时只截第一句,至总token数等于 max_length; truncation取’only_second’时只截第二句,至总token数等于 max_length;truncation取False or ‘do_not_truncate’ (default)。
return_tensors: str, None。‘tf’, ‘pt’ or ‘np’ 分布表示不同的tensor type.
- ids → string decode(token_ids: List[int], skip_special_tokens=False, clean_up_tokenization_spaces=True)
- encode_plus:
encode_plus(text, text_pair=None, add_special_tokens=True, padding=False, truncation=False, max_length=None, stride=0, is_pretokenized=False, pad_to_multiple_of=None, return_tensors=None, return_token_type_ids=None, return_attention_mask=None, return_overflowing_tokens=False, return_special_tokens_mask=False, return_offsets_mapping=False, return_length=False)
- batch_encode_plus:
输入为 encode 输入的 batch,其它参数相同。注意,plus 是返回一个字典。
- batch_decode:
输入是batch.
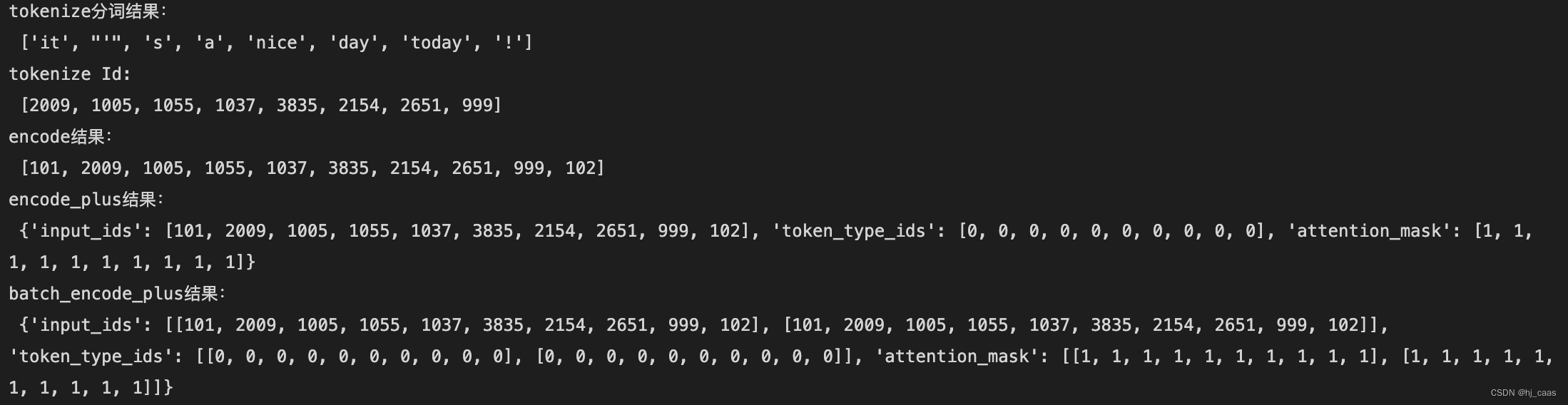
#这里以bert模型为例,使用上述提到的函数 from transformers import BertTokenizer tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') text = "It's a nice day today!" #tokenize,#仅用于分词 seg_words = tokenizer.tokenize(text) print("tokenize分词结果:\n",seg_words) #convert_tokens_to_ids,将token转化成id,在分词之后。 #convert_ids_to_tokens,将id转化成token,通常用于模型预测出结果,查看时使用。 seg_word_id = tokenizer.convert_tokens_to_ids(seg_words) print("tokenize Id:\n",seg_word_id) #encode,进行分词和token转换,encode=tokenize+convert_tokens_to_ids encode_text = tokenizer.encode(text) print("encode结果:\n",encode_text) #encode_plus,在encode的基础之上生成input_ids、token_type_ids、attention_mask encode_plus_text = tokenizer.encode_plus(text) print("encode_plus结果:\n",encode_plus_text) #batch_encode_plus,在encode_plus的基础之上,能够批量梳理文本。 batch_encode_plus_text = tokenizer.batch_encode_plus([text,text]) print("batch_encode_plus结果:\n",batch_encode_plus_text)