

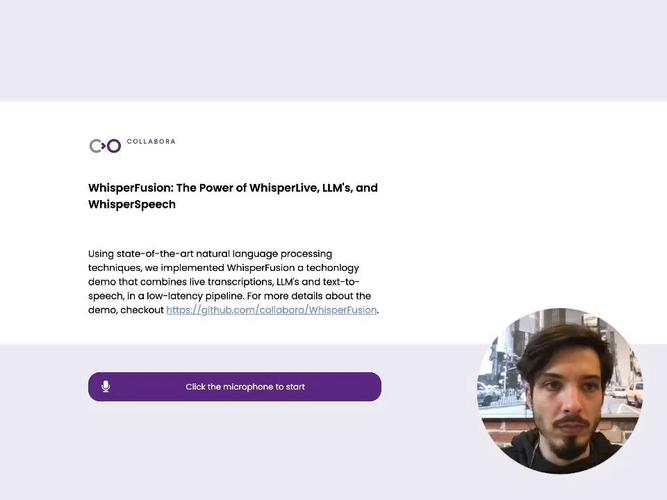
WhisperFusion 基于 WhisperLive 和 WhisperSpeech 的功能而构建,在实时语音到文本管道之上集成了大型语言模型 Mistral (LLM)。
(图片来源网络,侵删)
LLM 和 Whisper 都经过优化,可作为 TensorRT 引擎高效运行,从而最大限度地提高性能和实时处理能力。WhiperSpeech 是通过 torch.compile 进行优化的。
特征
-
实时语音转文本:利用 OpenAI WhisperLive 将口语实时转换为文本。
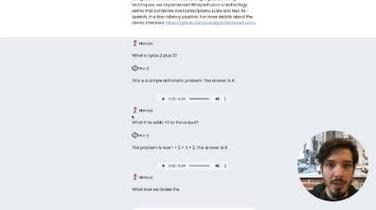 (图片来源网络,侵删)
(图片来源网络,侵删) -
大型语言模型集成:添加大型语言模型 Mistral,以增强对转录文本的理解和上下文。
-
TensorRT 优化:LLM 和 Whisper 都经过优化,可作为 TensorRT 引擎运行,确保高性能和低延迟处理。
-
torch.compile:WhisperSpeech 使用 torch.compile 来加速推理,通过将 PyTorch 代码 JIT 编译到优化的内核中,使 PyTorch 代码运行得更快。
入门
-
我们提供了一个预构建的 TensorRT-LLM docker 容器,该容器将 Whisper 和 phi 转换为 TensorRT 引擎,并且预先下载 WhisperSpeech 模型以快速开始与 WhisperFusion 交互。
docker run --gpus all --shm-size 64G -p 6006:6006 -p 8888:8888 -it ghcr.io/collabora/whisperfusion:latest
-







