

一、基本介绍
微软联合Facebook等在2017年搞了个深度学习以及机器学习模型的格式标准–ONNX,旨在将所有模型格式统一为一致,更方便地实现模型部署。现在大多数的深度学习框架都支持ONNX模型转出并提供相应的导出接口。
ONNXRuntime(Open Neural Network Exchange)是微软推出的一款针对ONNX模型格式的推理框架,用户可以非常便利的用其运行一个onnx模型。ONNXRuntime支持多种运行后端包括CPU,GPU,TensorRT,DML等。可以说ONNXRuntime是对ONNX模型最原生的支持,只要掌握模型导出的相应操作,便能对将不同框架的模型进行部署,提高开发效率。
利用onnx和onnxruntime实现pytorch深度框架使用C++推理进行服务器部署,模型推理的性能是比python快很多的。
1、下载
GitHub下载地址:
https://github.com/microsoft/onnxruntime/releases
Release ONNX Runtime v1.9.0 · microsoft/onnxruntime · GitHub
onnxruntime-linux-x64-1.9.0.tgz
2、解压
下载的onnxruntime是直接编译好的库文件,直接放在自定义的文件夹中即可。在CMakeLists.txt中引入onnxruntime的头文件、库文件即可。
# 引入头文件 include_directories(......../onnxruntime/include) # 引入库文件 link_directories(......../onnxruntime/lib)
二、Pytorch导出.onnx模型
首先,利用pytorch自带的torch.onnx模块导出 .onnx 模型文件,具体查看该部分pytorch官方文档,主要流程如下:
import torch
checkpoint = torch.load(model_path)
model = ModelNet(params)
model.load_state_dict(checkpoint['model'])
model.eval()
input_x_1 = torch.randn(10,20)
input_x_2 = torch.randn(1,20,5)
output, mask = model(input_x_1, input_x_2)
torch.onnx.export(model,
(input_x_1, input_x_2),
'model.onnx',
input_names = ['input','input_mask'],
output_names = ['output','output_mask'],
opset_version=11,
verbose = True,
dynamic_axes={'input':{1,'seqlen'}, 'input_mask':{1:'seqlen',2:'time'},'output_mask':{0:'time'}})
torch.onnx.export参数在文档里面都有,opset_version对应的版本很重要,dynamic_axes是对输入和输出对应维度可以进行动态设置,不设置的话输入和输出的Tensor 的 shape是不能改变的,如果输入固定就不需要加。
导出的模型可否顺利使用可以先使用python进行检测
import onnxruntime as ort
import numpy as np
ort_session = ort.InferenceSession('model.onnx')
outputs = ort_session.run(None,{'input':np.random.randn(10,20),'input_mask':np.random.randn(1,20,5)})
# 由于设置了dynamic_axes,支持对应维度的变化
outputs = ort_session.run(None,{'input':np.random.randn(10,5),'input_mask':np.random.randn(1,26,2)})
# outputs 为 包含'output'和'output_mask'的list
import onnx
model = onnx.load('model.onnx')
onnx.checker.check_model(model)
如果没有异常代表导出的模型没有问题,目前torch.onnx.export只能对部分支持的Tensor操作进行识别,详情参考Supported operators,对于包括transformer等基本的模型都是没有问题的,如果出现ATen等问题,你就需要对模型不支持的Tensor操作进行改进,以免影响C++对该模型的使用。
三、模型推理流程
总体来看,整个ONNXRuntime的运行可以分为三个阶段:
- Session构造;
- 模型加载与初始化;
- 运行;
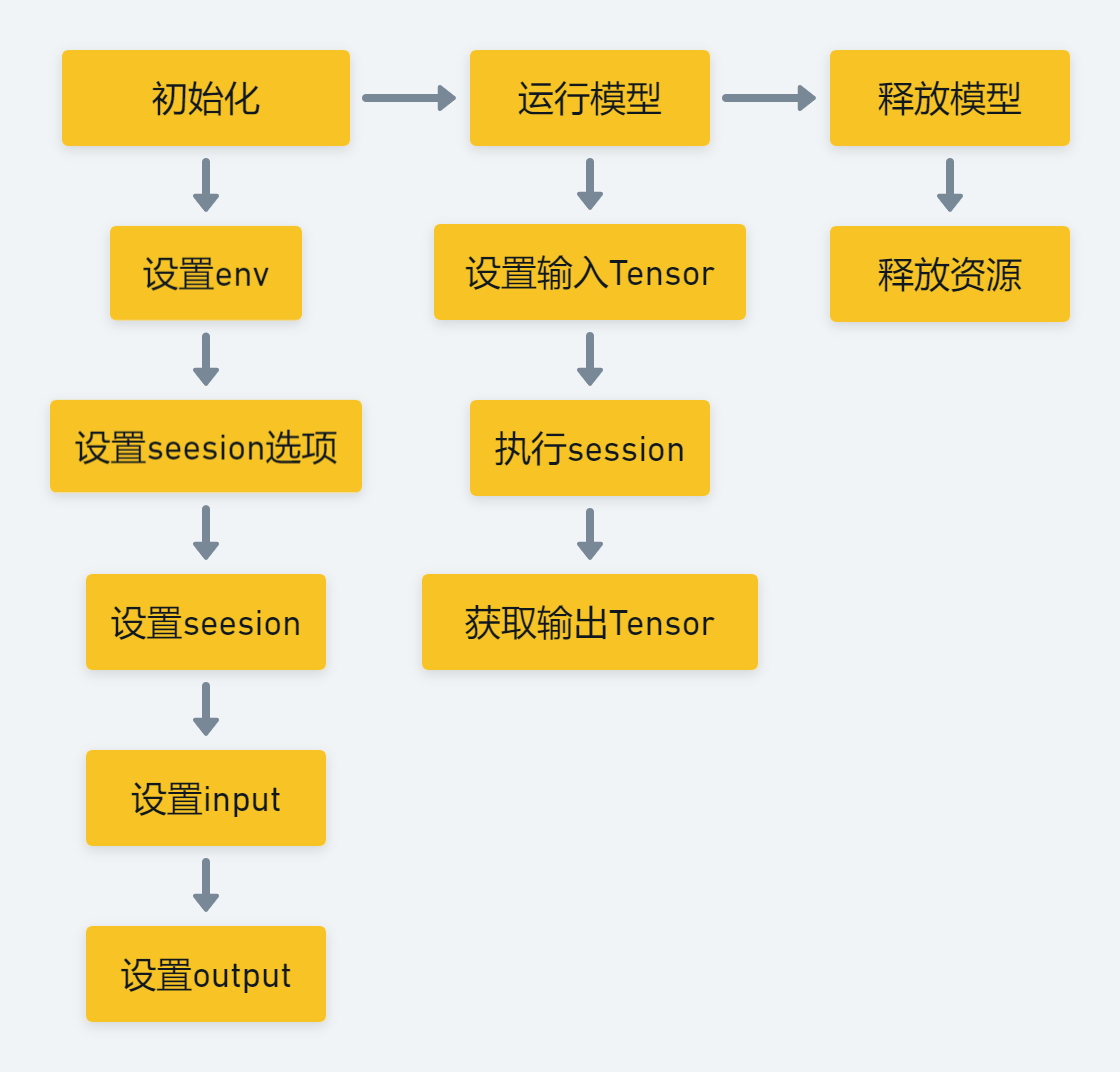
1、第1阶段:Session构造
构造阶段即创建一个InferenceSession对象。在python前端构建Session对象时,python端会通过http://onnxruntime_pybind_state.cc调用C++中的InferenceSession类构造函数,得到一个InferenceSession对象。
InferenceSession构造阶段会进行各个成员的初始化,成员包括负责OpKernel管理的KernelRegistryManager对象,持有Session配置信息的SessionOptions对象,负责图分割的GraphTransformerManager,负责log管理的LoggingManager等。当然,这个时候InferenceSession就是一个空壳子,只完成了对成员对象的初始构建。
2、第2阶段:模型加载与初始化
在完成InferenceSession对象的构造后,会将onnx模型加载到InferenceSession中并进行进一步的初始化。
2.1. 模型加载
模型加载时,会在C++后端会调用对应的Load()函数,InferenceSession一共提供了8种Load函数。包读从url,ModelProto,void* model data,model istream等读取ModelProto。InferenceSession会对ModelProto进行解析然后持有其对应的Model成员。
2.2. Providers注册
在Load函数结束后,InferenceSession会调用两个函数:RegisterExecutionProviders()和sess->Initialize();
RegisterExecutionProviders函数会完成ExecutionProvider的注册工作。这里解释一下ExecutionProvider,ONNXRuntime用Provider表示不同的运行设备比如CUDAProvider等。目前ONNXRuntimev1.0支持了包括CPU,CUDA,TensorRT,MKL等七种Providers。通过调用sess->RegisterExecutionProvider()函数,InferenceSession通过一个list持有当前运行环境中支持的ExecutionProviders。
2.3. InferenceSession初始化
即sess->Initialize(),这时InferenceSession会根据自身持有的model和execution providers进行进一步的初始化(在第一阶段Session构造时仅仅持有了空壳子成员变量)。该步骤是InferenceSession初始化的核心,一系列核心操作如内存分配,model partition,kernel注册等都会在这个阶段完成。
- 首先,session会根据level注册 graph optimization transformers,并通过GraphTransformerManager成员进行持有。
- 接下来session会进行OpKernel注册,OpKernel即定义的各个node对应在不同运行设备上的计算逻辑。这个过程会将持有的各个ExecutionProvider上定义的所有node对应的Kernel注册到session中,session通过KernelRegistryManager成员进行持有和管理。
- 然后session会对Graph进行图变换,包括插入copy节点,cast节点等。
- 接下来是model partition,也就是根运行设备对graph进行切分,决定每个node运行在哪个provider上。
- 最后,为每个node创建ExecutePlan,运行计划主要包含了各个op的执行顺序,内存申请管理,内存复用管理等操作。
3、第3阶段:模型运行
模型运行即InferenceSession每次读入一个batch的数据并进行计算得到模型的最终输出。然而其实绝大多数的工作早已经在InferenceSession初始化阶段完成。细看下源码就会发现run阶段主要是顺序调用各个node的对应OpKernel进行计算。
四、代码
和其他所有主流框架相同,ONNXRuntime最常用的语言是python,而实际负责执行框架运行的则是C++。
下面就是C++通过onnxruntime对.onnx模型的使用,参考官方样例和常见问题写的模型多输入多输出的情况,部分参数可以参考样例或者查官方API文档。
1、案例01
BasicOrtHandler.h
#include "onnxruntime_cxx_api.h" #include "opencv2/opencv.hpp" #include #define CHW 0 class BasicOrtHandler { public: Ort::Value BasicOrtHandler::create_tensor(const cv::Mat &mat, const std::vector &tensor_dims, const Ort::MemoryInfo &memory_info_handler, std::vector &tensor_value_handler, unsigned int data_format); protected: Ort::Env ort_env; Ort::Session *ort_session = nullptr; const char *input_name = nullptr; std::vector input_node_names; std::vector input_node_dims; // 1 input only. std::size_t input_tensor_size = 1; std::vector input_values_handler; // create input tensor Ort::MemoryInfo memory_info_handler = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault); std::vector output_node_names; std::vector output_node_dims; // >=1 outputs const char*onnx_path = nullptr; const char *log_id = nullptr; int num_outputs = 1; protected: const unsigned int num_threads; // initialize at runtime. protected: explicit BasicOrtHandler(const std::string &_onnx_path, unsigned int _num_threads = 1); virtual ~BasicOrtHandler(); protected: BasicOrtHandler(const BasicOrtHandler &) = delete; BasicOrtHandler(BasicOrtHandler &&) = delete; BasicOrtHandler &operator=(const BasicOrtHandler &) = delete; BasicOrtHandler &operator=(BasicOrtHandler &&) = delete; protected: virtual Ort::Value transform(const cv::Mat &mat) = 0; private: void initialize_handler(); };BasicOrtHandler.cpp
BasicOrtHandler::BasicOrtHandler(const std::string &_onnx_path, unsigned int _num_threads) : log_id(_onnx_path.data()), num_threads(_num_threads) { // string to wstring #ifdef LITE_WIN32 std::wstring _w_onnx_path(lite::utils::to_wstring(_onnx_path)); onnx_path = _w_onnx_path.data(); #else onnx_path = _onnx_path.data(); #endif initialize_handler(); } void BasicOrtHandler::initialize_handler() { // set ort env ort_env = Ort::Env(ORT_LOGGING_LEVEL_ERROR, log_id); // 0. session options Ort::SessionOptions session_options; // set op threads session_options.SetIntraOpNumThreads(num_threads); // set Optimization options: session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL); // set log level session_options.SetLogSeverityLevel(4); // GPU compatiable. // OrtCUDAProviderOptions provider_options; // session_options.AppendExecutionProvider_CUDA(provider_options); // #ifdef USE_CUDA // OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0); // C API stable. // #endif // 1. session ort_session = new Ort::Session(ort_env, onnx_path, session_options); // memory allocation and options Ort::AllocatorWithDefaultOptions allocator; // 2. input name & input dims input_name = ort_session->GetInputName(0, allocator); input_node_names.resize(1); input_node_names[0] = input_name; // 3. input names & output dimms Ort::TypeInfo type_info = ort_session->GetInputTypeInfo(0); auto tensor_info = type_info.GetTensorTypeAndShapeInfo(); input_tensor_size = 1; input_node_dims = tensor_info.GetShape(); for (unsigned int i = 0; i GetOutputCount(); output_node_names.resize(num_outputs); for (unsigned int i = 0; i GetOutputName(i, allocator); Ort::TypeInfo output_type_info = ort_session->GetOutputTypeInfo(i); auto output_tensor_info = output_type_info.GetTensorTypeAndShapeInfo(); auto output_dims = output_tensor_info.GetShape(); output_node_dims.push_back(output_dims); } } Ort::Value BasicOrtHandler::create_tensor(const cv::Mat &mat, const std::vector &tensor_dims, const Ort::MemoryInfo &memory_info_handler, std::vector &tensor_value_handler, unsigned int data_format) throw(std::runtime_error) { const unsigned int rows = mat.rows; const unsigned int cols = mat.cols; const unsigned int channels = mat.channels(); cv::Mat mat_ref; if (mat.type() != CV_32FC(channels)){ mat.convertTo(mat_ref, CV_32FC(channels)); } else{ mat_ref = mat; // reference only. zero-time cost. support 1/2/3/... channels } if (tensor_dims.size() != 4) { throw std::runtime_error("dims mismatch."); } if (tensor_dims.at(0) != 1) { throw std::runtime_error("batch != 1"); } // CXHXW if (data_format == CHW) { const unsigned int target_channel = tensor_dims.at(1); const unsigned int target_height = tensor_dims.at(2); const unsigned int target_width = tensor_dims.at(3); const unsigned int target_tensor_size = target_channel * target_height * target_width; if (target_channel != channels) { throw std::runtime_error("channel mismatch."); } tensor_value_handler.resize(target_tensor_size); cv::Mat resize_mat_ref; if (target_height != rows || target_width != cols) { cv::resize(mat_ref, resize_mat_ref, cv::Size(target_width, target_height)); } else{ resize_mat_ref = mat_ref; // reference only. zero-time cost. } std::vector mat_channels; cv::split(resize_mat_ref, mat_channels); // CXHXW for (unsigned int i = 0; imain.cpp
const std::string _onnx_path=""; unsigned int _num_threads = 1; //init inference BasicOrtHandler basicOrtHandler(_onnx_path,_num_threads); // after transform image const cv::Mat mat = ""; const std::vector &tensor_dims = basicOrtHandler.input_node_dims; const Ort::MemoryInfo &memory_info_handler = basicOrtHandler.memory_info_handler; std::vector &tensor_value_handler = basicOrtHandler.input_values_handler; unsigned int data_format = CHW; // 预处理后的模式 // 1. make input tensor Ort::Value input_tensor = basicOrtHandler.create_tensor(mat_rs); // 2. inference scores & boxes. auto output_tensors = ort_session->Run(Ort::RunOptions{nullptr}, input_node_names.data(), &input_tensor, 1, output_node_names.data(), num_outputs); // 3. get output tensor Ort::Value &pred = output_tensors.at(0); // (1,n,c) //postprocess ...2、案例02
#include #include #include int main(int argc, char* argv[]) { Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "test"); Ort::SessionOptions session_options; session_options.SetIntraOpNumThreads(1); session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_EXTENDED); #ifdef _WIN32 const wchar_t* model_path = L"model.onnx"; #else const char* model_path = "model.onnx"; #endif Ort::Session session(env, model_path, session_options); // print model input layer (node names, types, shape etc.) Ort::AllocatorWithDefaultOptions allocator; // print number of model input nodes size_t num_input_nodes = session.GetInputCount(); std::vector input_node_names = {"input","input_mask"}; std::vector output_node_names = {"output","output_mask"}; std::vector input_node_dims = {10, 20}; size_t input_tensor_size = 10 * 20; std::vector input_tensor_values(input_tensor_size); for (unsigned int i = 0; i编译命令:
g++ infer.cpp -o infer onnxruntime-linux-x64-1.4.0/lib/libonnxruntime.so.1.4.0 -Ionnxruntime-linux-x64-1.4.0/include/ -std=c++11
onnxruntime中Tensor支持的数据类型包括:
typedef enum ONNXTensorElementDataType { ONNX_TENSOR_ELEMENT_DATA_TYPE_UNDEFINED, ONNX_TENSOR_ELEMENT_DATA_TYPE_FLOAT, // maps to c type float ONNX_TENSOR_ELEMENT_DATA_TYPE_UINT8, // maps to c type uint8_t ONNX_TENSOR_ELEMENT_DATA_TYPE_INT8, // maps to c type int8_t ONNX_TENSOR_ELEMENT_DATA_TYPE_UINT16, // maps to c type uint16_t ONNX_TENSOR_ELEMENT_DATA_TYPE_INT16, // maps to c type int16_t ONNX_TENSOR_ELEMENT_DATA_TYPE_INT32, // maps to c type int32_t ONNX_TENSOR_ELEMENT_DATA_TYPE_INT64, // maps to c type int64_t ONNX_TENSOR_ELEMENT_DATA_TYPE_STRING, // maps to c++ type std::string ONNX_TENSOR_ELEMENT_DATA_TYPE_BOOL, ONNX_TENSOR_ELEMENT_DATA_TYPE_FLOAT16, ONNX_TENSOR_ELEMENT_DATA_TYPE_DOUBLE, // maps to c type double ONNX_TENSOR_ELEMENT_DATA_TYPE_UINT32, // maps to c type uint32_t ONNX_TENSOR_ELEMENT_DATA_TYPE_UINT64, // maps to c type uint64_t ONNX_TENSOR_ELEMENT_DATA_TYPE_COMPLEX64, // complex with float32 real and imaginary components ONNX_TENSOR_ELEMENT_DATA_TYPE_COMPLEX128, // complex with float64 real and imaginary components ONNX_TENSOR_ELEMENT_DATA_TYPE_BFLOAT16 // Non-IEEE floating-point format based on IEEE754 single-precision } ONNXTensorElementDataType;其中需要注意的是使用bool型,需要从uint_8的vector转为bool型:
std::vector mask_tensor_values; for(int i = 0; i
性能测试
实际情况粗略统计,以transformer为例,onnxruntime-c++上的运行效率要比pytorch-python快2-5倍
C++-onnx:用onnxruntime部署自己的模型_u013250861的博客-CSDN博客
ONNX Runtime使用简单介绍_竹叶青lvye的博客-CSDN博客_onnxruntime 使用
onnxruntime的c++使用_chencision的博客-CSDN博客_c++ onnxruntime
onnxruntime C++ 使用(一)_SongpingWang的技术博客_51CTO博客
OnnxRunTime的推理流程_hjxu2016的博客-CSDN博客_onnxruntime
onnxruntime安装与使用(附实践中发现的一些问题)_本初-ben的博客-CSDN博客_onnxruntime安装







