

| info | |
|---|---|
| paper | Prompt-to-Prompt Image Editing with Cross Attention Control |
| github | https://github.com/google/prompt-to-prompt |
| Org: | Google Research |
| 个人复现 | https://github.com/myhz0606/diffusion_learning |
| 个人博客主页 | http://myhz0606.com/article/p2p |
1 前言
基于扩散模型(diffusion model)的图片编辑技术当下取得了飞跃的进展,涌现出了大量优秀的工作,例如:InstructPix2Pix[1]和EmuEdit[2]。这些工作致力于实现直接通过文字指令来编辑图片,极大地提升了传统图像编辑流程的效率。这种新兴的技术领域被称作基于指令的图像编辑(instruction-based image editing)。饮水思源,这类技术成功的背后,离不开Google在2022年提出的Prompt-to-Prompt(下文简称为p2p)这项工作。
为了深入理解技术细节,笔者借鉴google的开源代码对其进行复现。
2 P2P提出的Motivation
目前大火的文生图技术(text to image),给定一段文本(prompt)和随机种子,文生图模型会基于这两者生成一张图片。生成图片的不同由两个变量决定
- 随机种子。随机种子决定初始的噪声 x T x_T xT。
- prompt。prompt是通过文本编码器(如CLIP的text encoder)转为语义向量再送入到diffusion model的cross-attention层中与图片信息交互。
假定up sampler不引入随机性,如DDIM; classifier-guidance-score; generation step是系统变量维持不变
如果我们固定了随机种子,仅微小的改变prompt,输出的图片是否相似?如果可行,那么根据这个特性,很方便的可以通过修改prompt来编辑图片了。很遗憾,事情没有那么简单。仅微小改动prompt,输出的图片也有很大差异。下图展示了固定随机种子,仅更改蛋糕种类的生成结果。

过去为了解决上述问题,Repaint[3]、Diffedit[4]在做图片编辑时,会引入一个mask,在编辑阶段,只更新mask区域的像素值,这类方法也取得了一些令人惊叹的结果,但上述方法同样存在三个问题:
- 需要手动构建mask,比较麻烦。(现在一般会接入SAM[5]来加速这个过程)
- 由于在编辑过程只修改mask区域的像素值,未考虑mask区域与非mask区域的结构信息,导致生成的图片语义连贯性较差。
- 这类方法只能实现object-level的编辑,无法实现图片风格、纹理的编辑。
在这篇文章中,作者提出了一种p2p的文字编辑方法(textual editing),无需训练任何参数、添加任何模块,仅用预训练的文生图模型(如stable diffusion)即能实现卓越的textual editing能力。下图展示了引入p2p技术后,同样的随机种子和prompt的生成结果。

下面来看p2p具体是怎么做的吧。
3 方法
3.1 什么是prompt-to-prompt 🤔
通过上面的背景和动机介绍,我们知道p2p做的是这样一件事:
给定原始图片的prompt( P \mathcal{P} P)与编辑图片的prompt ( P ∗ \mathcal{P}^* P∗),通过文生图模型,分别获得原始图片 I \mathcal{I} I与编辑后的图片 I ∗ \mathcal{I}^* I∗。 I \mathcal{I} I 与 I ∗ \mathcal{I}^* I∗除了编辑区域外尽可能的近。
举个🌰,当我输入prompt a photo of a house on a mountain.用文生图生成了一张在山上的房子的图片,现在我们想维持生成图片的整体布局,仅将其改为冬景。用p2p技术可以很方便实现,如下图所示
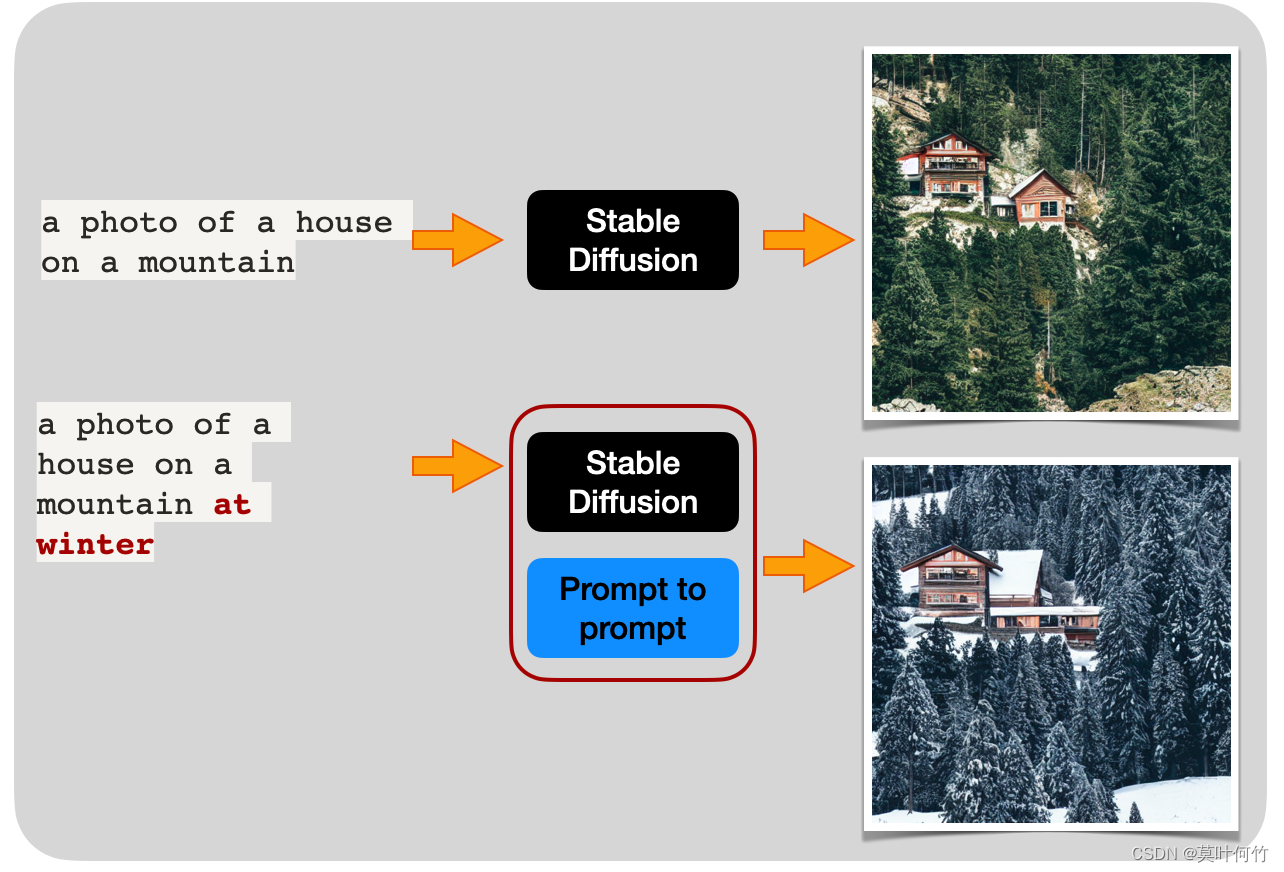
3.2 prompt-to-prompt的具体实现 🤔
在详细介绍p2p之前,我们先来回答motivation中的一个问题。
为什么给定了随机种子,仅微小的改变prompt,输出的图片却差异很大?
我们知道在文生图中,prompt与diffusion model是在cross-attention层进行交互(text embedding作为cross-attention的key和value)。如下图所示(灰色的块代表mask)。
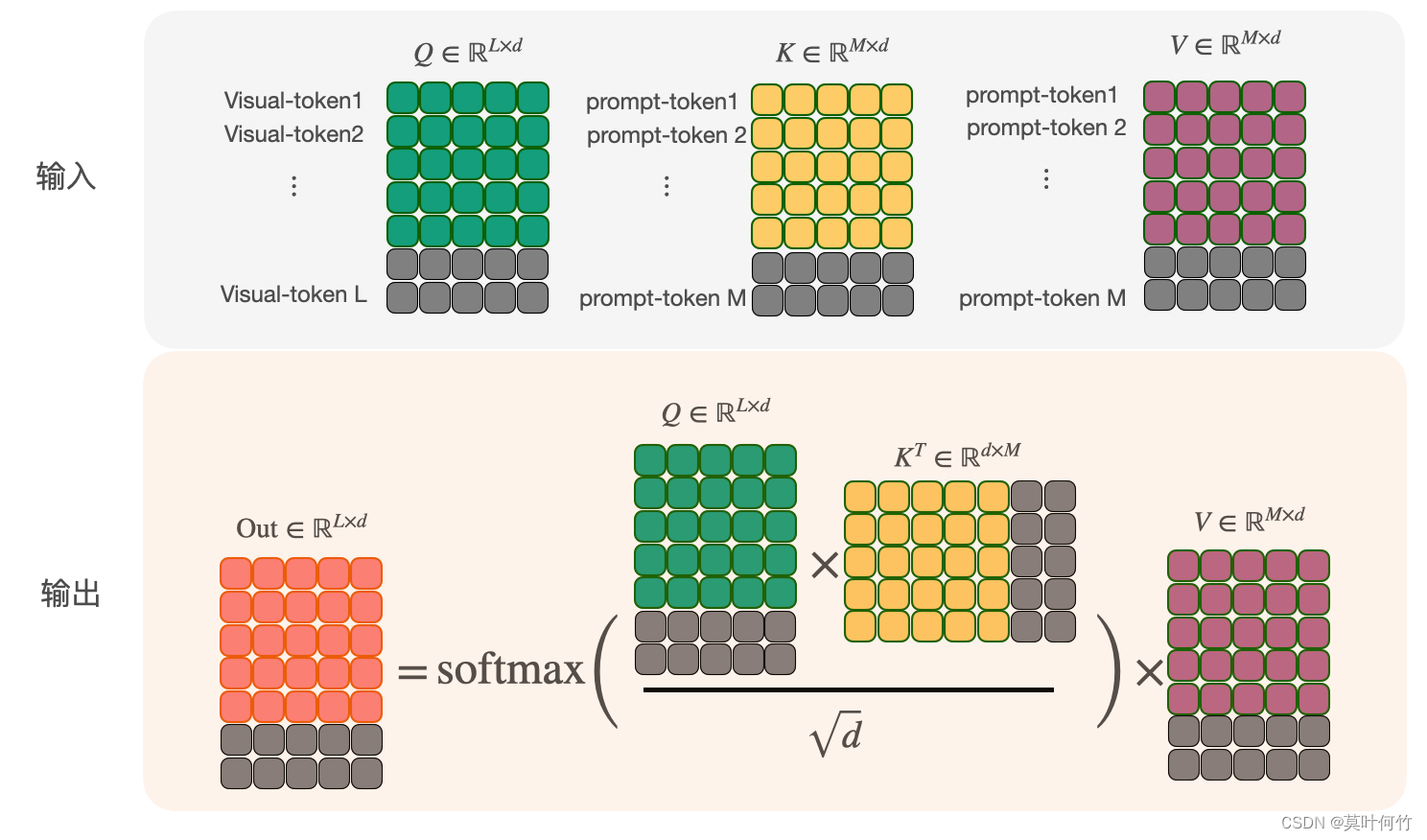
📌忘记文生图条件融合的话,可以回顾 classifier-free guided的内容。
假定当prompt的第二个token发生改变时,根据下图的计算流,可以看到整个attention score的数值都会发生改变。从而导致最终输出结果发生改变。
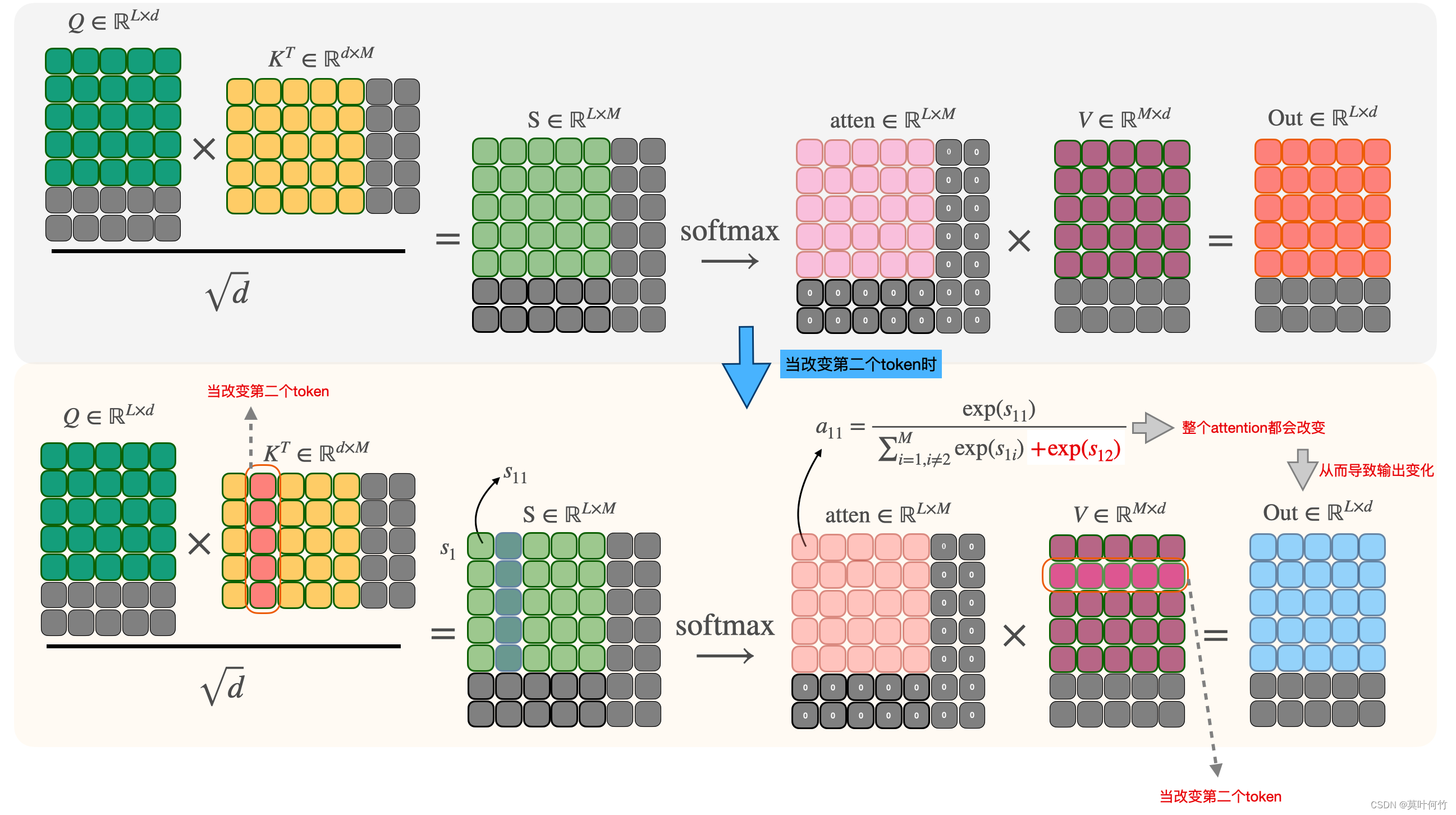
3.2.1 cross-attention对生成图片的影响
通过对diffusion model网络内部的观察,作者发现生成图片的空间布局和几何形状都是由内部的cross-attention层的attention map决定(上图的 a t t e n \mathrm{atten} atten)。下图是由prompt: “a furry bear watching a bird”生成的图片,我们分别看每一个token对应的attention map对应生成图片的相应位置。并在time step的早期这个对应关系就已形成。
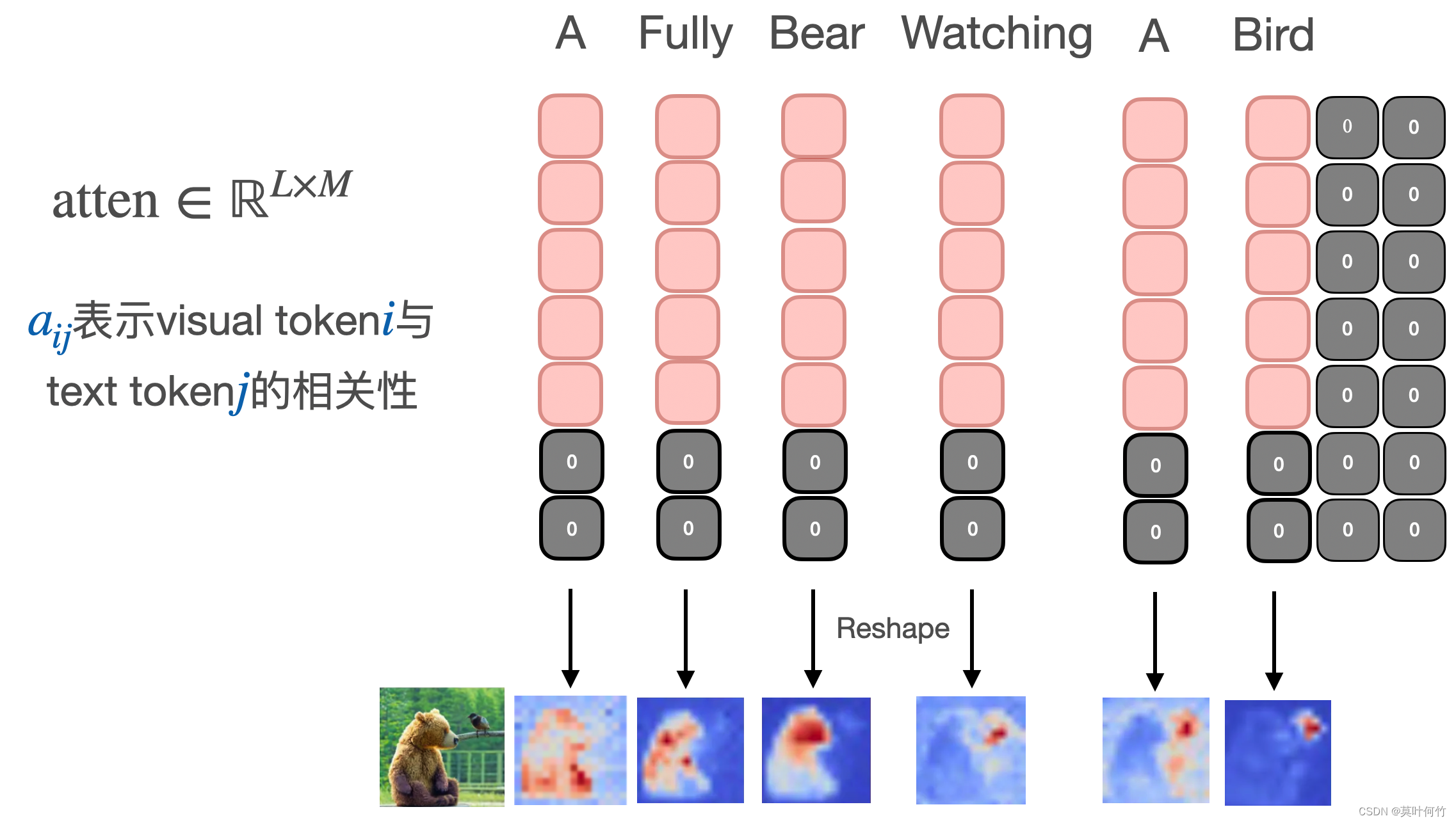
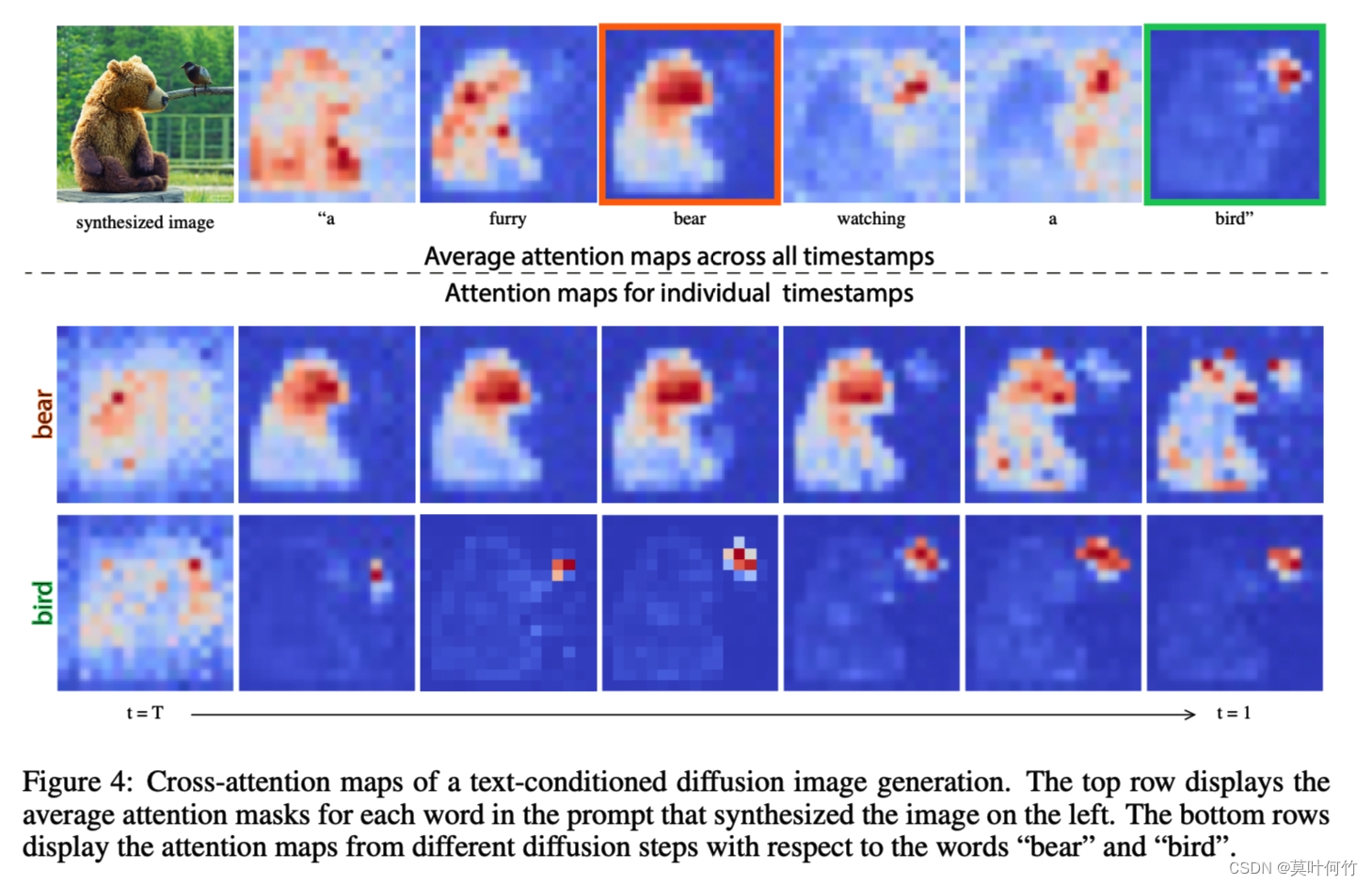
这里提供一张attention map随时间步变化的gif图。

3.2.1 controlling the cross-attention
control的思路很简单。既然cross-attention的attention map决定生成图片的结构信息,那我们维持原始的attention map即可。
p2p的整体算法流程如下图所示
每一个时间步 t t t分别计算原始prompt P \mathcal{P} P的attention map M t M_t Mt和新的prompt P ∗ \mathcal{P}^* P∗的attention map M t ∗ M^*_t Mt∗并用特定的替换规则 E d i t ( M t , M t ∗ , t ) Edit(M_t, M_t^*, t) Edit(Mt,Mt∗,t)替换后再进行生成。

作者根据不同的编辑类型,设计了不同的替换方式
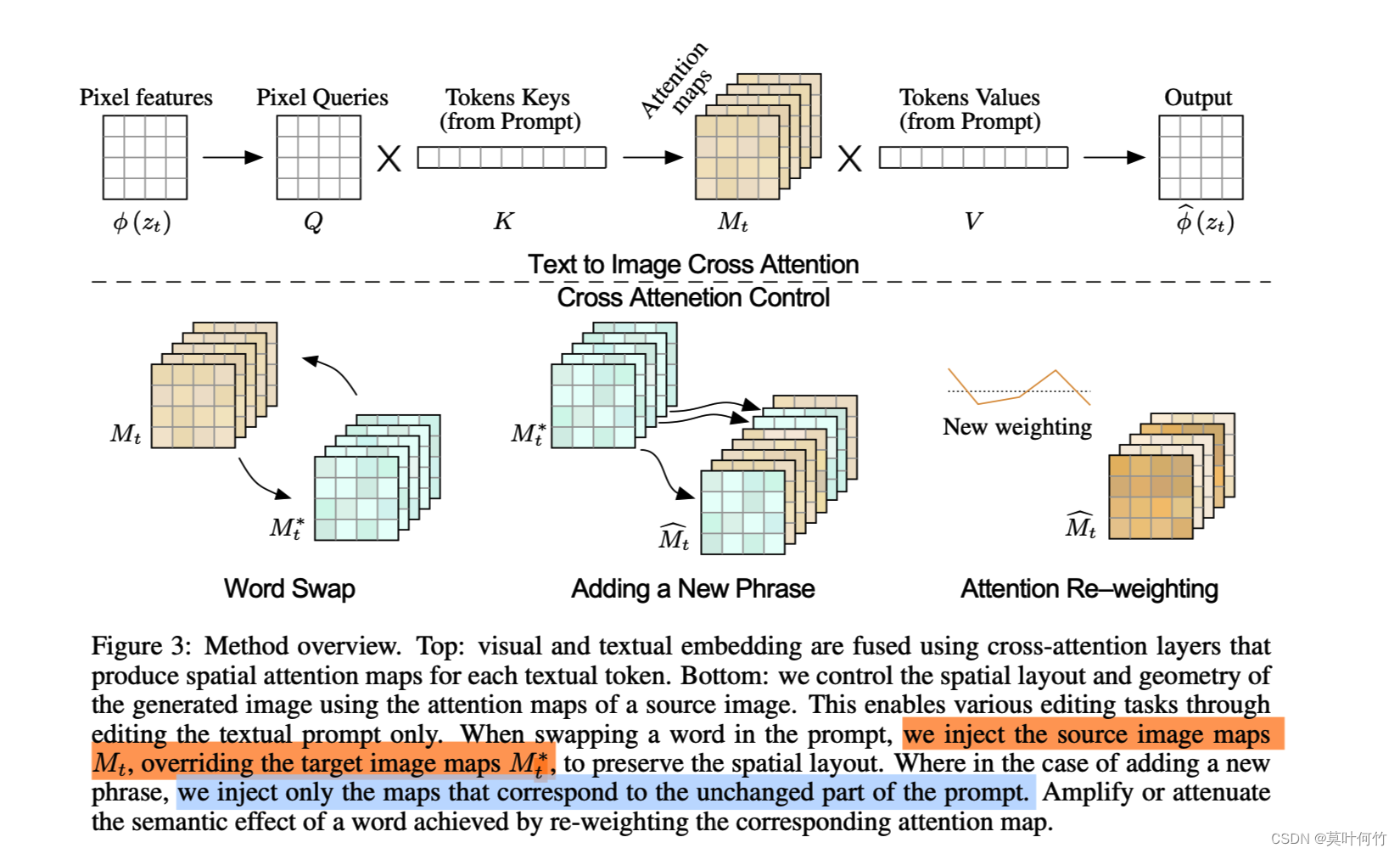
(一)Word Swap
这个编辑类型是指将原始prompt中的某个token用新的token进行替换。 P = \mathcal{P} = P= “photo of a cat riding on a bicycle”, P ∗ = \mathcal{P}^* = P∗= “photo of a cat riding on a motorcycle”。此时的替换规则是
E d i t ( M t , M t ∗ , t ) : = { M t ∗ i f t







