

文章目录
- 前言
- 一、本次比赛任务分工
- 二、OpenArt部分任务
- 1.地图识别
- 2.图像识别
- 1)模型训练
- 2)图像处理
- 3)通讯
- 总结
前言
我参加了第十七届全国大学生智能汽车竞赛智能视觉组的比赛。在此之前,我参加过校内的智能车竞赛,不过彼时是负责硬件。经过校赛后,发现自己对硬件方面的兴趣并不浓厚,想尝试负责软件方面。恰巧我当时曾学习过Python的基本语法,便想尝试智能视觉组的OpenArt部分。
我有幸和两名优秀的队友共事,调车的过程很愉快,享受到了努力备赛的乐趣,是一段非常值得的经历。虽然比赛的结果不尽人意,但是也算没有白费半年的努力。
为了能给未来的自己留下点东西,纪念一下这段时光,虽然在技术和思想方面乏善可陈,也会有许多漏洞,但也想记录下来。或许能为其他对智能车感兴趣的朋友提供一点帮助,也是荣幸之至。

一、本次比赛任务分工
第十七届的智能视觉组比赛省赛的任务简单来讲,就是通过读取地图,寻找并识别随机分布在5*4场地内的矩形图片,然后搬运到相对应的边界。
在本次比赛当中,智能视觉组可以有三名成员。我们组将整辆车要实现的功能大致分为三个部分:硬件部分、整车控制部分、OpenArt部分。硬件部分负责电路板的制作和机械结构的设计,整车控制部分包括车体的动作控制,OpenArt部分负责和OpenArt有关的功能实现(地图读取、图像识别)。
比赛场地示意图:
识别用的地图:
裁判员使用的地图:
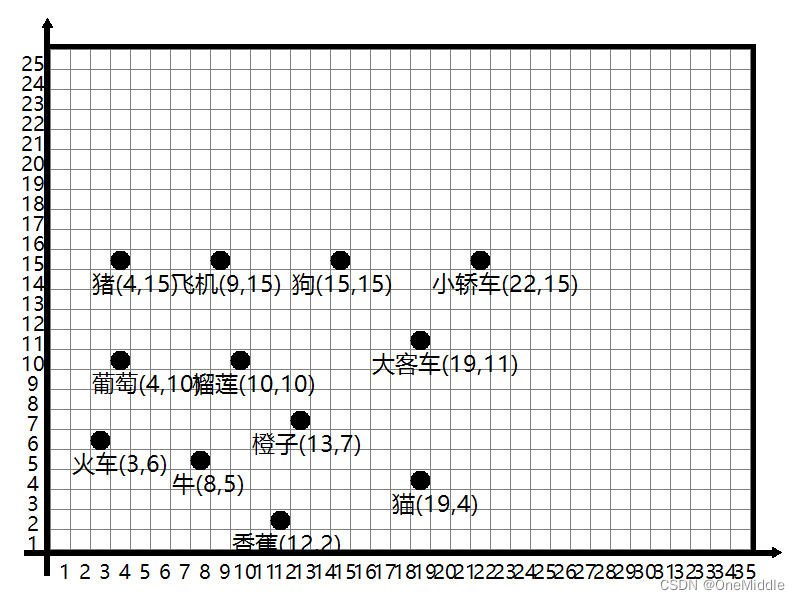
识别用的图片:

二、OpenArt部分任务
我们比赛使用的是OpenArt mini。OpenArt mini是逐飞在 NXP 的 OpenART 套件的基础上,去除非视觉部分而制作出来的迷你版。可以实现很多机器视觉处理,并且可以完成神经网络模型的部署和训练。在机器视觉处理方面,Art的函数库和MV的十分接近,基本可以照搬,因此大多OpenMV的资料也适用于OpenArt,但Art更像是MV的阉割版。
比赛OpenArt部分要实现的功能主要是以下两部分:
1.地图识别
比赛时参赛选手将抽取如下图所示的地图。图中点对应的是场地上的图片。需注意的是该地图的矩形框对应的其实是规则修改前5 * 7的场地,而不是实际上5 * 4的场地。识别地图其实就是将图中点与矩形的分布关系映射到实际场地上。
为解决这个问题则需要获取到矩形框四个角在图像中的坐标和圆点在图像中的坐标。
由于地图识别完全可用二值化后的图像完成任务,并且这样对矩形和圆点处理更快,识别效果更好,因此地图识别采用的是二值化图像。
light_threshold = (35, 100) # 二值化的阈值
通过对二值化阈值的调节可以很容易适应不同光照条件下的地图识别。
矩形识别和圆点识别的话可以用Art的函数库中的 find_rects() 和 find_circles() 轻松完成。通过修改函数参数可以修改识别范围和敏感程度等。函数分别返回Rect类和Cricle类,可通过访问类对象获得查找到的矩形或圆点的位置信息,使用的时候可自行查找相关资料。
在Art的库函数中,还存在许多绘图函数。如 draw_circle(), draw_rectangle() 等,可根据需要添加入代码中,使得结果更方便观察。
代码示例:
img = sensor.snapshot().lens_corr(1.5) img = img.binary([light_threshold]) # 图像二值化 if len(img.find_rects(threshold=RECT_THRESHOLD)) != 0: for r in img.find_rects(threshold=RECT_THRESHOLD): # 寻找合适的矩形,直到找到并得出四个点的坐标 angle_list = r.corners() width = r.rect()[2] height = r.rect()[3] rect_rect = r.rect() if widthcircle_find = img.find_circles(roi=rect_rect, threshold=CIRCLE_THRESHOLD, x_margin=10, y_margin=10, r_margin=10, r_min=2, r_max=5, r_step=1) if len(circle_find) != 0: list_x = [] list_y = [] list_dir = [] for r in circle_find: # 将检测到的各个点的xy坐标分别存到数组当中 img.draw_circle(r.x(), r.y(), r.r(), color=(255, 0, 0), thickness=5) list_x.append(r.x()) list_y.append(r.y())由于地图识别难免偶尔会出现错误,如圆点漏找或者多找,如果此时贸然发车则会导致此次发车成绩不理想。为解决这个问题,我将地图识别任务分为两段进行:矩形的识别和圆点的识别。矩形识别在绝大数情况下并不会出错,出错主要发生在圆点的识别上。我代码的逻辑是,按键后拍摄图像,首先进行矩形的识别,寻找到合适的矩形时,在矩形内部寻找圆点,只有找齐规定数量的圆点后才能完成地图识别任务,如果不能找齐规定数量的圆点,则会自动拍摄新图像,寻找矩形,重复之前操作。 经过测试,这样的逻辑可以一定程度上降低圆点数量不正确的问题。在代码中,我使用两个标志位来控制。
代码示例:
... while (flag1 == 0 or flag2 == 0): # 只有当寻找矩形和寻找各个点的任务完成后,退出循环,完成地图识别 ... while (flag1 == 1 and flag2 == 0): # 当矩形已经确认而圆点未确认时,运行循环,找出矩形框中的点 ... if len(list_dir) != NUM: # 判断是否识别全所有点 flag1 = 0 # 找齐所有的点则完成地图识别 else: flag2 = 1 # 识别点数不正确则重复操作 ...
此时我们已经获取到了矩形四个角的坐标和各圆点的坐标,便可通过一定的算法将它们映射到实际的比赛场地上。该算法并不复杂,用到了点到线的距离公式,并进行了变换,所以代码部分计算公式可能难以理解,可根据自己的理解修改计算公式。
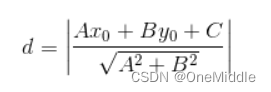
首先计算直线在坐标轴上的表达公式,然后计算点到直线的距离。
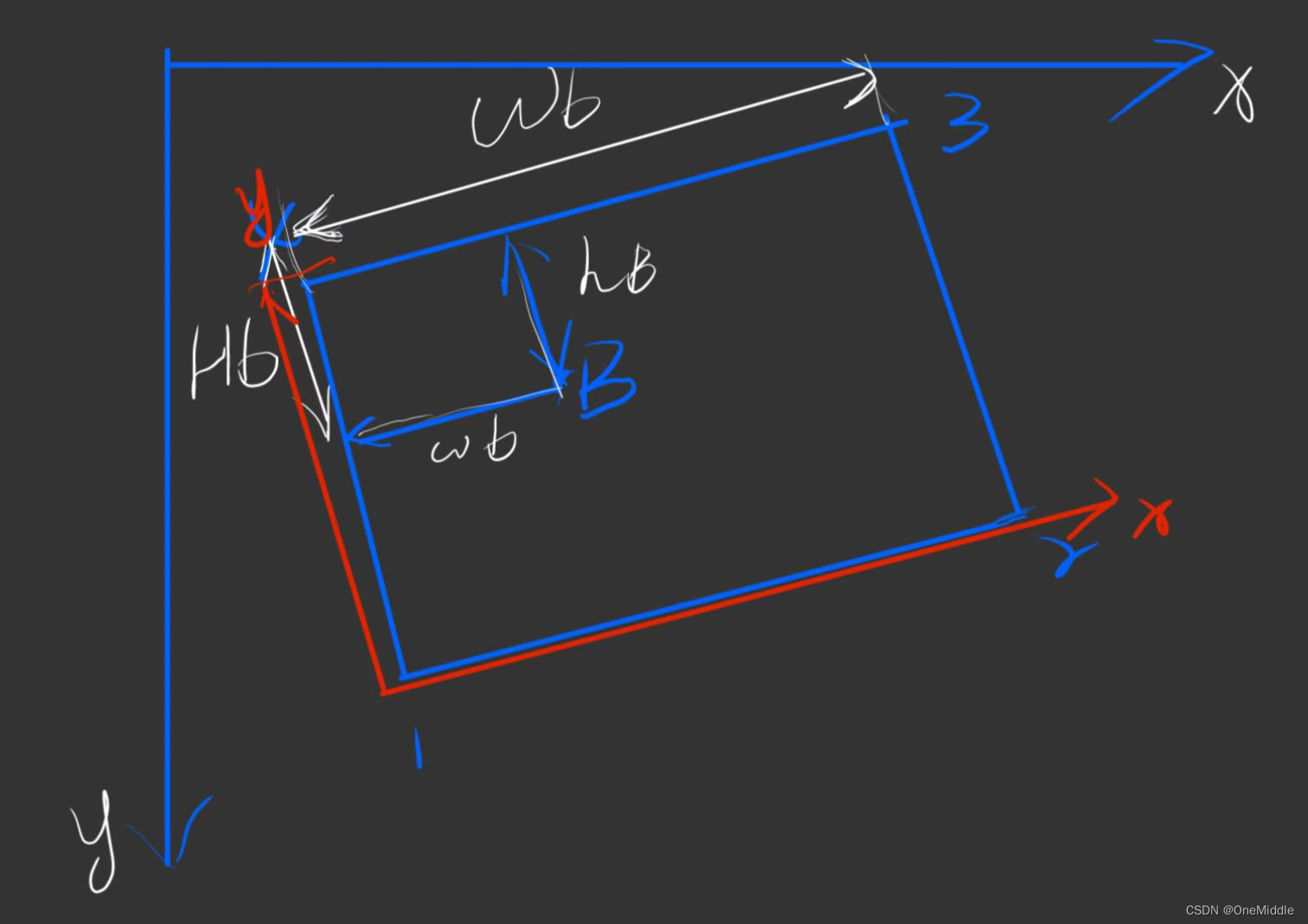
示意图:
其中蓝色的xy轴是拍摄到的图像的xy轴(计算公式中使用的xy轴),红色的xy轴是识别到的矩形的xy轴
代码示例:
'''x_A1、y_A1、x_A3、y_A3、x_A4、y_A4是矩形角1、3、4对应的xy坐标,x_B、y_B是一个圆点的xy坐标''' def direction_calculate_pro(x_A1, y_A1, x_A3, y_A3, x_A4, y_A4, x_B, y_B): p1 = 0 # 计算的中间变量 p2 = 0 p1 = pow((x_A3-x_A4), 2) p2 = pow((y_A3-y_A4), 2) Wb = pow(p1+p2, 0.5) k34 = (y_A3-y_A4)/(x_A3-x_A4) # 角34间直线的斜率 hB = abs(k34*x_B-y_B+(y_A4-k34*x_A4))/pow(pow(k34, 2)+1, 0.5) p1 = pow((x_A1-x_A4), 2) p2 = pow((y_A1-y_A4), 2) Hb = pow(p1+p2, 0.5) k14 = (y_A1-y_A4)/(x_A1-x_A4) # 角14间直线的斜率 wB = abs(k14*x_B-y_B+(y_A4-k14*x_A4))/pow(pow(k14, 2)+1, 0.5) x = (wB/Wb)*700 # 对识别到的圆点坐标进行比例放大 y = (1-(hB/Hb))*500 print([x, y]) x = int((wB/Wb)*700/20)*20 + 10 # 由于坐标在地图上可能出现的位置是规律且确定的,离散的,对坐标进行修正 y = int((1-(hB/Hb))*500/20)*20 + 10 if x 480 or y 380: # 由于时常将矩形直线上某一点识别为圆点,所以划定正常情况下圆点的坐标范围,超出范围的圆点返回计算失败,防止错误识别圆点 return 0 return [x, y] # 返回圆点在实际场地上的坐标2.图像识别
图像识别的主要任务主要是模型训练和使模型获取到易识别的图像。
在进行比赛之前,我对深度学习并无了解,但惭愧地说即使现在也是一知半解。
1)模型训练
最开始我是根据教程使用nncu,并通过批量处理图片来强化学习(旋转、曝光、裁剪等)。由于我的电脑当时莫名其妙无法使用nncu中的bat文件,因此折腾了好长一段时间,并且训练效果不佳。后来我又对最初的模型进行了修改,但效果提升不明显。不过后面使用EIQ之后训练模型比较方便。结合运行速度和准确率的需要,采用的是mobilenet_v2网络。理论上mobilenet_v2的准确率是很高的,并且轻量化方面也比较优秀,适合比赛场景。EIQ也提供了数据增强的功能,并且除了个别版本外,都可以对数据增强的效果可视化。使用者可结合使用需要实际测试来调节数据增强的参数。对于一些训练的超参数如Batch Size、Learning Rate等超参数,可以多去了解其对训练效果的影响,根据训练效果进行调整。具体情况这里就不多赘述了。
EIQ部分界面:
个人感觉使用EIQ和采用mobilenet_v2网络已经完全可以满足比赛的识别需要,模型选择和训练过程上提高识别准确度的空间其实并不大,关键在于数据集。官方给的每种图片约200张其实并不充分,且与实际比赛时OpenArt所拍摄到的图片相差较大,因此将OpenArt置于比赛条件下采取图片很重要,可以提高模型的准确率。
观察训练出的模型,我们发现了一些新问题。个别种类的图片总是误判为另一个种类。比如火车总是误判为轮船。我们观察火车和轮船的数据集,发现火车和轮船含有背景的图片是几种事物中最多的。因此为了排除背景的影响,我们对火车和轮船进行抠图处理,更换到更多不同背景下,得到新的一批图片,放入到数据集中,再次训练。可以发现准确率有所上升。
示例图:

在对数据集进行修改的时候,要时刻注意各个种类的图片数量要趋于相等,不然训练出来的模型会更倾向于将图片识别某一种类。某些种类数量较少的可随机复制部分图片来扩充。
在训练过程中,由于训练集的图片是经过数据增强的,而测试集的图片并没有,所以Train Accuracy往往会比Evaluation Accuracy低(个人推测),属于正常现象。
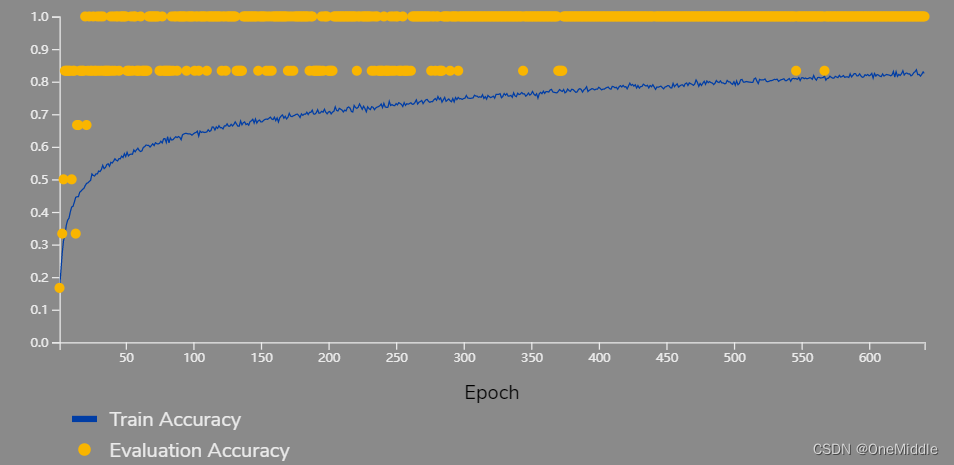
当Evaluation Accuracy基本不变时,可停止训练,防止模型过拟合。
2)图像处理
在代码中,是对图像Image对象使用模型进行图像识别。因此,我们需要想办法获得有效清晰的图像输入给模型。
... '''img1为一图像Image对象,net为使用的网络''' for obj in tf.classify(net, img1, min_scale=1.0, scale_mul=0.5, x_overlap=0.0, y_overlap=0.0): ...
为了防止对场地内图片以外的事物进行误判,加多一条进行图像识别的前提条件,即只有先找到图像中的矩形时才会进行图像识别,没有找到矩形时则不进行图像识别。由于场地上只存在图片一种矩形事物,便只会对图片进行图像识别。
在最初,我采用的矩形寻找方法是find_rects()
... for r in img.find_rects(threshold=4000): # 在图像中搜索矩形 if r.w()但后来发现这种寻找矩形的方法比较慢,严重降低了图片识别的效率。后来我了解到色块寻找函数find_blobs() 会返回的对象Blob,而通过读取Blob对象,可以获得图片的矩形框。这种寻找矩形框的方法很快,大大提高了图片识别的速度。
... for blobs in img.find_blobs([picture]): if blobs.h()3)通讯
地图识别和图片识别的结果都需要发送给控制车体运动的MCU,因此两个MCU间需要进行通讯。我们采用UART进行通讯。
识别地图得到的坐标列表经过一些处理后,包含包头。包尾、校验位一同发送。
list_changed = list_change(list_dir) # 将[(x,y),(x,y)...]坐标,转换为[x,y,x,y...]坐标 list_changed1 = bite_to_word(list_changed) # 将一个数稳定拆成两个字节数 checkbit = check_bit(list_changed)) baotou = [0xa5] uart.write(bytearray(baotou)) # 发送包头 uart.write(bytearray(list_changed1)) # 发送列表 uart.write(bytearray(checkbit)) # 发送校验位 baowei = [0x5a] uart.write(bytearray(baowei)) # 发送包尾
当车到达图片附近时,会给OpenArt发送标志位,此时OpenArt开始识别。当OpenArt发送完成后,等待下一个标志位。若另一片MCU没有收到OpenArt发来的结果,则会认为图片所处位置不适合识别,将会改变车身方向,再次等待OpenArt的识别结果,当超出一定时间未识别成功时,将会放弃该图片,前往下一个点。
总结
虽然我们基本完成了所有比赛项目,但是效果并不是十分理想。我们确实存在一些问题。其中有个问题是我们本可以避免的:我们使用的是前辈留下来的 H车模 ,虽然先前曾听说 M车模 的性能会比 H车模 好,但当时车速还不高,并没有充分感受到 M车模 的劣势,且 M车模 的价格确实不太怡人,所以我们仍然坚持用了 H车模 。后来便出现车模在较高速的情况下会打滑、车身振动大、难以全向行进等一些列问题。所以,能用金钱实现的提高,就别吝啬。
总体而言,此次智能车竞赛仍然是一次难得的经历。对智能车有兴趣的朋友都可以参加这个比赛,不仅可以提高一些专业能力,也能锻炼心态(特别是原本完赛的车在比赛前一天故障了)。
以上就是我在这次智能车比赛中的一些总结和思路,可能存在许多不成熟的看法,请多多包涵,也欢迎大家能帮我指出错误、评论区留言探讨。
谢谢观看。







