

- 大家好,我是同学小张,日常分享AI知识和实战案例
- 欢迎 点赞 + 关注 👏,持续学习,持续干货输出。
- +v: jasper_8017 一起交流💬,一起进步💪。
- 微信公众号也可搜【同学小张】 🙏
本站文章一览:
文章目录
- 0. 开篇
- 1. 基本RAG存在的问题
- 1.1 基本介绍
- 1.2 RAG的10大痛点总结
- 2. 优化方法
- 2.1 文档加载的准确性和效率
- 2.1.1 优化方法一:优化文档读取器
- 2.1.2 优化方法二:数据清洗与增强
- 2.2 文档切分的粒度
- 2.2.1 分块方法
- 2.2.1.1 固定大小的分块
- 2.2.1.2 内容重叠分块
- 2.2.1.3 段落分块
- 2.2.1.4 内容分块
- 2.2.1.5 递归分块
- 2.2.1.6 从小到大分块
- 2.2.1.7 特殊结构分块
- 2.2.2 分块大小的选择
- 2.3 内容缺失
- 2.3.1 优化方法一:让大模型说“No”
- 2.3.2 优化方法二:增加相应知识库
- 2.4 错过排名靠前的文档
- 2.4.1 优化方法一:增加召回数量(不推荐)
- 2.4.2 优化方法二:重排(Reranking)
- 2.5 提取上下文与答案无关
- 2.6 格式错误
- 2.6.1 优化方法一:优化Prompt
- 2.6.2 优化方法二:Pydantic方法
- 2.6.3 优化方法三:格式自修复
- 2.7 答案不完整
- 2.7.1 优化方法一:将问题分开提问
- 2.8 未提取到答案
- 2.8.1 优化方法一:提示压缩技术
- 2.8.2 优化方法二:上下文重排序
- 2.9 答案太具体或太笼统
- 2.10 安全性
- 3. 前沿优化方法
- 3.1 T-RAG
- 3.2 CRAG
- 3.3 Self-RAG
- 3.4 多步查询
- 3.5 Step-Back Prompting
- 3.6 混合检索
- 3.7 RAG-Fusion
- 3.8 Rewrite-Retrieve-Read RAG
- 3.9 其它RAG方法
- 4. 总结
- 参考
0. 开篇
我之前写过 RAG 的基本流程和实战(【AI大模型应用开发】3. RAG初探 - 动手实现一个最简单的RAG应用),里面介绍的是基本RAG的流水线。最后我也提到,要想实现比较好的RAG效果,还有很多工作需要做,落地很难。
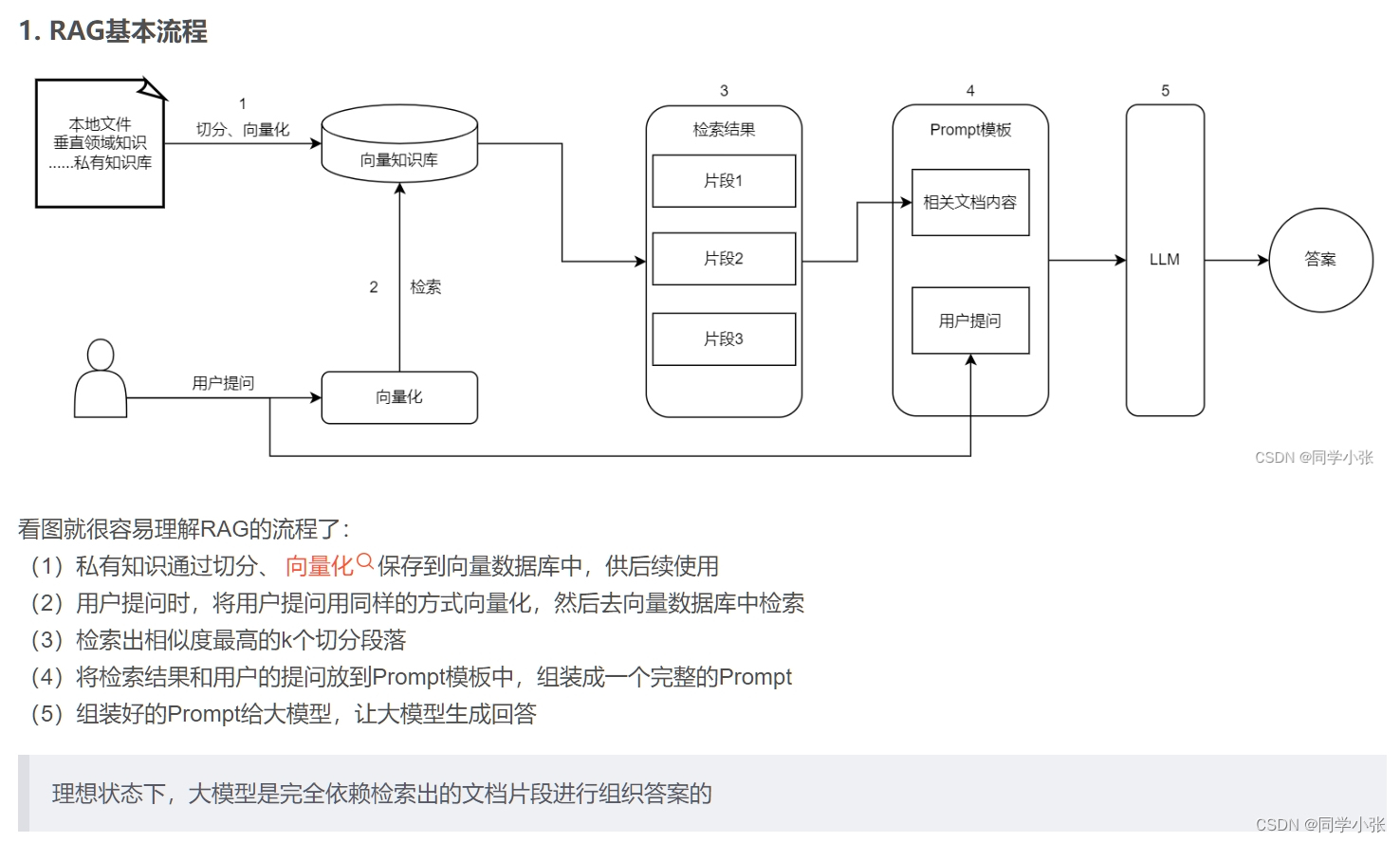

本文我们来概述一下当前基本RAG流程中存在的问题,以及目前常用的RAG效果优化方法。
1. 基本RAG存在的问题
1.1 基本介绍
以一篇专业的论文切入,让我们来看看当前RAG的基本框架存在哪些问题。
- 论文:《Seven Failure Points When Engineering a Retrieval Augmented Generation System》
主要在下面这张图,文中提出了当前RAG存在的7个痛点(问题):
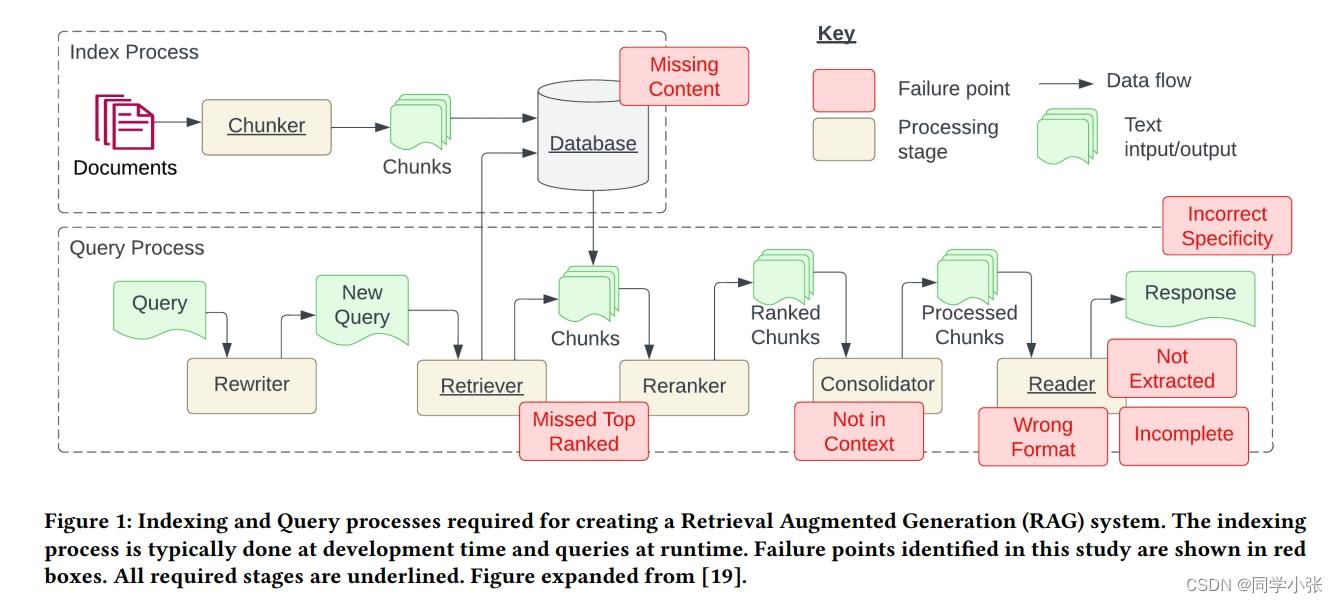
理解下图中的信息:
- 基本RAG流程可以分为两大块:文本向量化构建索引的过程(Index Process)和 检索增强问答的过程(Query Process)。
在文本向量化构建索引的过程中,可能的缺陷如下:
- 内容缺失:原本的文本中就没有问题的答案
在检索增强回答的过程中,可能的缺陷如下:
- 错过排名靠前的文档
- 提取上下文与答案无关
- 格式错误:例如需要Json,给了字符串
- 答案不完整:答案只回答了问题的一部分
- 未提取到答案:提取的上下文中有答案,但大模型没有提取出来
- 答案不够具体或过于具体
其实,除了这7个痛点,我觉得在文本向量化构建索引的过程中,还有另两个问题没有指出:
- 文档加载准确性和效率:比如pdf文件的加载,如何提取其中的有用文字信息和图片信息等
- 文档切分的粒度:文本切分的大小和位置会影响后面检索出来的上下文完整性和与大模型交互的token数量,怎么控制好文档切分的度,是个难题
当然如果这是个真实的应用,还应考虑安全性。
1.2 RAG的10大痛点总结
好了,总结下我认为的RAG流程存在的问题(痛点),一共10个:
-
文本向量化构建索引的过程
- (1)文档加载准确性和效率
- (2)文档切分的粒度
- (3)内容缺失
-
检索增强回答的过程
- (4)错过排名靠前的文档
- (5)提取上下文与答案无关
- (6)格式错误
- (7)答案不完整
- (8)未提取到答案
- (9)答案不够具体或过于具体
-
其它
- (10)安全性
下面我们来针对每一个痛点问题,看下目前有哪些解决或优化方法。
2. 优化方法
2.1 文档加载的准确性和效率
文本的准确性和清洁性是RAG系统能有好的效果的前提。
2.1.1 优化方法一:优化文档读取器
一般知识库中的文档格式都不尽相同,HTML、PDF、Markdown、TXT、CSV等。每种格式文档都有其都有的数据组织方式。怎么在读取这些数据时将干扰项去除(如一些特殊符号等),同时还保留原文本之间的关联关系(如csv文件保留其原有的表格结构),是主要的优化方向。
目前针对这方面的探索为:针对每一类文档,涉及一个专门的读取器。如LangChain中提供的WebBaseLoader专门用来加载HTML文本等。
2.1.2 优化方法二:数据清洗与增强
(1)去除特殊字符和不相关信息。除重复文档或冗余信息。
(2)实体解析:消除实体和术语的歧义以实现一致的引用。例如,将“LLM”、“大语言模型”和“大模型”标准化为通用术语。
(3)数据增强:使用同义词、释义甚至其他语言的翻译来增加语料库的多样性。
(4)用户反馈循环:基于现实世界用户的反馈不断更新数据库,标记它们的真实性。
(5)时间敏感数据:对于经常更新的主题,实施一种机制来使过时的文档失效或更新。
2.2 文档切分的粒度
粒度太大可能导致检索到的文本包含太多不相关的信息,降低检索准确性,粒度太小可能导致信息不全面,导致答案的片面性。
问题的答案可能跨越两个甚至多个片段
切分原则:确保信息的完整性和相关性。一般来说,理想的文本块应当在没有周围上下文的情况下对人类来说仍然有意义,这样对语言模型来说也是有意义的。
2.2.1 分块方法
2.2.1.1 固定大小的分块
这是最简单和直接的方法,我们直接设定块中的字数,每个文本块有多少字。
简单 但 死板,一般不推荐。
2.2.1.2 内容重叠分块
在固定大小分块的基础上,为了保持文本块之间语义上下文的连贯性,在分块时,保持文本块之间有一定的内容重叠。
还记得我们在学习LangChain的数据连接模块时用的RecursiveCharacterTextSplitter吗?里面的chunk_size参数就是固定的字数,chunk_overlap参数就是两个相邻文本块之间重叠的字数。
text_splitter = RecursiveCharacterTextSplitter( chunk_size=200, chunk_overlap=100, length_function=len, add_start_index=True, )2.2.1.3 段落分块
顾名思义,按段落分块 - 我在 【AI大模型应用开发】3. RAG初探 - 动手实现一个最简单的RAG应用 这篇文章中用的分块方法。
这种分块方法也比较简单。对于段落间关系不大,段落语义较独立的文档分割比较实用。
2.2.1.4 内容分块
根据文档的具体内容进行分块,例如根据标点符号(如句号)分割。或者直接使用更高级的 NLTK 或者 spaCy 库提供的句子分割功能。
2.2.1.5 递归分块
重复的利用分块规则不断细分文本块。例如,在langchain中会先通过段落换行符(\n\n)进行分割。然后,检查这些块的大小。如果大小不超过一定阈值,则该块被保留。对于大小超过标准的块,使用单换行符(\n)再次分割。以此类推,不断根据块大小更新更小的分块规则(如空格,句号)。
这种方法可以灵活地调整块的大小。例如,对于文本中的密集信息部分,可能需要更细的分割来捕捉细节;而对于信息较少的部分,则可以使用更大的块。而它的挑战在于,需要制定精细的规则来决定何时和如何分割文本。
2.2.1.6 从小到大分块
将文档按不同大小尺寸全部分割一遍存储,例如文档A先按100字数分,再按50字数分。100字数分割块和50字数分割块全部存入向量数据库。同时保存每个分块的上下级关系,进行递归搜索。
重复存储、浪费空间
2.2.1.7 特殊结构分块
针对特定结构化内容的专门分割器。这些分割器特别设计来处理这些类型的文档,以确保正确地保留和理解其结构。langchain提供的特殊分割器包括:Markdown文件,Latex文件,以及各种主流代码语言分割器。
2.2.2 分块大小的选择
(1)不同的嵌入模型有其最佳输入大小。比如Openai的text-embedding-ada-002的模型在256 或 512大小的块上效果更好。
(2)文档的类型和用户查询的长度及复杂性也是决定分块大小的重要因素。处理长篇文章或书籍时,较大的分块有助于保留更多的上下文和主题连贯性;而对于社交媒体帖子,较小的分块可能更适合捕捉每个帖子的精确语义。如果用户的查询通常是简短和具体的,较小的分块可能更为合适;相反,如果查询较为复杂,可能需要更大的分块。
实际场景中,我们可能还是需要不断实验调整,在一些测试中,128大小的分块往往是最佳选择,在无从下手时,可以从这个大小作为起点进行测试。
2.3 内容缺失
准备的外挂文本中没有回答问题所需的知识。这时候,RAG可能会提供一个自己编造的答案。
2.3.1 优化方法一:让大模型说“No”
通过Prompts,让大模型在找不到答案的情况下,输出“根据当前知识库,无法回答该问题”等提示。如下面这个Prompt中的如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。:
prompt_template = """ 你是一个问答机器人。 你的任务是根据下述给定的已知信息回答用户问题。 确保你的回复完全依据下述已知信息。不要编造答案。 如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。 已知信息: __INFO__ 用户问: __QUERY__ 请用中文回答用户问题。
2.3.2 优化方法二:增加相应知识库
将相应的知识文本加入到向量知识库中。
2.4 错过排名靠前的文档
外挂知识库中存在回答问题所需的知识,但是可能这个知识块与问题的向量相似度排名并不是靠前的,导致无法召回该知识块传给大模型,导致大模型始终无法得到正确的答案。
2.4.1 优化方法一:增加召回数量(不推荐)
增加召回的 topK 数量,也就是说,例如原来召回前3个知识块,修改为召回前5个知识块。不推荐此种方法,因为知识块多了,不光会增加token消耗,也会增加大模型回答问题的干扰。
2.4.2 优化方法二:重排(Reranking)
该方法的步骤是,首先检索出 topN 个知识块(N > K,过召回),然后再对这 topN 个知识块进行重排序,取重排序后的 K 个知识块当作上下文。重排是利用另一个排序模型或排序策略,对知识块和问题之间进行关系计算与排序。
2.5 提取上下文与答案无关
这个其实是【内容缺失】 或者 【错过排名靠前的文档】的具体体现。优化方法参考这两种问题的处理即可。
2.6 格式错误
例如我们想要大模型返回一个Json,它确返回了一个字符串
2.6.1 优化方法一:优化Prompt
优化Prompt逐渐让大模型返回正确的格式。例如给例子等。
2.6.2 优化方法二:Pydantic方法
使用Pydantic进行结果格式验证,例如使用LangChain中的PydanticOutputParser类来校验输出格式。
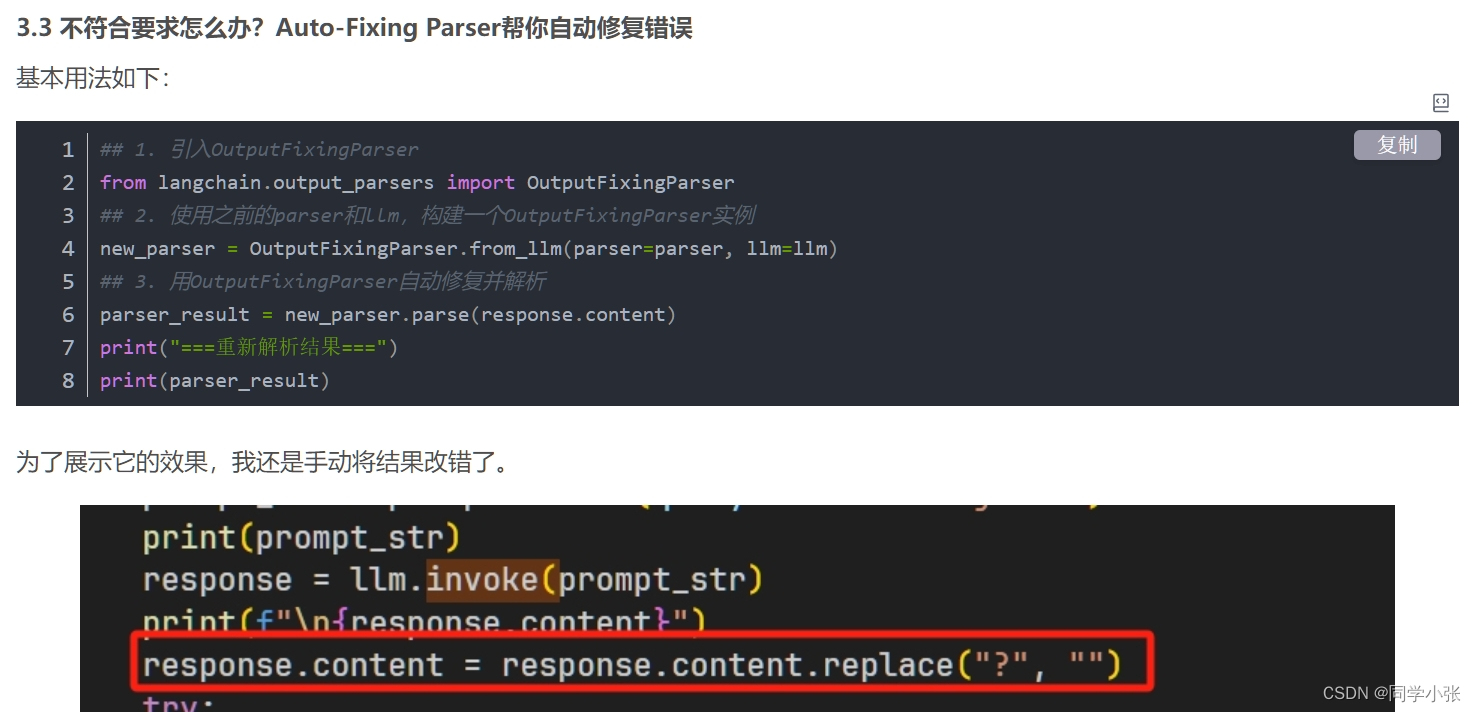
2.6.3 优化方法三:格式自修复
前面我们也用过,利用 Auto-Fixing Parser 帮你自动修复错误
2.7 答案不完整
一种情况是一次提问多个问题,可能只会得到其中部分问题的答案。
例如问“A的概念是什么,它有什么作用,它的使用方式是什么”。这三个问题可能分布于不同的知识块中。检索可能只能检索到部分上下文,大模型可能只能提取到部分问题的答案,这些综合作用,就导致了效果不好。
2.7.1 优化方法一:将问题分开提问
一方面引导用户精简问题,一次只提问一个问题。
另一方面,针对用户的问题进行内部拆分处理,拆分成数个子问题,等子问题答案都找到后,再总结起来回复给用户
2.8 未提取到答案
当上下文中存在太多噪音或相互矛盾的信息时,或者提示词不好,大模型能力不足时,即使上下文中有答案,大模型也可能无法找出来
2.8.1 优化方法一:提示压缩技术
在检索到上下文之后进行压缩处理,然后再输入给LLM。参考:https://mp.weixin.qq.com/s/61LZgc1a5yRP2J7MTIVZ4Q
2.8.2 优化方法二:上下文重排序
有研究表明,大模型对输入数据的开头和结尾比较敏感,因此尽量的让关键的信息出现在提示的开头和结尾。
2.9 答案太具体或太笼统
答复可能缺乏必要的细节或具体性,通常需要后续询问才能澄清。答案可能过于模糊或笼统,无法有效满足用户的需求。
我们可以用高级检索策略来解决此类问题。比如用从小到大检索,句子窗口检索,递归检索等方法。待研究…
2.10 安全性
对抗提示注入,处理不安全的输出,防止敏感信息的泄露。
之前的文章中讨论过:【AI大模型应用开发】1.3 Prompt攻防(安全) 和 Prompt逆向工程
3. 前沿优化方法
除了以上相对比较简单和直接的优化方式,这里也给大家搜集了一些当前比较前沿的优化方法研究进展。
3.1 T-RAG
T-RAG(Tree-RAG):T-RAG: LESSONS FROM THE LLM TRENCHES
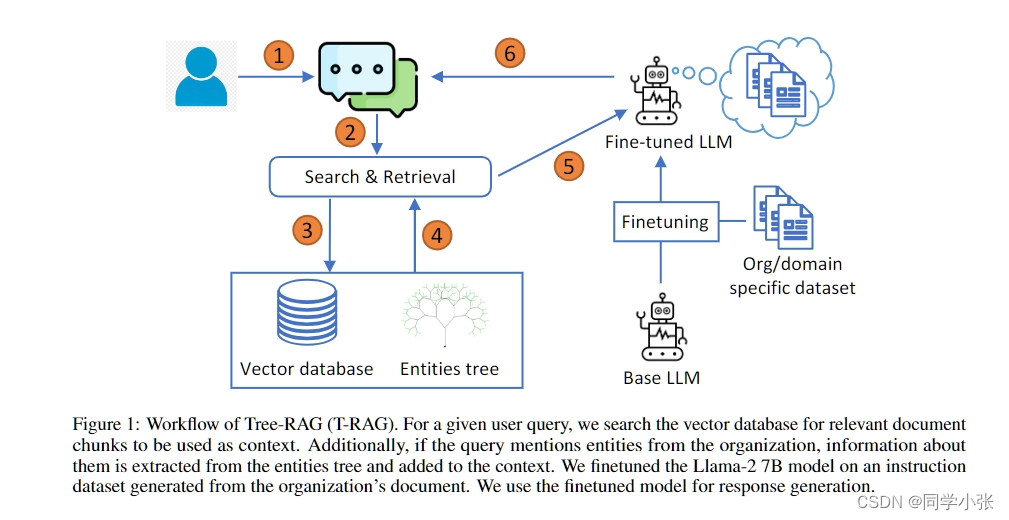
该方法的创新点在于,其将企业中的实体信息构造成了树结构。在利用RAG检索回来相关上下文之后,如果原始问题中存在实体信息,则会再去实体树中查找相应的实体信息,补充到上下文中。一般在企业中,各个项目或方向都会有自己的一些专用术语,构建这样一棵实体树,能够帮助大模型更好地理解问题,不会去瞎猜相关的概念。
3.2 CRAG
CRAG(Corrective RAG):Corrective Retrieval Augmented Generation
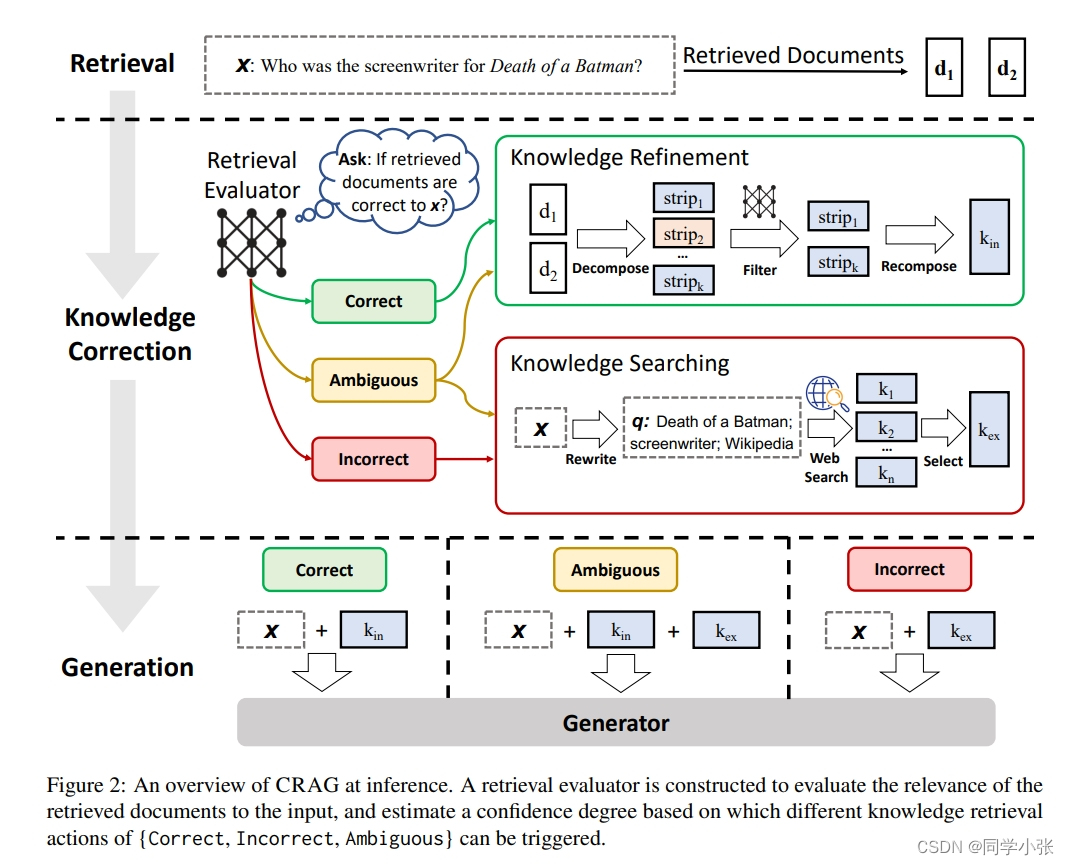
其核心思想是:检索到相关文档后,使用 LLMs 进行评估,分类三类 Correct、Incorrect、Ambiguous。将 Correct 文档传递给 LLM 以生成基于检索上下文的答案。对于Incorrect的文档,使用 Web 的文档检索以补充上下文传递给 LLM 用以生成答案。对于Ambiguous的文档,原文和通过Web检索补充的信息都传递给 LLMs 来生成答案。
3.3 Self-RAG
Self-RAG(Self-Reflective RAG):SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION
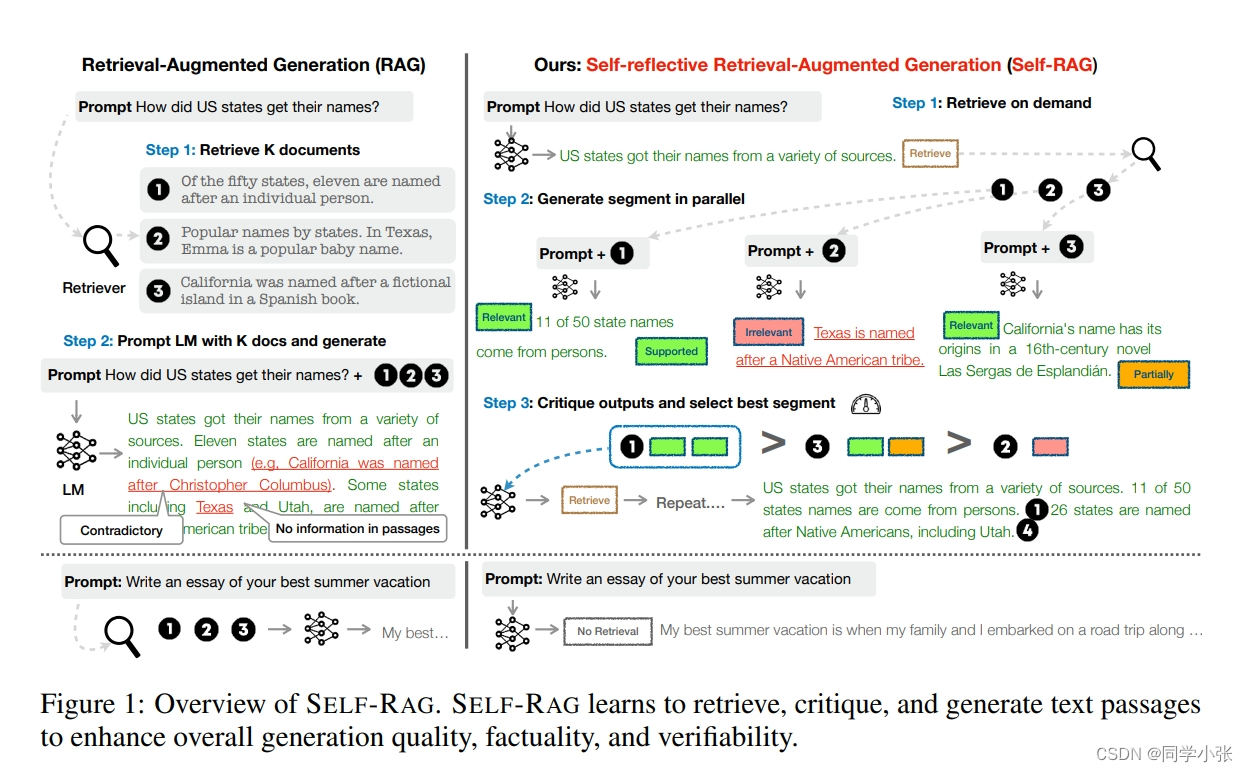
其主要步骤如下:
(1)判断是否需要额外检索事实性信息(retrieve on demand),仅当有需要时才召回
(2)处理每个片段:生产 prompt + 一个片段 的生成结果
(3)使用反思字段,检查输出是否相关,选择最符合需要的片段;
(4)再重复检索
(5)生成结果会引用相关片段,以及输出结果是否符合该片段,便于查证事实。
Self-RAG 的一个重要创新是 Reflection tokens (反思字符):通过生成反思字符这一特殊标记来检查输出。这些字符会分为 Retrieve 和 Critique 两种类型,会标示:检查是否有检索的必要,完成检索后检查输出的相关性、完整性、检索片段是否支持输出的观点。模型会基于原有词库和反思字段来生成下一个 token。
3.4 多步查询
Langchain Multi Query Retriever
3.5 Step-Back Prompting
TAKE A STEP BACK: EVOKING REASONING VIA ABSTRACTION IN LARGE LANGUAGE MODELS
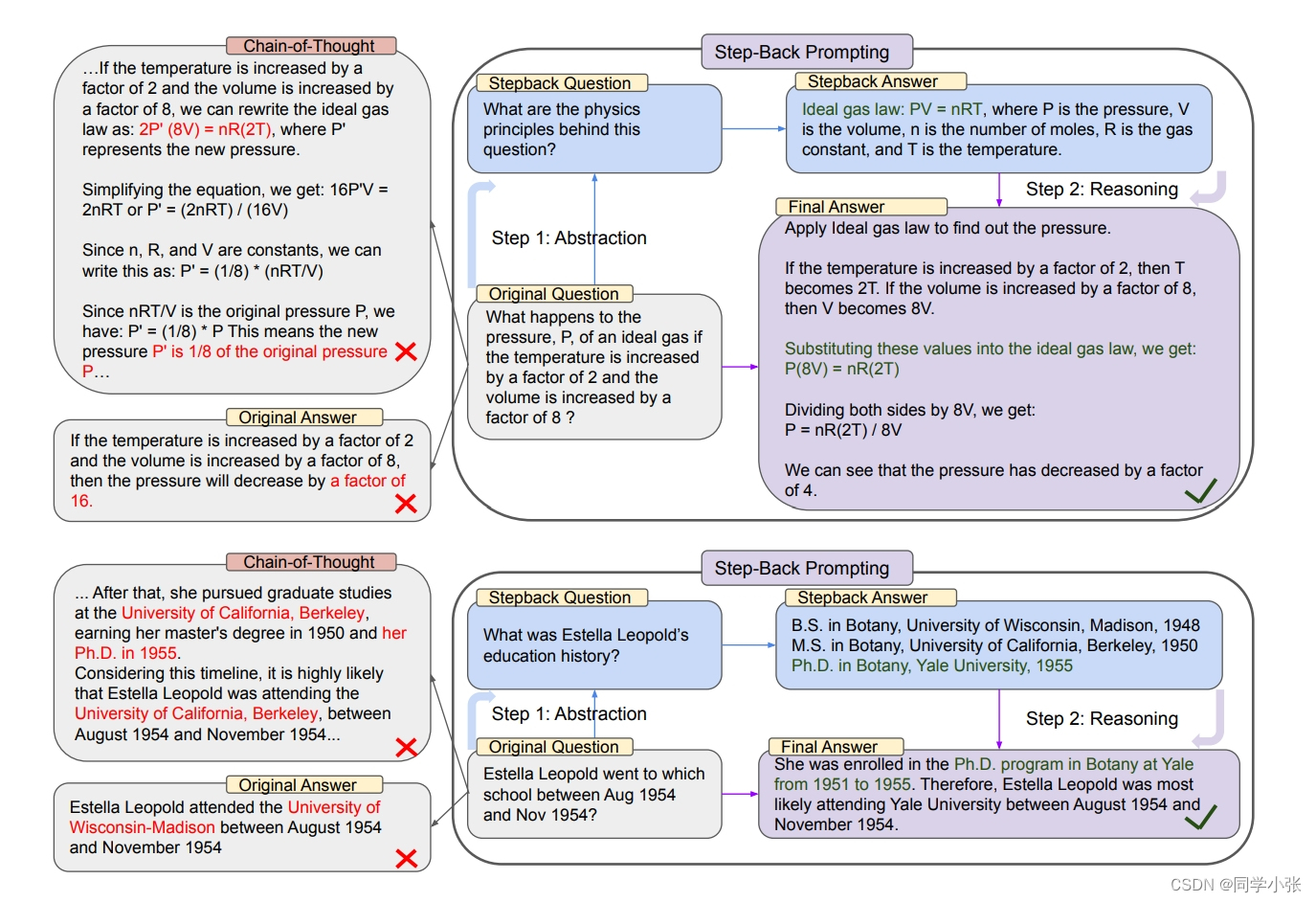
该论文提出了一种Prompt自动优化方法,使用LLM对用户提问进行抽象,从中提取出包含特定细节的高级概念和第一原理。使用这些概念和原则来指导推理步骤。具体可以看下上图中的例子,它的StepBack问题是:这个问题背后的物理原理是什么。先回答这个StepBack问题,知道了背后的原理后,再用这个原理指导最终答案的生成。
3.6 混合检索
不止使用向量检索,再加上传统检索手段等,以提高检索结果的准确性
3.7 RAG-Fusion
原始项目:https://github.com/Raudaschl/rag-fusion
参考:https://mp.weixin.qq.com/s/hxukMEeMzTEOVqd1P1fQLQ
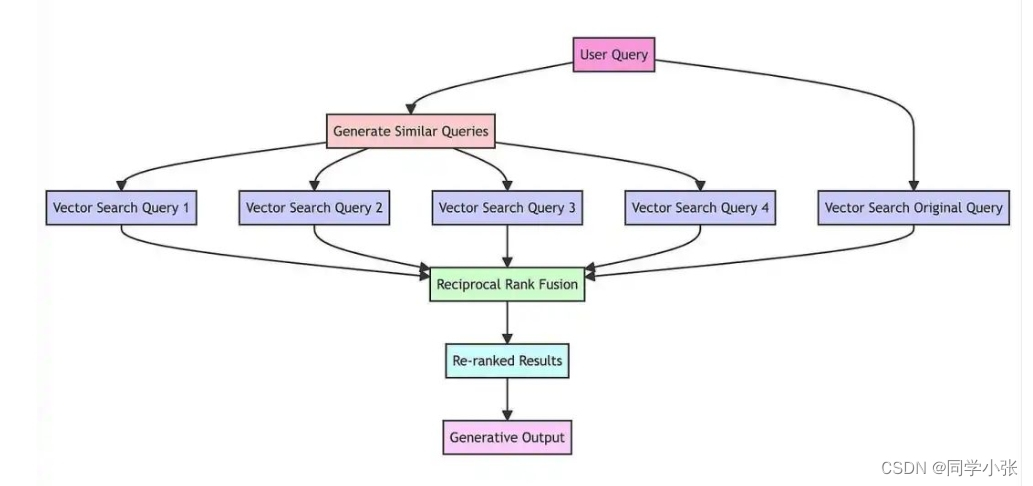
RAG Fusion在传统RAG技术的基础上:
(1)通过LLM将用户的查询翻译成相似但不同的查询。
(2)对原始查询及其生成的类似查询进行向量搜索,实现多个查询生成。
(3)使用RRF结合和精炼所有查询结果。
(4)选择新查询的所有顶部结果,为LLM提供足够的材料,以考虑所有查询和重排的结果列表来创建输出响应。
3.8 Rewrite-Retrieve-Read RAG
Query Rewriting for Retrieval-Augmented Large Language Models
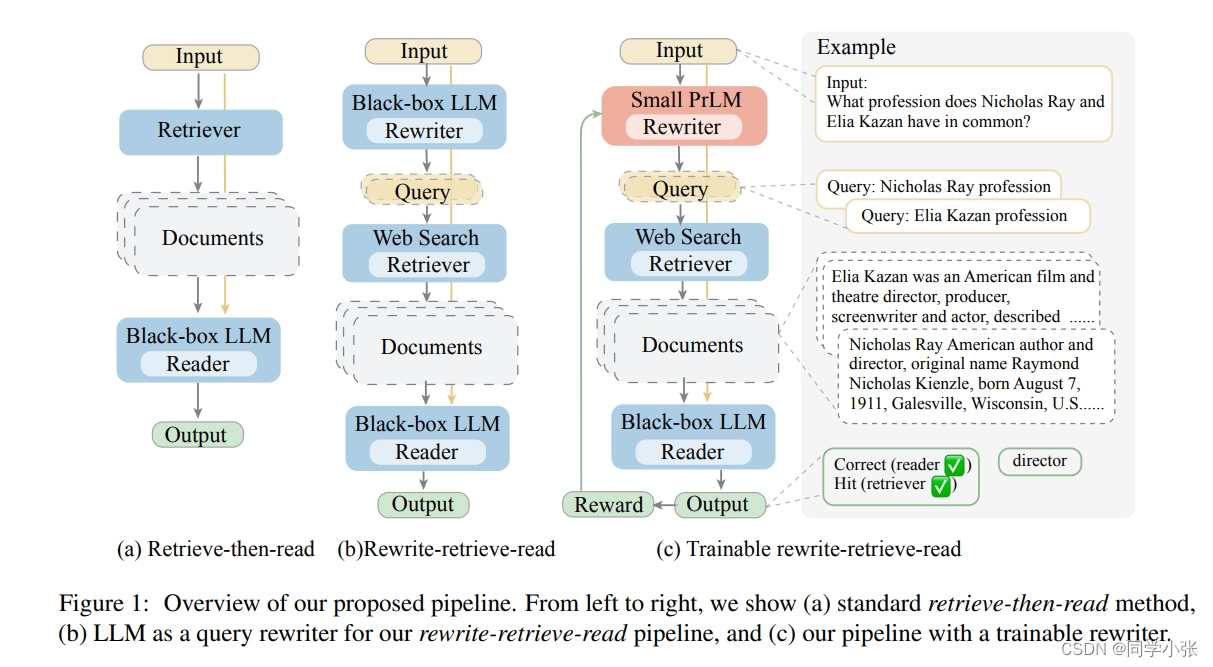
该方法旨在解决现有方法中输入文本与真正需要查询的知识之间的差距问题。该框架在检索器之前添加了一个重写步骤,以填补给定输入和检索需求之间的差距。与之前的研究相比,其动机是澄清输入文本的检索需求,而不是依赖于多次交互轮次来获取每个样本的正确答案。重写器是一个小的、可训练的语言模型。
3.9 其它RAG方法
其它先进的RAG方法,欢迎评论区补充…
4. 总结
本文我们从RAG的流水线开始,全面梳理了当前传统RAG存在的问题,同时针对每个问题,总结了几个优化方法。并且,整理了当前一些前沿的RAG优化方法研究。
本文是对这些方法的综述,旨在为读者提供优化思路或方向指导。欢迎评论区补充更多问题和解决方法!
参考
- https://mp.weixin.qq.com/s/9DSRIA9BjhMVHOTvsUfyAg
- https://mp.weixin.qq.com/s/_4Q7MS7E0RyMiE4_cRXKtA
- 其它参考文献见文章中的链接
如果觉得本文对你有帮助,麻烦点个赞和关注呗 ~~~
- 大家好,我是同学小张,日常分享AI知识和实战案例
- 欢迎 点赞 + 关注 👏,持续学习,持续干货输出。
- +v: jasper_8017 一起交流💬,一起进步💪。
- 微信公众号也可搜【同学小张】 🙏
本站文章一览:
- (10)安全性
-
- 内容缺失:原本的文本中就没有问题的答案
- 基本RAG流程可以分为两大块:文本向量化构建索引的过程(Index Process)和 检索增强问答的过程(Query Process)。
- 论文:《Seven Failure Points When Engineering a Retrieval Augmented Generation System》







