

文章目录
- MySQL
- 表的增删查改
- 1. Create(创建)
- 1.1 单行插入
- 1.2 多行插入
- 1.3 替换
- 2. Retrieve(读取)
- 2.1 select查看
- 2.2 where条件
- 2.3 结果排序
- 2.4 筛选分页结果
- 3. Update(更新)
- 3.1 更新单个数据
- 3.2 更新多个数据
- 4. Delete(删除)
- 其他补充:
MySQL

表的增删查改
CURD是一个数据库技术中的缩写词,它代表Create(创建),Retrieve(读取),Update(更新),Delete(删除)操作。这四个基本操作是数据库管理的基础,用于处理数据的基本原子操作。
1. Create(创建)
在MySQL中,Create操作是十分重要的,它帮助用于创建数据库对象,如数据库、表、索引等并且允许用户定义新的数据结构和存储方式。我们常使用create databases [库名]; 创建数据库,create table [表名]; 创建数据表,insert into [表名] values(数据); 创建单条数据。
1.1 单行插入
insert 语句在 MySQL 中用于向数据库表中插入新的记录。
insert into 表名 (列1, 列2, 列3, ...) values(值1, 值2, 值3, ...);
如果你想要为表中的每一列都插入值(即列的顺序与表中的定义一致),我们直接省略列名:
insert into 表名 values(值1, 值2, 值3, ...);
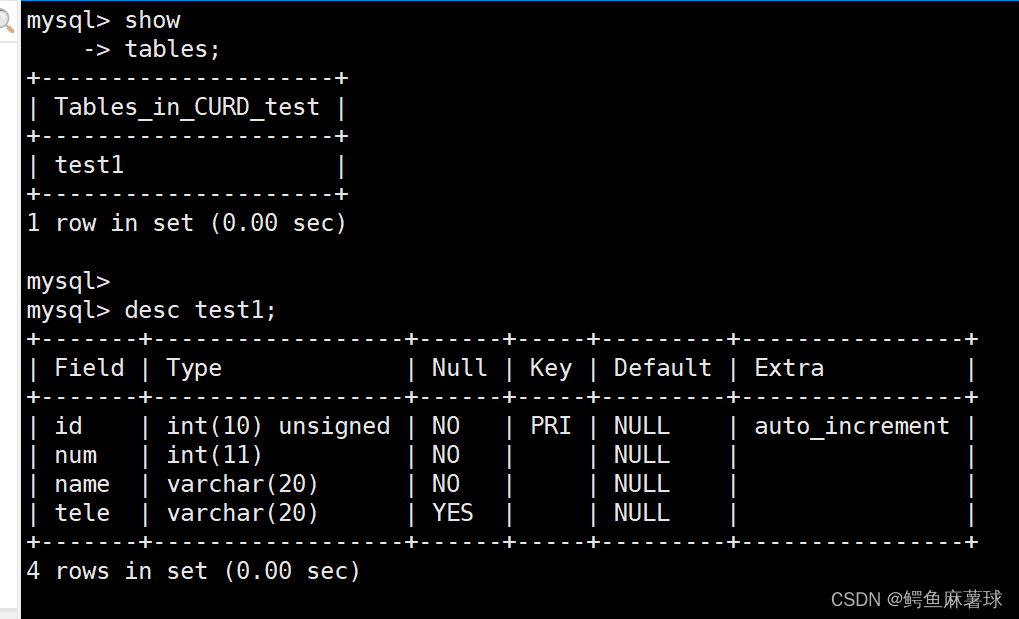
创建一张学生数据表,包括学号,姓名,电话等基本信息:
mysql> create table test1( -> id int unsigned primary key auto_increment, -> num int not null, -> name varchar(20) not null, -> tele varchar(20) -> );对于上面的表中,id代表学号,每一个学生有且只有唯一的一个,所以我们设计为主键,同时设置为自增长,下面的num和name设置为不为空类型。
查看表的结构:
desc test1;
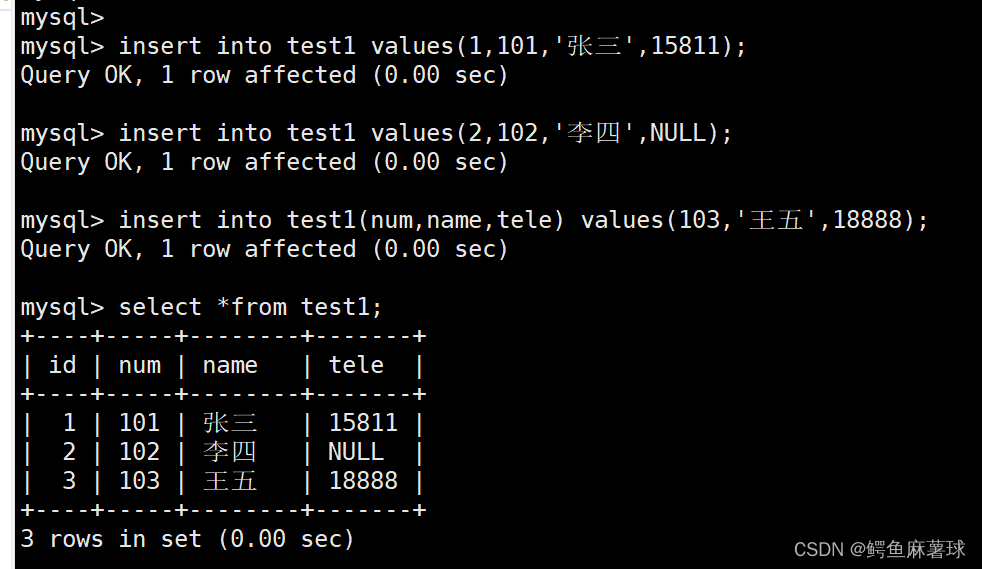
连续插入三个单条数据并且打印查看:
mysql> insert into test1 values(1,101,'张三',15811); mysql> insert into test1 values(2,102,'李四',NULL); mysql> insert into test1(num,name,tele) values(103,'王五',18888);
select * from test1;
1.2 多行插入
insert语句可以一次性插入多行数据。通常我们只需要在values子句中列出多组值来实现的,每组值之间用逗号分隔。
insert多行插入并且打印:
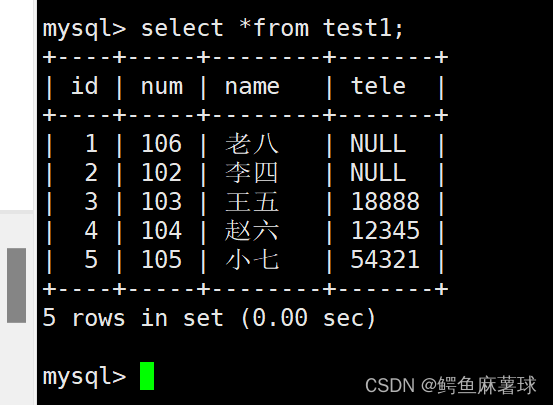
mysql> insert into test1 (num,name,tele) values -> (104,'赵六',12345), -> (105,'小七',54321);select *from test1;
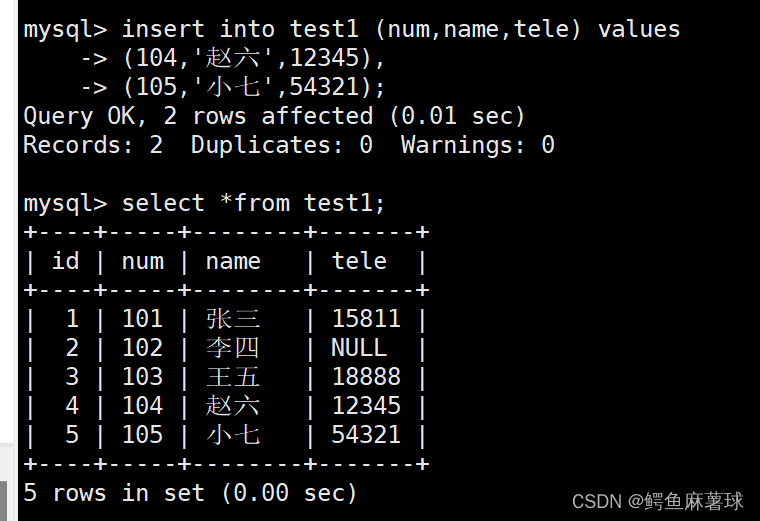
确保我们插入的数据和列的数据匹配,如果列中not null,我们需要提供值,除非有默认值,我们要注意由于插入的数据是否会因为主键或者唯一键对应的值已经存在而导致插入失败。
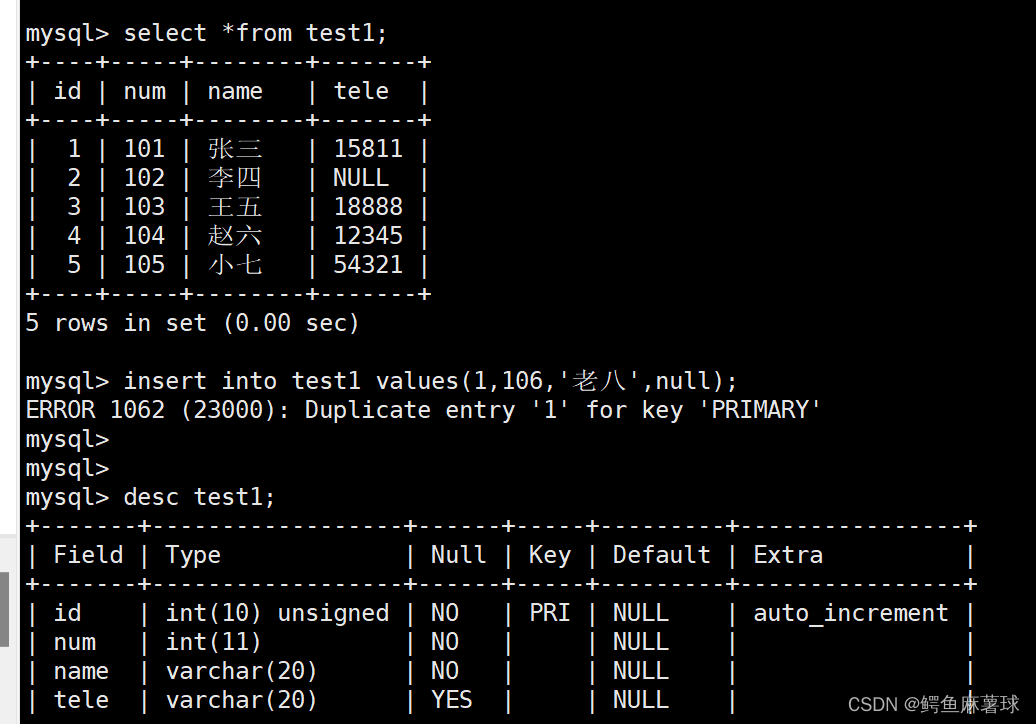
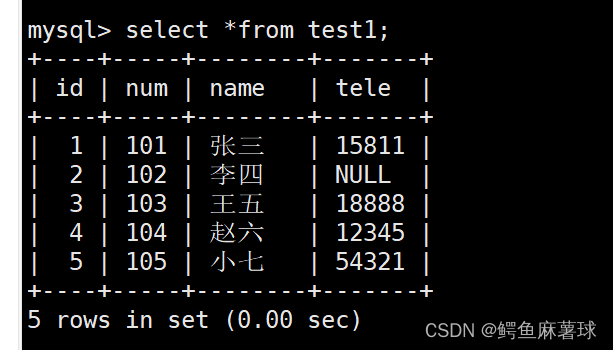
对应主键已经有唯一值导致插入失败:
mysql> insert into test1 values(1,106,'老八',null); ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'
1.3 替换
replace 语句在 SQL 中是一个特殊的语句,它结合了 insert 和 update 的功能。既可以插入数据也可以替换数据。
插入数据:如果 replace 语句中指定的数据在表中不存在,它会执行一个插入操作,将数据添加到表中。
替换数据:如果数据已经存在于表中(通常是因为主键或唯一键冲突),replace 语句会先删除原有的数据行,然后插入新的数据行。
replace into 表名 (列1, 列2, 列3, ...) values(值1, 值2, 值3, ...);
总而言之:主键或者唯一键没有冲突,则直接插入;主键或者唯一键如果冲突,则删除后再插入。
替换原有的主键数据并插入新的数据:
mysql> replace into test1 values(1,106,'老八',null);

2. Retrieve(读取)
Retrieve操作在数据库应用中主要用于从数据窗口或数据存储(Datastore)中检索数据。常用的有select进行数据的显示,或者其他如where等进行数据的筛选。
2.1 select查看
SELECT是SQL语言中的一个核心命令,用于从数据库表中检索数据。
[distinct]{* | {column[,column]...} [from table_name] [where...] [order BY column[ASC|DESC],...] limit...distinct:这个关键字用于去重。
* 或 {column[,column]…}:这部分指定了要检索的列。* 表示选择所有列,而 {column[,column]…} 则允许您指定一个或多个列名。
from table_name:这部分指定了要从哪个表中检索数据。
where…:这是一个可选的子句,用于过滤结果集,只返回满足指定条件的行。
order BY column[ASC|DESC],…:这部分用于对结果集进行排序。 您可以指定一个或多个列,以及排序的方向(升序 ASC 或降序 DESC)。
limit…:这个子句用于限制返回的记录数。 它通常与分页查询一起使用。
创建学生成绩表:
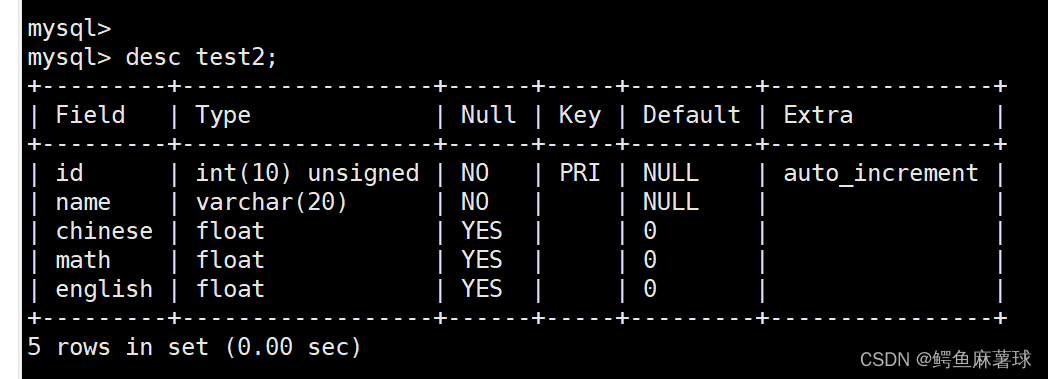
mysql> create table test2( -> id int unsigned primary key auto_increment, -> name varchar(20) not null, -> chinese float default 0.0 comment '语文成绩', -> math float default 0.0 comment '数学成绩', -> english float default 0.0 comment '英语成绩' -> );查看表结构:
desc test2;
向表中插入数据并且打印:
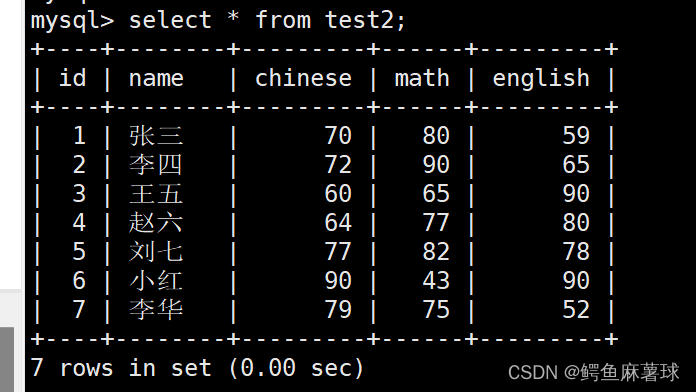
mysql> insert into test2(name,chinese,math,english) values -> ('张三',70,80,59), -> ('李四',72,90,65), -> ('王五',60,65,90), -> ('赵六',64,77,80), -> ('刘七',77,82,78), -> ('小红',90,43,90), -> ('李华',79,75,52);通常情况下不建议使用 * 进行全列查询,查询的列越多,意味着需要传输的数据量越大;可能会影响到索引的使用。
select * from test2;
指定列打印信息(id,name,chinese):
select id,name,chinese from test2;

打印的字段可以是一个表达式:
select id,name,chinese+math+english from test2;
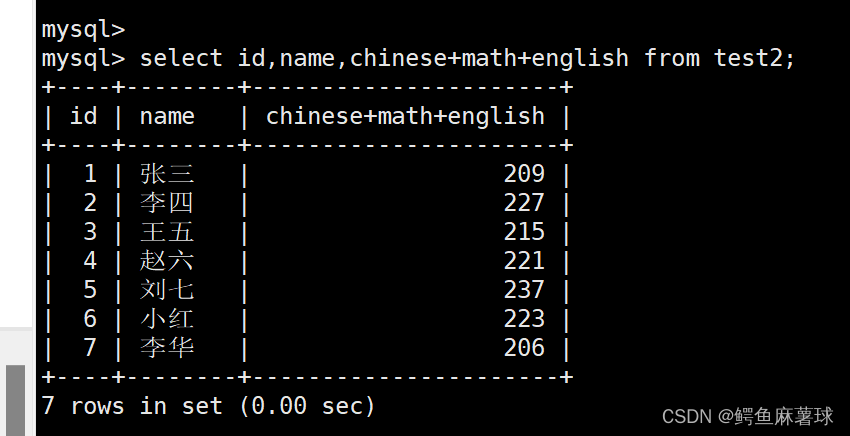
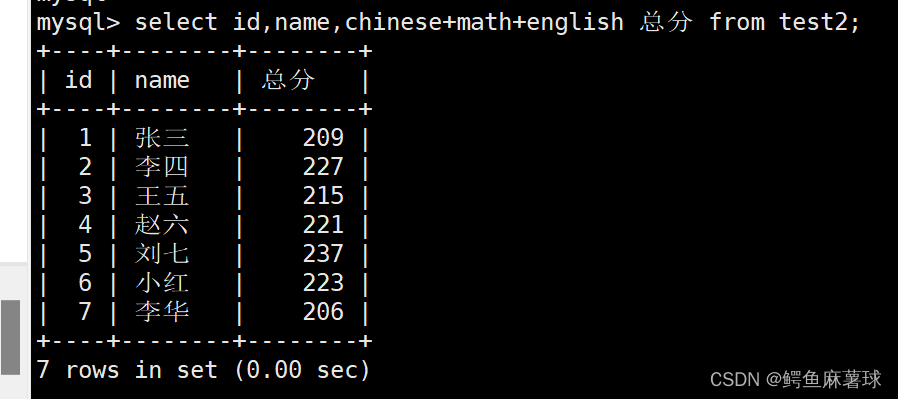
给打印字段的表达式重新命名:
select id,name,chinese+math+english 总分 from test2;
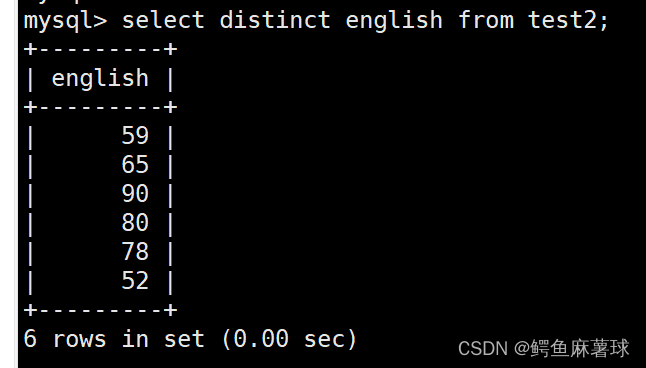
将打印出来的英文成绩去重:
select distinct english from test2;
2.2 where条件
在MySQL的select语句中,where子句用于指定查询条件,只有满足这些条件的记录才会出现在结果集中。where子句的主要目的是从数据表或查询结果中过滤出符合条件的行。
where子句后面可以跟随一个或多个条件,这些条件可以是算术表达式、逻辑表达式或比较运算符的组合。
比较运算符:
运算符 说明 = 大于,大于等于,小于,小于等于 = 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL 等于,NULL 安全,例如 NULL NULL 的结果是 TRUE(1) !=, 不等于 between a0 and a1 范围匹配,[a0, a1],如果 a0
- 其他补充:







