

AI竞赛1-Xgboost算法之京东用户购买意向预测
- 1.项目流程
- 1.1 数据清洗
- 1.2 数据探查
- 1.3 特征提取
- 1.4 模型建立
- 2.项目背景
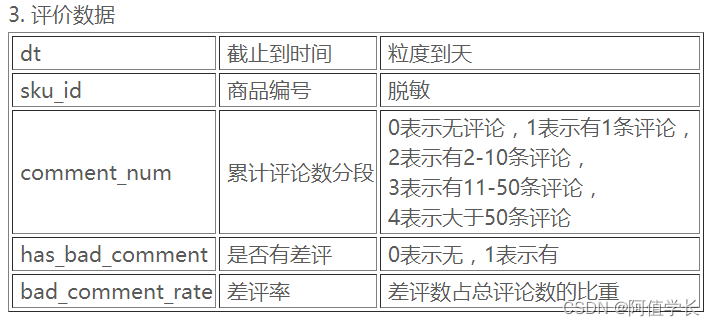
- 3.数据概述
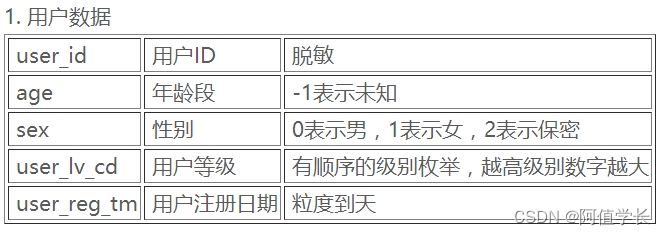
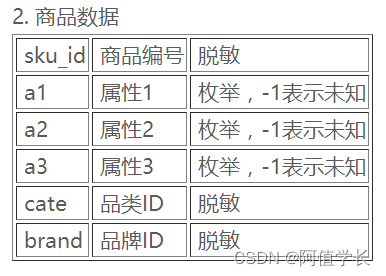
- 3.1 京东用户数据集
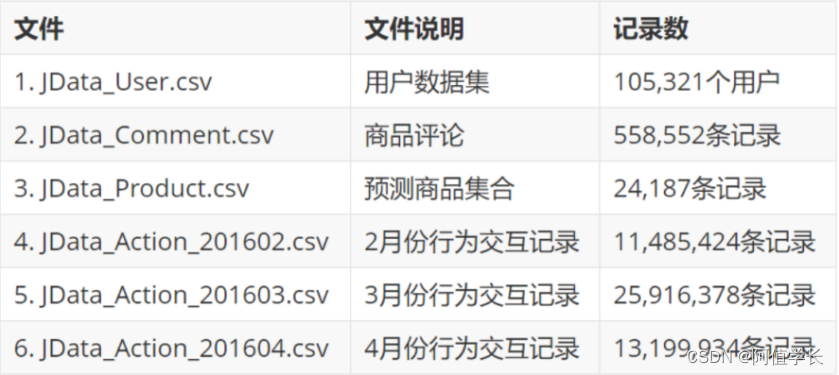
- 3.2 数据集记录数
- 4.数据预处理
- 4.1 用户一致性检验
- 4.2 检查数据是否重复
- 4.3 构建user_table
- 5. 数据清洗
- 5.1 用户整体性查看
- 5.2 删除没有age、sex字段的用户
- 5.3 删除无交互记录的用户
- 5.4 统计并删除无购买记录的用户
- 5.5 删除爬虫及惰性用户
- 5.6 数据查看与保存
- 6.数据探查
- 6.1 定义文件变量
- 6.2 周一到周日每天购买情况
- 6.3 一个月中每天购买量
- 6.3.1 2016年2月份
- 6.3.2 2016年3月份
- 6.3.3 2016年4月份
- 6.4 周一到周日各商品类别销售情况
- 6.5 每月商品销售情况 (只关注商品8)
- 6.6 查看特定用户对特定商品的消费轨迹
- 7.数据加载
- 7.1 变量声明
- 7.2 数据加载函数
- 8.特征工程
- 8.1 特征工程概念
- 8.2 用户特征
- 8.3 商品特征
- 8.4 评论特征
- 8.5 行为特征
- 8.6 累积用户特征
- 8.7 用户近期行为特征
- 8.8 用户对大类商品交互行为特征
- 8.9 累积商品特征
- 8.10 类别特征
- 9.训练集/测试集创建
- 9.1 数据查看
- 9.2 训练集创建
- 9.3 测试集创建
- 10.Xgboost 模型
- 10.1 模型导入
- 10.2 数据加载
- 10.3 Xgboost建模
- 10.4 特征重要性
- 10.5 算法预测验证数据
- 10.6 验证集模型评估
- 10.7 测试数据
- 10.8 测试集模型评估
1.项目流程
1.1 数据清洗
- (1) 数据集完整性验证
- (2) 数据集中是否存在缺失值
- (3) 数据集中各特征数值应该如何处理
- (4) 哪些数据是我们想要的,哪些是可以过滤掉的
- (5) 将有价值数据信息做成新的数据源
- (6) 去除无行为交互的商品和用户
- (7) 去掉浏览量很大而购买量很少的用户(惰性用户或爬虫用户)
1.2 数据探查
- (1) 掌握各个特征的含义
- (2) 观察数据有哪些特点,是否可利用来建模
- (3) 可视化展示便于分析
- (4) 用户的购买意向是否随着时间等因素变化
1.3 特征提取
- (1) 基于清洗后的数据集哪些特征是有价值
- (2) 分别对用户与商品以及其之间构成的行为进行特征提取
- (3) 行为因素中哪些是核心?如何提取?
- (4) 瞬时行为特征or累计行为特征?
1.4 模型建立
- (1) 使用机器学习算法进行预测
- (2) 参数设置与调节
- (3) 数据集切分
2.项目背景
- 京东作为中国最大的自营式电商,在保持高速发展的同时,沉淀了数亿的忠实用户,积累了海量的真实数据。如何从历史数据中找出规律,去预测用户未来的购买需求,让最合适的商品遇见最需要的人,是机器学习应用在精准营销中的关键问题,也是所有电商平台在做智能化升级时所需要的核心技术。以京东商城真实的用户、商品和行为数据(脱敏后)为基础,通过数据挖掘的技术和机器学习的算法,构建用户购买商品的预测模型,输出高潜用户和目标商品的匹配结果,为精准营销提供高质量的目标群体。
- 目标:使用京东多个品类下商品的历史销售数据,构建算法模型,预测用户在未来5天内,对某个目标品类下商品的购买意向。
3.数据概述
3.1 京东用户数据集
- JData_User.csv用户数据集105,321个用户
- JData_Comment.csv商品评论558,552条记录
- JData_Product.csv预测商品集合24,187条记录
- JData_Action_201602.csv2月份行为交互记录11,485,424条记录
- JData_Action_201603.csv3月份行为交互记录25,916,378条记录
- JData_Action_201604.csv4月份行为交互记录13,199,934条记录
3.2 数据集记录数

4.数据预处理
4.1 用户一致性检验
- 一致性检验:保证行为数据中的所产生的行为均由用户数据中的用户产生(但可能存在用户在行为数据中无行为)
- 思路:利用pd.Merge根据sku连接两个DataFrame,观察数据是否减少
(1) Merge举例 import pandas as pd df1 = pd.DataFrame({'sku':['a','b','c','d'],'data':[1,1,2,3]}) df2 = pd.DataFrame({'sku':['a','b','f']}) df3 = pd.DataFrame({'sku':['a','b','d']}) df4 = pd.DataFrame({'sku':['a','b','c','d']}) display(pd.merge(df1,df2)) display(pd.merge(df1,df3)) display(pd.merge(df1,df4)) # 索引一致未减少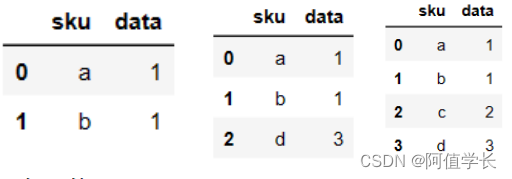
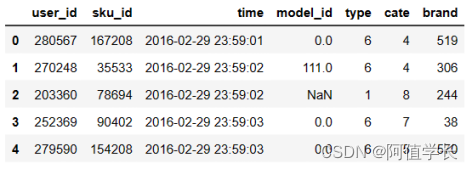
(2)查看数据 df_user = pd.read_csv('data/JData_User.csv') display(df_user.head()) df_month3 = pd.read_csv('data/JData_Action_201603.csv') df_month3.head()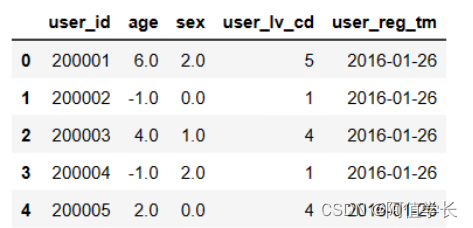
(3)垃圾回收 import gc del df_user del df_month3 gc.collect() 16
(4)利用pd.Merge根据user_id连接数据,判断数据是否减少 def user_action_id_check(): df_user = pd.read_csv('data/JData_User.csv') df_user = df_user.loc[:,'user_id'].to_frame() df_month2 = pd.read_csv('data/JData_Action_201602.csv') print ('Is action of Feb. from User file? ', len(df_month2) == len(pd.merge(df_user,df_month2))) df_month3 = pd.read_csv('data/JData_Action_201603.csv') print ('Is action of Mar. from User file? ', len(df_month3) == len(pd.merge(df_user,df_month3))) df_month4 = pd.read_csv('data/JData_Action_201604.csv') print ('Is action of Apr. from User file? ', len(df_month4) == len(pd.merge(df_user,df_month4))) del df_user,df_month2,df_month3,df_month4 gc.collect() user_action_id_check() Is action of Feb. from User file? True Is action of Mar. from User file? True Is action of Apr. from User file? True(5)结论 - User数据集中的用户和交互行为数据集中的用户完全一致 - 根据merge前后的数据量比对,能保证Action中的用户ID是User中的ID的子集
4.2 检查数据是否重复
- 去除各个数据文件中完全重复的记录,可能解释是重复数据是有意义的,比如用户同时购买多件商品,同时添加多个数量的商品到购物车等
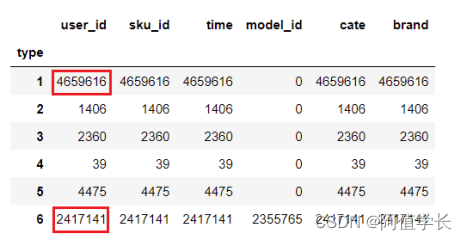
(1)删除重复数据函数 def deduplicate(filepath, filename, newpath): df_file = pd.read_csv(filepath) before = df_file.shape[0] df_file.drop_duplicates(inplace=True) after = df_file.shape[0] n_dup = before-after if n_dup != 0: print ('No. of duplicate records for ' + filename + ' is: ' + str(n_dup)) df_file.to_csv(newpath, index=None) else: print ('no duplicate records in ' + filename) del df_file gc.collect()(2)检查每个数据文件重复数据 deduplicate('data/JData_Action_201602.csv', 'Feb. action', 'data/JData_Action_201602_dedup.csv') deduplicate('data/JData_Action_201603.csv', 'Mar. action', 'data/JData_Action_201603_dedup.csv') deduplicate('data/JData_Action_201604.csv', 'Apr. action', 'data/JData_Action_201604_dedup.csv') deduplicate('data/JData_Comment.csv', 'Comment', 'data/JData_Comment_dedup.csv') deduplicate('data/JData_Product.csv', 'Product', 'data/JData_Product_dedup.csv') deduplicate('data/JData_User.csv', 'User', 'data/JData_User_dedup.csv') No. of duplicate records for Feb. action is: 2756093 No. of duplicate records for Mar. action is: 7085037 No. of duplicate records for Feb. action is: 3672710 no duplicate records in Comment no duplicate records in Product no duplicate records in User(3)重复数据分析 df_month3 = pd.read_csv('data/JData_Action_201603.csv') IsDuplicated = df_month3.duplicated() df_d=df_month3[IsDuplicated] # 发现重复数据大多数都是由于浏览(1),或者点击(6)产生 display(df_d.groupby('type').count()) del df_month3,df_d gc.collect() 964
4.3 构建user_table
为了能够进行上述清洗,在此首先构造了简单的用户(user)行为特征,user_table特征包括:
- user_id(用户id),age(年龄),sex(性别),
- user_lv_cd(用户级别),browse_num(浏览数),
- addcart_num(加购数),delcart_num(删购数),
- buy_num(购买数),favor_num(收藏数),
- click_num(点击数),buy_addcart_ratio(购买加购转化率),
- buy_browse_ratio(购买浏览转化率),
- buy_click_ratio(购买点击转化率),
- buy_favor_ratio(购买收藏转化率)
(1)定义文件名 ACTION_201602_FILE = "data/JData_Action_201602.csv" ACTION_201603_FILE = "data/JData_Action_201603.csv" ACTION_201604_FILE = "data/JData_Action_201604.csv" COMMENT_FILE = "data/JData_Comment.csv" PRODUCT_FILE = "data/JData_Product.csv" USER_FILE = "data/JData_User.csv" USER_TABLE_FILE = "data/User_table.csv"
(2)定义函数统计用户操作频次 import pandas as pd import numpy as np from collections import Counter # 功能函数: 对每一个user分组的数据进行统计 def add_type_count(group): behavior_type = group.type.astype(int) # 用户行为类别 type_cnt = Counter(behavior_type) # 1: 浏览 2: 加购 3: 删除 4: 购买 5: 收藏 6: 点击 group['browse_num'] = type_cnt[1] group['addcart_num'] = type_cnt[2] group['delcart_num'] = type_cnt[3] group['buy_num'] = type_cnt[4] group['favor_num'] = type_cnt[5] group['click_num'] = type_cnt[6] return group[['user_id', 'browse_num', 'addcart_num', 'delcart_num', 'buy_num', 'favor_num', 'click_num']](3)用户行为数据分块读取 # 由于用户行为数据量较大,一次性读入可能造成内存错误(MemoryError),因而使用pandas分块(chunk)读取 def get_from_action_data(fname, chunk_size=50000): # 对action数据进行统计 根据自己调节chunk_size大小 reader = pd.read_csv(fname, header=0, iterator=True) chunks = [] loop = True while loop: try: chunk = reader.get_chunk(chunk_size)[["user_id", "type"]] # 只读取user_id和type两个字段 chunks.append(chunk) except StopIteration: loop = False print("Iteration is stopped") df_ac = pd.concat(chunks, ignore_index=True) # 将块拼接为pandas dataframe格式 # 按user_id分组对每一组进行统计,as_index 表示无索引形式返回数据 df_ac = df_ac.groupby(['user_id'], as_index=False).apply(add_type_count) df_ac = df_ac.drop_duplicates('user_id') # 将重复的行丢弃 return df_ac(4)2月数据处理查看 df_ac = get_from_action_data(fname = ACTION_201602_FILE, chunk_size=50000) display(df_ac.head(10)) del df_ac gc.collect()
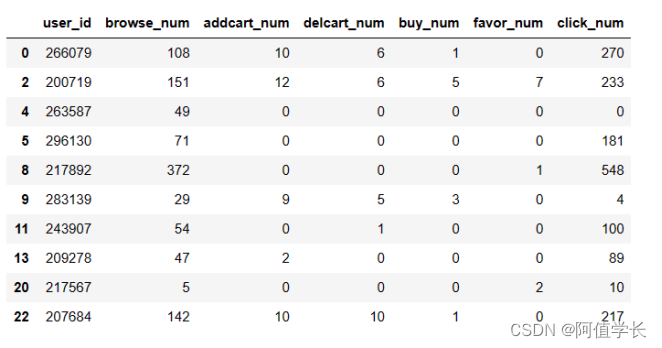
(5)定义函数聚合全部数据 def merge_action_data(): # 将各个action数据的统计量进行聚合 df_ac = [] df_ac.append(get_from_action_data(fname=ACTION_201602_FILE)) df_ac.append(get_from_action_data(fname=ACTION_201603_FILE)) df_ac.append(get_from_action_data(fname=ACTION_201604_FILE)) df_ac = pd.concat(df_ac, ignore_index=True) # 用户在不同action表中统计量求和 df_ac = df_ac.groupby(['user_id'], as_index=False).sum() # 构造转化率字段 df_ac['buy_addcart_ratio'] = df_ac['buy_num'] / df_ac['addcart_num'] df_ac['buy_browse_ratio'] = df_ac['buy_num'] / df_ac['browse_num'] df_ac['buy_click_ratio'] = df_ac['buy_num'] / df_ac['click_num'] df_ac['buy_favor_ratio'] = df_ac['buy_num'] / df_ac['favor_num'] # 将大于1的转化率字段置为1(100%) print((df_ac['buy_addcart_ratio'] > 1.).sum()) df_ac.loc[df_ac['buy_addcart_ratio'] > 1., 'buy_addcart_ratio'] = 1. df_ac.loc[df_ac['buy_browse_ratio'] > 1., 'buy_browse_ratio'] = 1. df_ac.loc[df_ac['buy_click_ratio'] > 1., 'buy_click_ratio'] = 1. df_ac.loc[df_ac['buy_favor_ratio'] > 1., 'buy_favor_ratio'] = 1. return df_ac(6)聚合全部数据 user_behavior = merge_action_data() user_behavior.head() Iteration is stopped Iteration is stopped Iteration is stopped 1430

(7)从JData_User表中抽取需要的字段 def get_from_jdata_user(): df_usr = pd.read_csv(USER_FILE, header=0) df_usr = df_usr[["user_id", "age", "sex", "user_lv_cd"]] return df_usr user_base = get_from_jdata_user() user_base.head()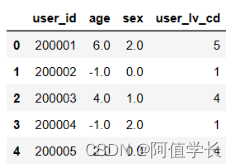
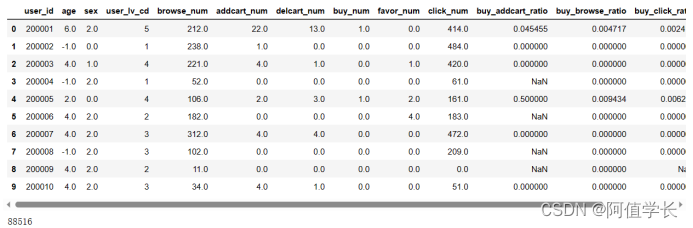
(8)数据保存 # 连接成一张表,类似于SQL的左连接(left join) user_table = pd.merge(user_base, user_behavior, on=['user_id'], how='left') user_table.to_csv(USER_TABLE_FILE, index=False) # 保存为user_table.csv display(user_table.head(10)) del user_table,user_behavior,user_base gc.collect()
5. 数据清洗
5.1 用户整体性查看
import pandas as pd df_user = pd.read_csv('data/User_table.csv',header=0) pd.options.display.float_format = '{:,.3f}'.format # 输出格式设置,保留三位小数 df_user.describe()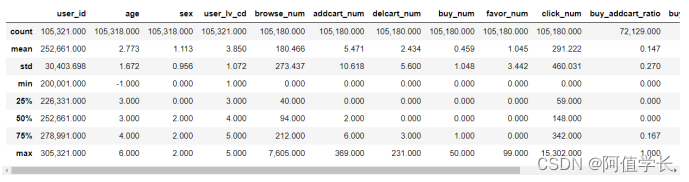
由上述统计信息发现:第一行中根据User_id统计发现有105321个用户,发现有3个用户没有age,sex字段,而且根据浏览、加购、删购、购买等记录却只有105180条记录,说明存在用户无任何交互记录,因此可以删除上述用户
5.2 删除没有age、sex字段的用户
df_user[df_user['age'].isnull()]

delete_list = df_user[df_user['age'].isnull()].index df_user.drop(delete_list,axis=0,inplace=True) df_user.shape (105318, 14)
5.3 删除无交互记录的用户
cond = (df_user['browse_num'].isnull()) & (df_user['addcart_num'].isnull()) & (df_user['delcart_num'].isnull()) & (df_user['buy_num'].isnull()) & (df_user['favor_num'].isnull()) & (df_user['click_num'].isnull()) df_naction = df_user[cond] display(df_naction.head()) df_user.drop(df_naction.index,axis=0,inplace=True) df_user.shape
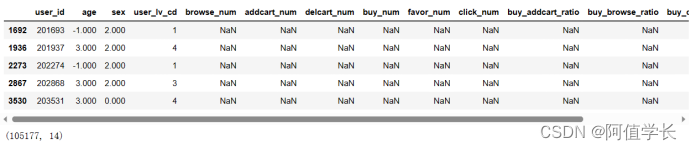
5.4 统计并删除无购买记录的用户
df_bzero = df_user[df_user['buy_num']==0] print(len(df_bzero)) # 输出购买数为0的总记录数 df_user = df_user[df_user['buy_num']!=0] # 删除无购买记录的用户 df_user.describe()
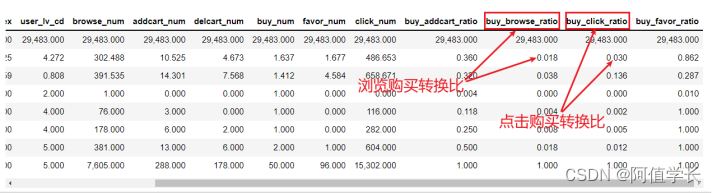
5.5 删除爬虫及惰性用户
由上表所知,浏览购买转换比和点击购买转换比均值为0.018,0.030,因此这里认为浏览购买转换比和点击购买转换比小于0.0005的用户为爬虫与惰性用户。
(1)浏览购买转换比 bindex = df_user[df_user['buy_browse_ratio']'size':10}) plt.savefig('./10-周购买情况数据可视化.png',dpi = 200) 'size':15}) plt.savefig('./11-2月购买情况可视化.png',dpi = 200) 'size':9}) plt.savefig('./12-3月购买情况可视化.png',dpi = 200) 'size':9}) plt.savefig('./14-4月购买情况可视化.png',dpi = 200) 'size':9}) plt.savefig('./17-商品8每月按天统计销量可视化.png',dpi = 200) 'n_estimators': 1000, 'max_depth': 3, 'min_child_weight': 5, 'gamma': 0.1, 'subsample': 0.9,'colsample_bytree': 0.8, 'scale_pos_weight':10, 'eta': 0.1, 'objective': 'binary:logistic','eval_metric':['auc','error']} num_round = param['n_estimators'] evallist = [(dtrain, 'train'), (dvalid, 'eval')] bst = xgb.train(param, dtrain, num_round, evallist, early_stopping_rounds=10) bst.save_model('bst.model') [0] train-auc:0.91146 train-error:0.22325 eval-auc:0.90894 eval-error:0.22536 [1] train-auc:0.92244 train-error:0.21835 eval-auc:0.91992 eval-error:0.22098 [2] train-auc:0.92433 train-error:0.22065 eval-auc:0.92176 eval-error:0.22277 ... [997] train-auc:0.98720 train-error:0.07033 eval-auc:0.98493 eval-error:0.07279 [998] train-auc:0.98720 train-error:0.07031 eval-auc:0.98493 eval-error:0.07282 [999] train-auc:0.98721 train-error:0.07030 eval-auc:0.98494 eval-error:0.07281h310.4 特征重要性/h3 pre class="brush:python;toolbar:false"def feature_importance(bst_xgb): importance = bst_xgb.get_fscore() importance = sorted(importance.items(), key=lambda x:x[1], reverse=True) df = pd.DataFrame(importance, columns=['feature', 'fscore']) display(df.head()) df['fscore'] = df['fscore'] / df['fscore'].sum() # 计算了每个特征得分的比例 file_name = 'feature_importance_.csv' df.to_csv(file_name,index=False) feature_importance(bst) feature_importance_ = pd.read_csv('feature_importance_.csv') feature_importance_.head() /pre pimg src="https://img-blog.csdnimg.cn/a59644c3be9c4d0eb63d9c142f3126e1.png" alt="在这里插入图片描述" //p h310.5 算法预测验证数据/h3 pre class="brush:python;toolbar:false"(1)查看验证数据 X_val.head() /pre pimg src="https://img-blog.csdnimg.cn/ed66027292d34d709930fa5b6ae537c1.png" alt="在这里插入图片描述" //p pre class="brush:python;toolbar:false"(2)算法预测 users=X_val[['user_id','sku_id','cate']].copy() delX_val['user_id'] delX_val['sku_id'] X_val_DMatrix=xgb.DMatrix(X_val) y_pred=bst.predict(X_val_DMatrix) X_val['pred_label']=y_pred X_val.head() /pre pimg src="https://img-blog.csdnimg.cn/f46d4a490d5845d58fe23f0daaffab21.png" alt="在这里插入图片描述" //p pre class="brush:python;toolbar:false"(3)目标值概率转分类 def label(column): if column['pred_label'] 0.5: column['pred_label'] = 1 else: column['pred_label'] = 0 return column X_val = X_val.apply(label,axis = 1) X_val.head() /pre pimg src="https://img-blog.csdnimg.cn/2147e33811a6405cb52d2fe985e97aba.png" alt="在这里插入图片描述" //p pre class="brush:python;toolbar:false"(4)添加真实值用户ID商品编号 X_val['true_label']=y_val X_val['user_id']=users['user_id'] X_val['sku_id']=users['sku_id'] X_val.head() /pre pimg src="https://img-blog.csdnimg.cn/a6830c02b2e34df4a8e6bfd39e8062d6.png" alt="在这里插入图片描述" //p h310.6 验证集模型评估/h3 pre class="brush:python;toolbar:false"(1)购买用户统计 all_user_set=X_val[X_val['true_label']==1]['user_id'].unique() # 所有购买用户 print(len(all_user_set)) all_user_test_set=X_val[X_val['pred_label']==1]['user_id'].unique() # 所有预测购买的用户 print(len(all_user_test_set)) 2610 8210 X_val.shape (96536, 252) /pre pre class="brush:python;toolbar:false"(2)准确率召回率 pos, neg = 0,0 for user_id in all_user_test_set:# 预测购买数据 if user_id in all_user_set: # 真实购买数据 pos += 1 else: neg += 1 all_user_acc = pos / ( pos + neg) all_user_recall = pos / len(all_user_set) # 从真实购买的用户中,识别了多少 print ('所有用户中预测购买用户的准确率为 ' + str(all_user_acc)) print ('所有用户中预测购买用户的召回率' + str(all_user_recall)) 所有用户中预测购买用户的准确率为 0.3132764920828258 所有用户中预测购买用户的召回率0.98544061302682 /pre pre class="brush:python;toolbar:false"(3)实际商品对准确率召回率 用户-商品id # 所有预测购买用户商品对应关系 all_user_test_item_pair = X_val[X_val['pred_label'] == 1]['user_id'].map(str) + '-' + X_val[X_val['pred_label'] == 1]['sku_id'].map(str) all_user_test_item_pair = np.array(all_user_test_item_pair) print(len(all_user_test_item_pair)) # 所有实际用户-商品对 all_user_item_pair = X_val[X_val['true_label']==1]['user_id'].map(str) + '-' + X_val[X_val['true_label']==1]['sku_id'].map(str) all_user_item_pair = np.array(all_user_item_pair) print(len(all_user_item_pair)) pos, neg = 0, 0 for user_item_pair in all_user_test_item_pair: if user_item_pair in all_user_item_pair: pos += 1 else: neg += 1 all_item_acc = 1.0 * pos / ( pos + neg) all_item_recall = 1.0 * pos / len(all_user_item_pair) print ('所有用户中预测购买商品的准确率为 ' + str(all_item_acc)) print ('所有用户中预测购买商品的召回率' + str(all_item_recall)) 15503 8852 所有用户中预测购买商品的准确率为 0.5600206411662259 所有用户中预测购买商品的召回率0.9807953004970628 /pre h310.7 测试数据/h3 pre class="brush:python;toolbar:false"(1)数据加载 X_data=pd.read_csv('test_set.csv') display(X_data.head()) X_test,y_test=X_data.iloc[:,:-1],X_data.iloc[:,-1] /pre pimg src="https://img-blog.csdnimg.cn/fad32f9e67ca442bab3f03b49744b79a.png" alt="在这里插入图片描述" //p pre class="brush:python;toolbar:false"(2)算法预测 users=X_test[['user_id','sku_id','cate']].copy() delX_test['user_id'] delX_test['sku_id'] X_test_DMatrix=xgb.DMatrix(X_test) y_pred=bst.predict(X_test_DMatrix) X_test['pred_label']=y_pred X_test.head() /pre pimg src="https://img-blog.csdnimg.cn/45a3500849e146f89dced05e1d1169a6.png" alt="在这里插入图片描述" //p pre class="brush:python;toolbar:false"(3)目标值概率转分类 def label(column): if column['pred_label'] > 0.5: column['pred_label'] = 1 else: column['pred_label'] = 0 return column X_test = X_test.apply(label,axis = 1) X_test.head()
(4)添加真实用户ID商品编号 X_test['true_label']=y_test X_test['user_id']=users['user_id'] X_test['sku_id']=users['sku_id'] X_test.head()
10.8 测试集模型评估
(1)购买用户统计 all_user_set=X_test[X_test['true_label']==1]['user_id'].unique() # 所有购买用户 print(len(all_user_set)) all_user_test_set=X_test[X_test['pred_label']==1]['user_id'].unique() # 所有预测购买的用户 print(len(all_user_test_set)) 643 5576
(2)准确率召回率 pos, neg = 0,0 for user_id in all_user_test_set: if user_id in all_user_set: pos += 1 else: neg += 1 all_user_acc = 1.0 * pos / ( pos + neg) all_user_recall = 1.0 * pos / len(all_user_set) print ('所有用户中预测购买用户的准确率为 ' + str(all_user_acc)) print ('所有用户中预测购买用户的召回率' + str(all_user_recall)) 所有用户中预测购买用户的准确率为 0.10258249641319943 所有用户中预测购买用户的召回率0.8895800933125972(3)实际商品对准确率召回率 # 所有预测购买用户商品对应关系 all_user_test_item_pair = X_test[X_test['pred_label'] == 1]['user_id'].map(str) + '-' + X_test[X_test['pred_label'] == 1]['sku_id'].map(str) all_user_test_item_pair = np.array(all_user_test_item_pair) print(len(all_user_test_item_pair)) # 所有实际商品对 all_user_item_pair = X_test[X_test['true_label']==1]['user_id'].map(str) + '-' + X_test[X_test['true_label']==1]['sku_id'].map(str) all_user_item_pair = np.array(all_user_item_pair) print(len(all_user_item_pair)) pos, neg = 0, 0 for user_item_pair in all_user_test_item_pair: if user_item_pair in all_user_item_pair: pos += 1 else: neg += 1 all_item_acc = 1.0 * pos / ( pos + neg) all_item_recall = 1.0 * pos / len(all_user_item_pair) print ('所有用户中预测购买商品的准确率为 ' + str(all_item_acc)) print ('所有用户中预测购买商品的召回率' + str(all_item_recall)) 17117 11310 所有用户中预测购买商品的准确率为 0.5433779283752994 所有用户中预测购买商品的召回率0.8223695844385499
- 去除各个数据文件中完全重复的记录,可能解释是重复数据是有意义的,比如用户同时购买多件商品,同时添加多个数量的商品到购物车等







