

Pytorch
PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。
首先是使用pytorch
cuda 和 cudnn
cuDNN是NVIDIA专门针对深度神经网络中的基础操作而设计的基于GPU的加速库。cuDNN为深度神经网络中的标准流程提供了高度优化的实现方式,例如卷积、池化、归一化以及激活层的前向以及后向过程。当开发者们需要用到深度学习GPU加速时,才安装cuDNN库,工作速度相较CPU快很多。
需要安装cuda 和 cudnn 库的卸载与安装,可以参考以下教程:
cuda和cudnn安装
安装完成后,可按照下面教程安装pytorch:
此处需要用到anaconda:Anaconda是一个安装、管理Python相关包的软件,其包含了conda、Python等180多个科学包及其依赖项,可以用于在同一个机器上安装不同版本的软件包及其依赖,并能够在不同的环境之间切换。
pytorch安装
另外,如需在pycharm进行操作,可安装以下教程配置虚拟环境:
pycharm配置讯环境(此步需要完成pytorch环境的安装,有anaconda环境)
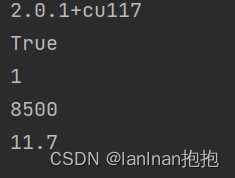
所有环境准备好以后,查看配置是否完成:
import torch # 查看版本 print(torch.__version__) # 查看gup是否可用 print(torch.cuda.is_available()) # 返回gpu个数 print(torch.cuda.device_count()) # 查看对应cuda版本号 print(torch.backends.cudnn.version()) print(torch.version.cuda)
现在就开始准备移植所需的文件吧。
pt模型和pth模型的不同
PT模型是一种完整的模型文件,不仅包含了模型的参数,还包括了模型的结构,可以直接被加载到模型中,开始进行训练和预测。而pth文件则只保存了模型的参数,因此在加载模型时需要重新定义模型结构。
所以,需要一个安卓端的pt模型
这里我们使用到图像识别的resnet101模型,新建一个py文件,运行以下代码:
模型转换
import torch
import torchvision
model = torchvision.models.resnet101(pretrained=True)
model.eval()
example = torch.rand(1, 3, 224, 224)
traced_script_module = torch.jit.trace(model, example)
traced_script_module.save("model101.pt")
- import torch 和 import torchvision 是导入PyTorch和PyTorch的计算机视觉库。
- model = torchvision.models.resnet101(pretrained=True) 加载一个预训练的ResNet-101模型。pretrained=True表示使用预训练的权重,这些权重是在ImageNet数据集上训练得到的。
- model.eval() 将模型设置为评估模式。这在推理时使用,例如在测试集或生产环境中。
- example = torch.rand(1, 3, 224, 224) 创建一个随机输入张量,大小为[1, 3, 224, 224],模拟一个输入图像。
- traced_script_module = torch.jit.trace(model, example) 使用torch.jit.trace将模型转换为一个TorchScript模型。TorchScript是一种可以优化PyTorch模型的方式,使其在没有Python运行环境的情况下运行。
- traced_script_module.save(“model101.pt”) 将转换后的模型保存为"model101.pt"。
标签获取
这样,我们就获得了一个图像识别的pt模型。
然后,需要找到该模型的标签文件,我们从以下项目中获取
https://github.com/ethereon/caffe-tensorflow/blob/master/examples/imagenet/imagenet-classes.txt
拿到txt标签文件以后,我们需要转换成java中String[]的形式,所以稍微处理一下,
import re with open('imagenet-classes.txt','r',encoding='utf-8') as f: text = f.read() text = re.sub(r'^', '"', text, flags=re.M) text = re.sub(r'$', '",', text, flags=re.M) with open('imagenet-classes.txt','w',encoding='utf-8') as f: f.write(text)这里是给开头和结尾都加上了"(双引号)以及结尾用,(逗号)分隔。
安卓端代码
完成以后我们打开AndroidStudio
新建一个空的项目
在资源文件中放入我们的model101.pt文件:
然后Gradle导入pytorch的依赖:
implementation("org.pytorch:pytorch_android:1.12.1") implementation("org.pytorch:pytorch_android_torchvision:1.12.1")完成以后修改activity
MainAvity:
public class MainActivity extends AppCompatActivity { Button takePictureBtn=null; Bitmap bitmap = null; Module module = null; // 将图片显示在界面上 ImageView imageView = null; TextView textView = null; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); initView(); //从assets中获得图片数据 try { bitmap = BitmapFactory.decodeStream(getAssets().open("image.jpg")); imgClassify(bitmap); } catch (IOException e) { Log.e("PytorchHelloWorld", "Error reading assets", e); finish(); } } private void imgClassify(Bitmap img){ try { // 加载PyTorch序列化模型 module = Module.load(assetFilePath(this, "model101.pt")); } catch (IOException e) { Log.e("PytorchHelloWorld", "Error reading assets", e); finish(); } imageView.setImageBitmap(img); // 建立输入张量 final Tensor inputTensor = TensorImageUtils.bitmapToFloat32Tensor(img, TensorImageUtils.TORCHVISION_NORM_MEAN_RGB, TensorImageUtils.TORCHVISION_NORM_STD_RGB); // 运行模型推理 final Tensor outputTensor = module.forward(IValue.from(inputTensor)).toTensor(); // 获取推理结果 final float[] scores = outputTensor.getDataAsFloatArray(); // 获取概率最高的分类的索引号 float maxScore = -Float.MAX_VALUE; int maxScoreIdx = -1; for (int i = 0; i maxScore) { maxScore = scores[i]; maxScoreIdx = i; } } //通过索引号获得分类名称 String className = ImageNetClasses.IMAGENET_CLASSES[maxScoreIdx]; textView.setText("识别结果为:"+className); } private void initView(){ takePictureBtn = findViewById(R.id.button); // 将图片显示在界面上 imageView = findViewById(R.id.image); // 显示分类名称 textView = findViewById(R.id.text); takePictureBtn.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { Intent intent = new Intent(MainActivity.this,TakePicturesActivity.class); startActivity(intent); } }); } //返回模型文件路径 public static String assetFilePath(Context context, String assetName) throws IOException { File file = new File(context.getFilesDir(), assetName); if (file.exists() && file.length() > 0) { return file.getAbsolutePath(); } try (InputStream is = context.getAssets().open(assetName)) { try (OutputStream os = new FileOutputStream(file)) { byte[] buffer = new byte[4 * 1024]; int read; while ((read = is.read(buffer)) != -1) { os.write(buffer, 0, read); } os.flush(); } return file.getAbsolutePath(); } } }TakePicturesActivity:
package com.example.newdemo05; import static com.example.newdemo05.MainActivity.assetFilePath; import androidx.annotation.NonNull; import androidx.appcompat.app.AppCompatActivity; import androidx.core.app.ActivityCompat; import androidx.core.content.ContextCompat; import android.content.ContentResolver; import android.content.Intent; import android.content.pm.PackageManager; import android.graphics.Bitmap; import android.graphics.BitmapFactory; import android.hardware.camera2.CameraAccessException; import android.hardware.camera2.CameraCharacteristics; import android.hardware.camera2.CameraDevice; import android.hardware.camera2.CameraManager; import android.hardware.camera2.params.StreamConfigurationMap; import android.net.Uri; import android.os.Bundle; import android.provider.MediaStore; import android.util.Log; import android.view.TextureView; import android.view.View; import android.widget.Button; import android.widget.ImageView; import android.widget.TextView; import com.example.newdemo05.classify.ImageNetClasses; import org.pytorch.IValue; import org.pytorch.Module; import org.pytorch.Tensor; import org.pytorch.torchvision.TensorImageUtils; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStream; public class TakePicturesActivity extends AppCompatActivity { private TextureView textureView; private TextView textPrediction; private Button openCam; private ImageView v_img; Module module = null; private CameraDevice cameraDevice; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_take_pictures); initView(); } private void initView(){ v_img = findViewById(R.id.image); textPrediction = findViewById(R.id.text_prediction); openCam = findViewById(R.id.btn_capture); openCam.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { startCamera(); } }); } // 打开相机 public void startCamera(){ Intent intent = new Intent(Intent.ACTION_PICK, null); //调用setDataAndType方法,指定了选择的数据类型为图片 //设置数据的URI为MediaStore.Images.Media.EXTERNAL_CONTENT_URI,表示选择外部存储中的图片 intent.setDataAndType(MediaStore.Images.Media.EXTERNAL_CONTENT_URI, "image/*"); //调用startActivityForResult方法,将Intent发送给系统,并指定一个请求码为2,以便在之后的回调中处理用户选择的图片 startActivityForResult(intent, 2); } @Override protected void onActivityResult(int requestCode, int resultCode, Intent data) { super.onActivityResult(requestCode, resultCode, data); if (requestCode == 2) { // 从相册返回的数据 Log.e(this.getClass().getName(), "Result:" + data.toString()); if (data != null) { // 得到图片的全路径 Uri uri = data.getData(); v_img.setImageURI(uri); ContentResolver cr = getContentResolver(); InputStream inputStream = null; try { inputStream = cr.openInputStream(uri); } catch (FileNotFoundException e) { throw new RuntimeException(e); } Bitmap bitmap = BitmapFactory.decodeStream(inputStream); imgClassify(bitmap); Log.e(this.getClass().getName(), "Uri:" + String.valueOf(uri)); } } } private void imgClassify(Bitmap img){ try { // 加载PyTorch序列化模型 module = Module.load(assetFilePath(this, "model101.pt")); } catch (IOException e) { Log.e("PytorchHelloWorld", "Error reading assets", e); finish(); } v_img.setImageBitmap(img); // 建立输入张量 final Tensor inputTensor = TensorImageUtils.bitmapToFloat32Tensor(img, TensorImageUtils.TORCHVISION_NORM_MEAN_RGB, TensorImageUtils.TORCHVISION_NORM_STD_RGB); // 运行模型推理 final Tensor outputTensor = module.forward(IValue.from(inputTensor)).toTensor(); // 获取推理结果 final float[] scores = outputTensor.getDataAsFloatArray(); // 获取概率最高的分类的索引号 float maxScore = -Float.MAX_VALUE; int maxScoreIdx = -1; for (int i = 0; i maxScore) { maxScore = scores[i]; maxScoreIdx = i; } } //通过索引号获得分类名称 String className = ImageNetClasses.IMAGENET_CLASSES[maxScoreIdx]; textPrediction.setText("识别结果为:"+className); } }然后新建一个ImageNetClasses,来装我们的标签文件:
public class ImageNetClasses { public static String[] IMAGENET_CLASSES = new String[]{};}然后负责粘贴处理好的标签txt文件数据:
具体代码逻辑如下:
- TakePicturesActivity: 主Activity,用于打开相机或相册,获取图片并显示。
- initView(): 初始化视图控件,如ImageView、TextView和Button。
- startCamera(): 打开系统相册,调用startActivityForResult获取图片。
- onActivityResult(): 接收选择的图片,将图片显示在ImageView上。
- imgClassify(): 使用PyTorch模型对图片进行图像分类,将结果显示在TextView上。
- Module: PyTorch的模型类,用于加载pt模型并进行推理。
- Tensor: PyTorch的张量类,用于转换Bitmap为模型输入张量。
- TensorImageUtils: PyTorch的图片工具类,用于图像数据的预处理。
- ImageNetClasses: 包含ImageNet数据集的所有类别名称。
主要步骤是:
- 初始化视图控件
- 打开相册,获取图片uri
- 将图片解码为Bitmap
- 用TensorImageUtils处理为模型输入张量
- 加载PyTorch模型并进行推理
- 处理输出结果,显示分类类别名称







