

第一章 昇腾AI基础知识
第一节 本章学习目标
- 了解CANN在昇腾AI架构中的位置和作用。
- 了解基于CANN的应用开发编成框架、基本概念。
第二节 昇腾AI全栈架构
昇腾A全栈可以分成四个大部分:
- 应用使能层面,此层面通常包含用于部署模型的软硬件,例如API、SDK、部署平台,模型库等等。
- AI框架层面,此层面包含用于构建模型的训练框架,例如华为的MindSpore 、TensorFlow 、Pytorch 等。
- 异构计算架构,偏底层、偏通用的计算框架,用于针对上层A框架的调用进行加速,力求向上支持多种A框架,并在硬件上进行加速。
- 计算硬件,本层是AI计算的底座,有了强力的芯片及硬件设备,上层的加速才有实施的基础。

第三节 异构计算架构CANN
CANN提供了功能强大、适配性好、可自定义开发的AI异构计算架构,自顶向下分为5部分。
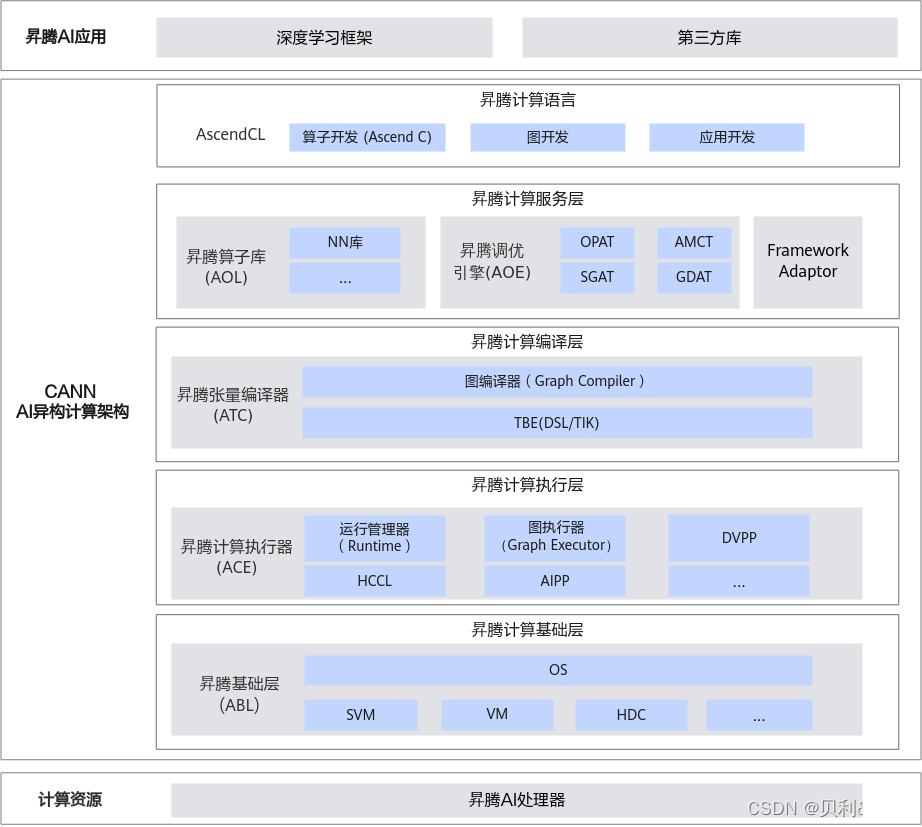
- 昇腾计算语言(Ascend Computing Language,简称AscendCL):AscendCL接口是昇腾计算开放编程框架,是对底层昇腾计算服务接口的封装。它提供设备(Device)管理、上下文(Context)管理、流(Stream)管理、内存管理、模型加载与执行、算子加载与执行、媒体数据处理、图(Graph)管理等API库,供用户开发人工智能应用。
- 昇腾计算服务层(Ascend Computing Service Layer): 主要提供昇腾算子库AOL(Ascend Operator Library),通过神经网络(Neural Network,NN)库、线性代数计算库(Basic Linear Algebra Subprograms,BLAS)等高性能算子加速计算;昇腾调优引擎AOE(Ascend Optimization Engine),通过算子调优OPAT、子图调优SGAT、梯度调优GDAT、模型压缩AMCT提升模型端到端运行速度。同时提供AI框架适配器Framework Adaptor用于兼容TensorFlow、PyTorch等主流AI框架。
- 昇腾计算编译层(Ascend Computing Compilation Layer):昇腾计算编译层通过图编译器(Graph Compiler)将用户输入中间表达(Intermediate Representation,IR)的计算图编译成昇腾硬件可执行模型;同时借助张量加速引擎TBE(Tensor Boost Engine)的自动调度机制,高效编译算子。
- 昇腾计算执行层(Ascend Computing Execution Layer):负责模型和算子的执行,提供运行时库(Runtime)、图执行器(Graph Executor)、数字视觉预处理(Digital Vision Pre-Processing,DVPP)、人工智能预处理(Artificial Intelligence Pre-Processing,AIPP)、华为集合通信库(Huawei Collective Communication Library,HCCL)等功能单元。
- 昇腾计算基础层(Ascend Computing Base Layer):主要为其上各层提供基础服务,如共享虚拟内存(Shared Virtual Memory,SVM)、设备虚拟化(Virtual Machine,VM)、主机-设备通信(Host Device Communication,HDC)等。
第四节昇腾计算语言接口AscendCL
AscendCL(Ascend Computing Language)是一套用于在昇腾平台上开发深度神经网络应用的C语言API库,提供运行资源管理、内存管理、模型加载与执行、算子加载与执行、媒体数据处理等API,能够实现利用昇腾硬件计算资源、在昇腾CANN平台上进行深度学习推理计算、图形图像预处理、单算子加速计算等能力。简单来说,就是统一的API框架,实现对所有资源的调用。

AscendCL的应用场景:
- 开发应用:用户可以直接调用AscendCL提供的接口开发图片分类应用、目标识别应用等。
- 供第三方框架调用:用户可以通过第三方框架调用AscendCL接口,以便使用昇腾AI处理器的计算能力。
- 供第三方开发lib库:用户还可以使用AscendCL封装实现第三方lib库,以便提供昇腾AI处理器的运行管理、资源管理等能力。
AscendCL的优势:
- 高度抽象:算子编译、加载、执行的API归一,相比每个算子一个API,AscendCL大幅减少API数量,降低复杂度。
- 向后兼容:AscendCL具备向后兼容,确保软件升级后,基于旧版本编译的程序依然可以在新版本上运行。
- 零感知芯片:一套AscendCL接口可以实现应用代码统一,多款昇腾AI处理器无差异。
第二章 PyTorch模型迁移&调优
第一节 本章学习目标
- 了解PyTorch是如何适配到昇腾平台上的
- 了解Davinci硬件架构以及什么样的模型在昇腾上更亲和
- 了解软件术语和Ascend-PyTorch的安装步骤
- 了解原生PyTorch的模型代码是如何适配到Ascend-PyTorch
第二节 PyTorch Adapter概述
当前阶段,PyTorch框架与昇腾AI处理器进行了在线对接适配。
方案特性及优点
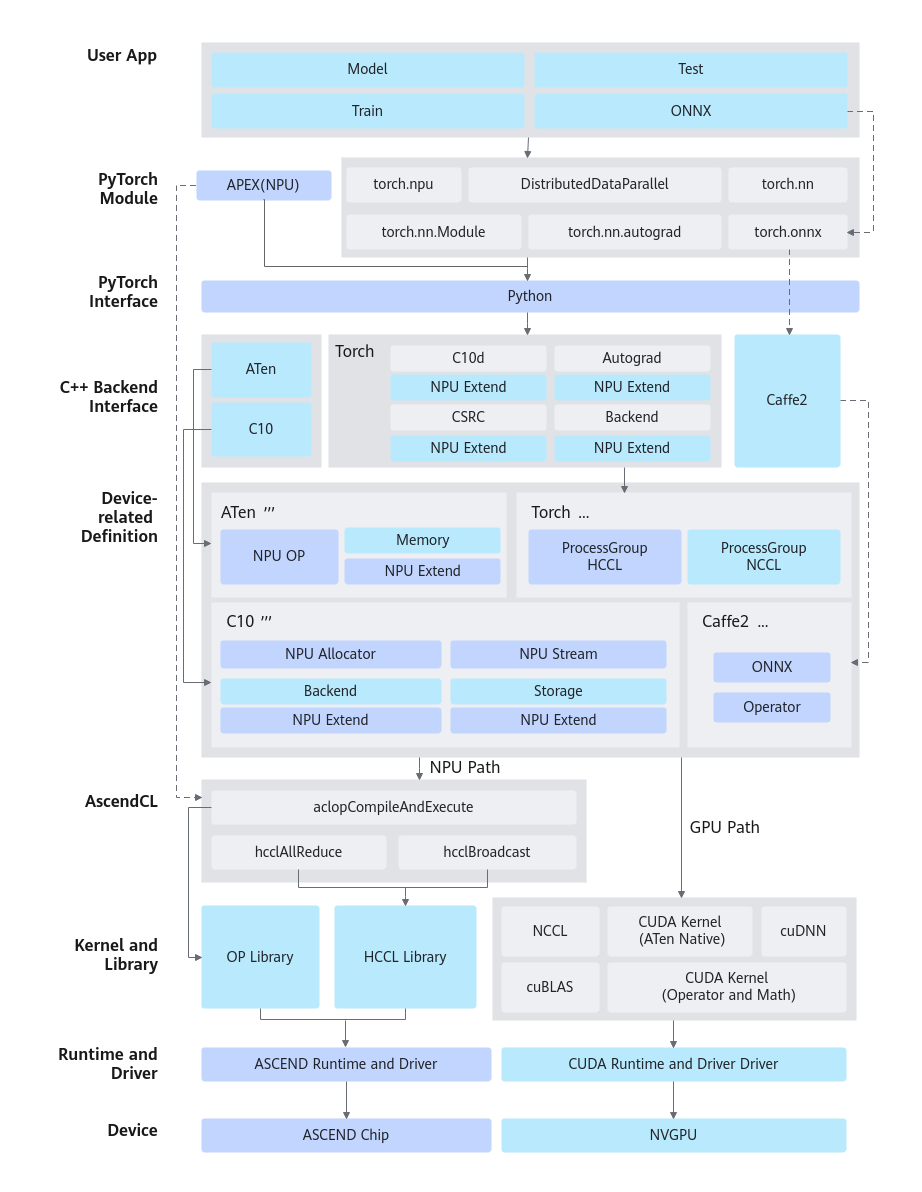
昇腾AI处理器的加速实现方式是以算子为粒度进行调用(OP-based),即通过Ascend Computing Language(AscendCL)调用一个或几个亲和算子组合的形式,代替原有GPU的实现方式。其逻辑模型如图1所示。
当前选择在线对接适配方案的主要原因有以下几点:
- 最大限度的继承PyTorch框架动态图的特性。
- 最大限度的继承GPU在PyTorch上的使用方式,可以使用户在将模型移植到昇腾AI处理器设备进行训练时,在开发方式和代码重用方面做到最小的改动。
- 最大限度的继承PyTorch原生的体系结构,保留框架本身出色的特性,比如自动微分、动态分发、Debug、Profiling、Storage共享机制以及设备侧的动态内存管理等。
- 扩展性好。在打通流程的通路之上,对于新增的网络类型或结构,只需涉及相关计算类算子的开发和实现。框架类算子,反向图建立和实现机制等结构可保持复用。
- 与GPU的使用方式和风格保持一致。用户在使用在线对接方案时,只需在Python侧和device相关操作中,指定device为昇腾AI处理器,即可完成用昇腾AI处理器在PyTorch对网络的开发、训练以及调试,用户无需进一步关注昇腾AI处理器具体的底层细节。这样可以确保用户的修改最小化,迁移成本较低。
第三节 什么是达芬奇架构?
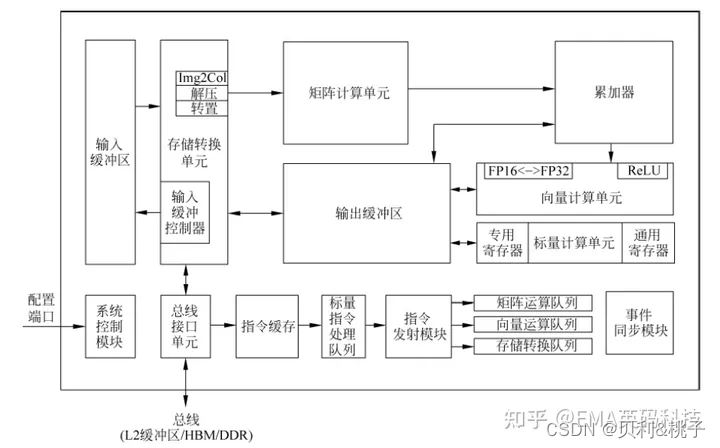
达芬奇架构(DaVinci Architecture)是华为面向计算密集型人工智能应用研发的全新计算架构,昇腾AI处理器的AI Core即是基于此架构实现。其基本结构如图:
达芬奇架构的优势有哪些?
- 灵活性和可扩展性:
达芬奇架构将应用程序分解成多个模块,每个模块都有特定的功能和职责,可以独立地构建、测试、部署和维护,从而更容易适应不同的业务需求和市场变化。
- 高算力和高能效:
达芬奇架构是NPU的一个部分,细分成核心的3D Cube、Vector向量计算单元、Scalar标量计算单元等,负责不同的运算任务。达芬奇架构以高性能3D Cube计算引擎为基础,针对矩阵运算进行加速,大幅提高单位面积下的AI算力,充分激发端侧AI的运算潜能。
- 支持多种精度计算:
达芬奇架构同时支持多种精度计算,支撑训练和推理两种场景的数据精度要求,实现AI的全场景需求覆盖。
- 高可用性和可靠性:
达芬奇架构通过将应用程序分解成多个小型部件,降低了系统的复杂性,从而提高了系统的稳定性和可用性。
- 更高效的开发、测试和部署:
由于每个部件都相对独立,因此可以更容易地进行单元测试和集成测试,这可以帮助开发人员更快地找到和解决问题,从而减少了开发和维护的成本。
第四节 模型迁移
简介
将基于PyTorch的训练脚本迁移到昇腾AI处理器上进行训练,目前有以下3种方式:自动迁移(推荐)、工具迁移、手工迁移,且迁移前要保证该脚本能在GPU、CPU上运行。推荐用户使用最简单的自动迁移方式。
- 自动迁移:在训练脚本中导入脚本转换库,然后拉起脚本执行训练。训练脚本在运行的同时,会自动将脚本中的CUDA接口替换为昇腾AI处理器支持的NPU接口。整体过程为边训练边转换。
- 工具迁移:训练前,通过脚本迁移工具,自动将训练脚本中的CUDA接口替换为昇腾AI处理器支持的NPU接口,并生成迁移报告(脚本转换日志、不支持算子的列表、脚本修改记录)。训练时,运行转换后的脚本。整体过程为先转换脚本,再进行训练。
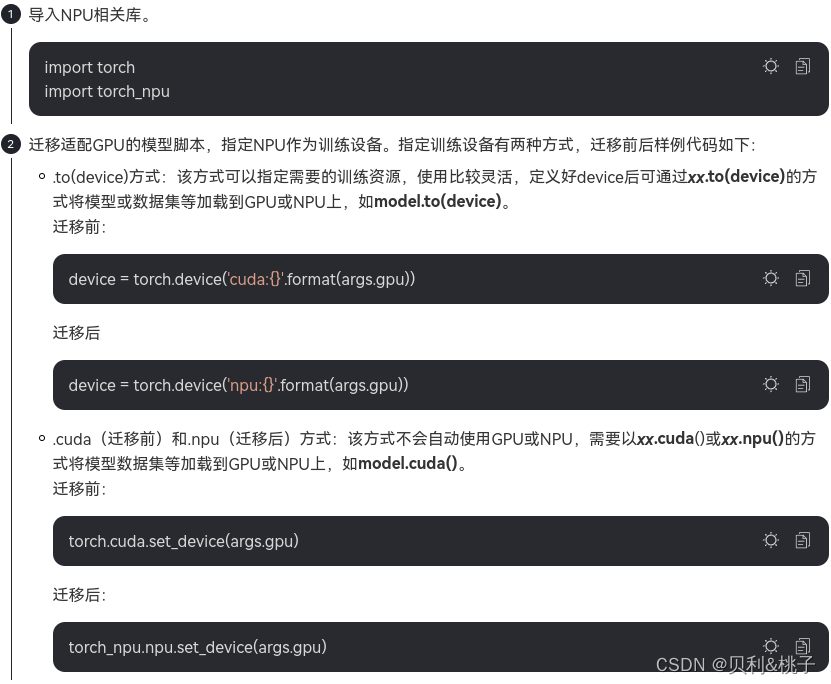
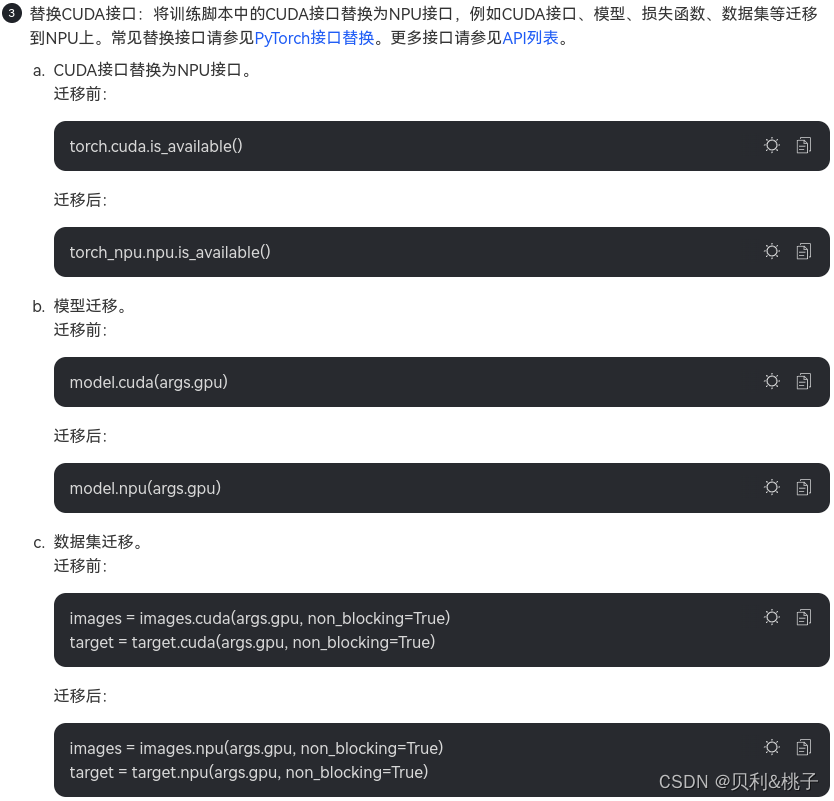
- 手工迁移:算法工程师通过对模型的分析、GPU与NPU代码的对比进而对训练脚本进行修改,以支持在昇腾AI处理器上执行训练。迁移要点如下。
- 定义NPU为训练设备,或将训练脚本中适配GPU的接口切换至适配NPU的接口。
- 多卡迁移需修改芯片间通信方式为hccl。
(推荐)自动迁移
----------------------------说明---------------------------------
- 仅PyTorch 1.11.0版本及以上使用,自动迁移方式较简单,且修改内容最少,只需在训练脚本中导入库代码。
- 当前自动迁移暂不支持channel_last特性,建议用户使用contiguous代替。
- 若原脚本中使用的backend为nccl,在init_process_group初始化进程组后,backend已被自动迁移工具替换为hccl。如果后续代码逻辑包含backend是否为nccl的判断,例如assert backend in [‘gloo’, ‘nccl’]、if backend == ‘nccl’,请手动将字符串nccl改写为hccl。
- 由于自动迁移工具使用了Python的动态特性,但torch.jit.script不支持Python的动态语法,因此用户原训练脚本中包含torch.jit.script时使用自动迁移功能会产生冲突,目前自动迁移时会屏蔽torch.jit.script功能,若用户脚本中必须使用torch.jit.script功能,请使用工具迁移进行迁移。
--------------------------使用方法----------------------------
1.在训练脚本中导入以下库代码。
import torch import torch_npu ..... from torch_npu.contrib import transfer_to_npu
2.参考模型训练执行训练。查看训练后是否生成权重文件,生成了如下图文件则说明迁移训练成功。

若训练过程中提示部分cuda接口报错,可能是部分API(算子API或框架API)不支持引起,用户可参考以下方案进行解决。
- 参见PyTorch Analyse迁移分析工具对脚本进行分析,获得支持情况存疑的API列表,进入昇腾开源社区提出ISSUE求助。
- 参见以下步骤,将部分不支持的算子API移动至CPU运行。
-
1.参见《CANN 软件安装指南》中“安装PyTorch > 编译安装PyTorch ”章节获取Ascend PyTorch源码包。
-
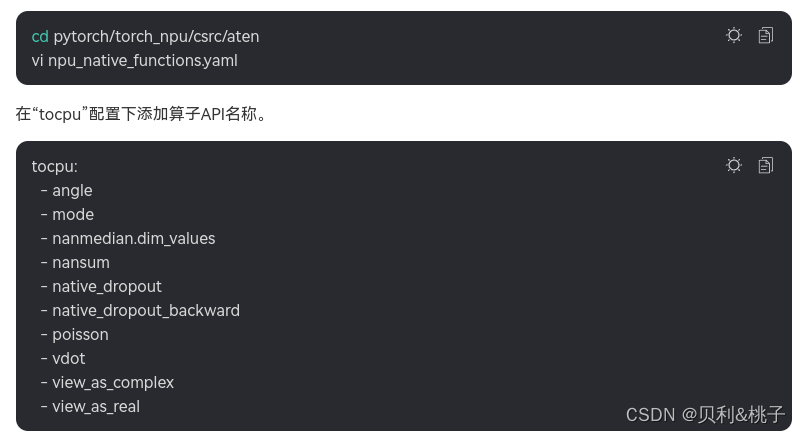
2.进入获取后的源码包目录,修改“npu_native_functions.yaml”。
-
3.参见《CANN 软件安装指南》中“安装PyTorch > 编译安装PyTorch ”章节重新编译框架插件包并安装。
-
4.重新进行迁移训练。
- 参见《TBE&AI CPU算子开发指南》中“算子开发过程>算子适配>适配插件开发(PyTorch框架)”进行算子适配。
工具迁移
工具迁移推荐使用命令行方式。
若用户想使用图形开发界面、或已安装MindStudio,可以参考《MindStudio 安装指南》中的“分析迁移>PyTorch GPU2Ascend”章节使用MindStudio中集成的PyTorch GPU2Ascend功能进行工具迁移。
使用命令行方式进行工具迁移的核心步骤如下:


./pytorch_gpu2npu.sh -i 原始脚本路径 -o 脚本迁移结果输出路径 -v 原始脚本框架版本 [-s] [-m] [distributed -t 目标模型变量名 -m 训练脚本的入口文件]
示例参考:
#单卡 ./pytorch_gpu2npu.sh -i /home/train/ -o /home/out -v 1.11.0 [-s] [-m] #分布式 ./pytorch_gpu2npu.sh -i /home/train/ -o /home/out -v 1.11.0 [-s] [-m] distributed -m /home/train/train.py [-t model]
“[]”表示可选参数,实际使用可不用添加。
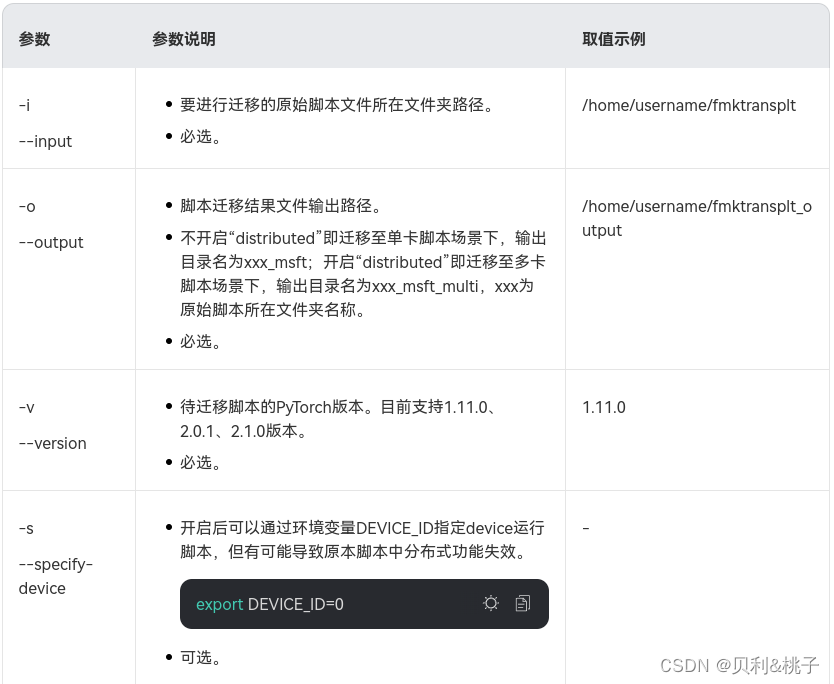

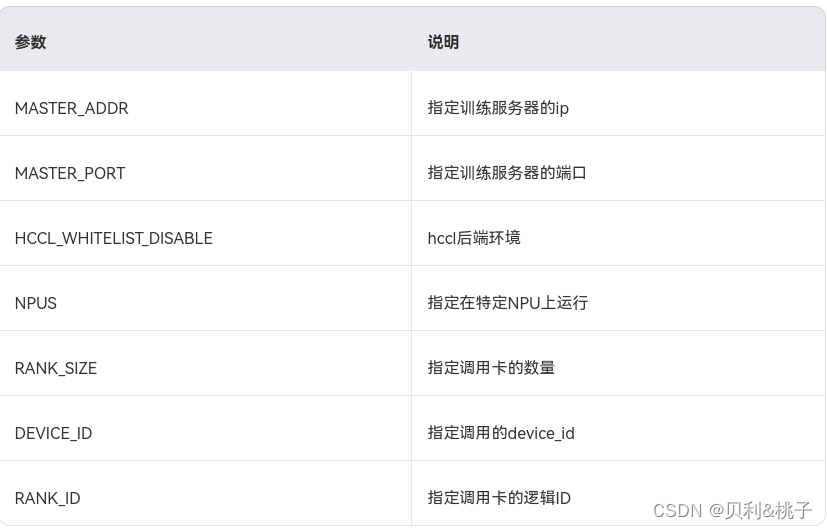
如果迁移时启用了“distributed”参数,迁移后会生成如下run_distributed_npu.sh文件,在执行迁移后的模型之前需要把文件中的“please input your shell script here”语句替换成模型原来的训练shell脚本。执行run_distributed_npu.sh文件后会生成指定NPU的log日志。
export MASTER_ADDR=127.0.0.1 export MASTER_PORT=29688 export HCCL_WHITELIST_DISABLE=1 NPUS=($(seq 0 7)) export RANK_SIZE=${#NPUS[@]} rank=0 for i in ${NPUS[@]} do export DEVICE_ID=${i} export RANK_ID=${rank} echo run process ${rank} please input your shell script here > output_npu_${i}.log 2>&1 & let rank++ done将“please input your shell script here”替换为模型训练命令“bash model_train_script.sh --data_path data_path ”。

----------------------------说明----------------------------------
- 若用户训练脚本中包含昇腾NPU平台不支持的amp_C模块,需要用户手动删除后再进行训练。
- 由于转换后的脚本与原始脚本平台不一致,迁移后的脚本在调试运行过程中可能会由于算子差异等原因而抛出异常,导致进程终止,该类异常需要用户根据异常信息进一步调试解决。
手工迁移
手工迁移需要用户对AI模型有迁移基础,了解GPU与NPU的代码的异同点以及各种迁移手段。手工迁移过程中各个模型的迁移方法均有不同,下文给出手工迁移的核心要点。

------------------------单卡迁移--------------------------
----------------------------------多卡迁移(分布式训练迁移)---------------------------------
除单卡迁移包含的3个修改要点外,在分布式场景下,还需要切换通信方式,直接修改init_process_group的值。
修改前,GPU使用nccl方式:
dist.init_process_group(backend='nccl',init_method = "tcp//:127.0.0.1:**", ...... ,rank = args.rank) # **为端口号,根据实际选择一个闲置端口填写
修改后,NPU使用hccl方式:
dist.init_process_group(backend='hccl',init_method = "tcp//:127.0.0.1:**", ...... ,rank = args.rank) # **为端口号,根据实际选择一个闲置端口填写
第三章 AI应用开发
第一节 本章学习目标
1.了解昇腾A全栈架构及该架构中各层的作用。
2.了解异构计算架构CANN在昇腾A全栈中的位置和作用。
3.了解应用开发编程框架、基本概念。
4.掌握基本的应用开发流程,可以按照指导编译、运行应用。
5.了解如何获取及查看应用运行日志,具备基本的问题定界、定位能力。
在开始应用开发入门课程之前,请先通读第2节您需要提前准备什么,以便更好地理解本课程中涉及的概念并完成练习
第二节 需要提前准备审什么
- C&C++语言
变量、基本数据类型、指针、引用、const 限定符等
字符串和数组
表达式,包括赋值运算、条件运算、逻辑运算等
条件语句,包括if条件语句、for循环、while 循环等函数,包括函数声明、return 语句等
I/O标准库
- Python 语言
使用位置和关键字参数定义和调用函数
字典、列表、集合(创建、访问和迭代)
for循环,for具有多个迭代器变量的循环(例如,fora,bin[(1,2),(3,4)])
if/else条件块和条件表达式
字符串格式(例如,%。2f%3.14)
变量、赋值、基本数据类型(int,float ,bool,str等)
- 熟悉Linux 基本操作
本课程中的操作涉及Linux 操作系统上的如下基本操作,建议您在学习本课程前先学习这部分内容:
1.远程登录Linux 服务器
2.文件与目录的管理,包括新增、删除文件或目录等
3.熟悉vi/vim文本编译器的使用

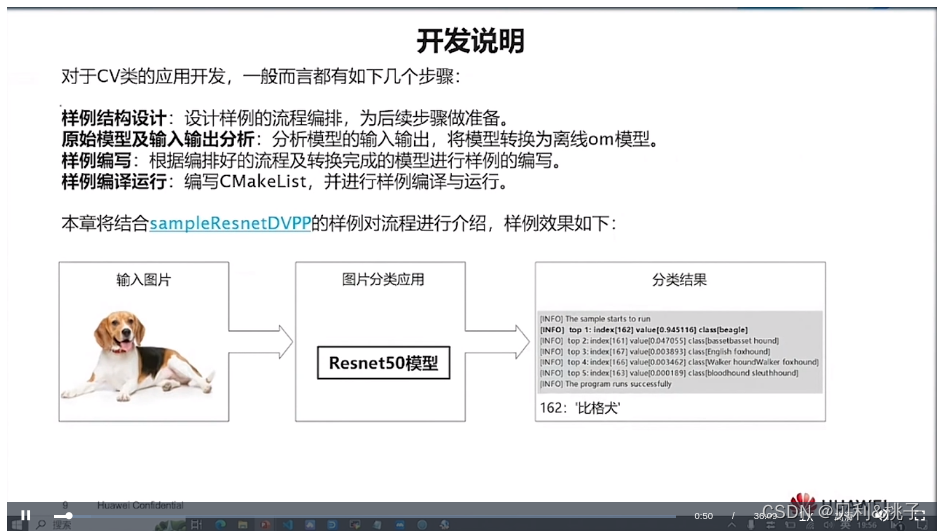
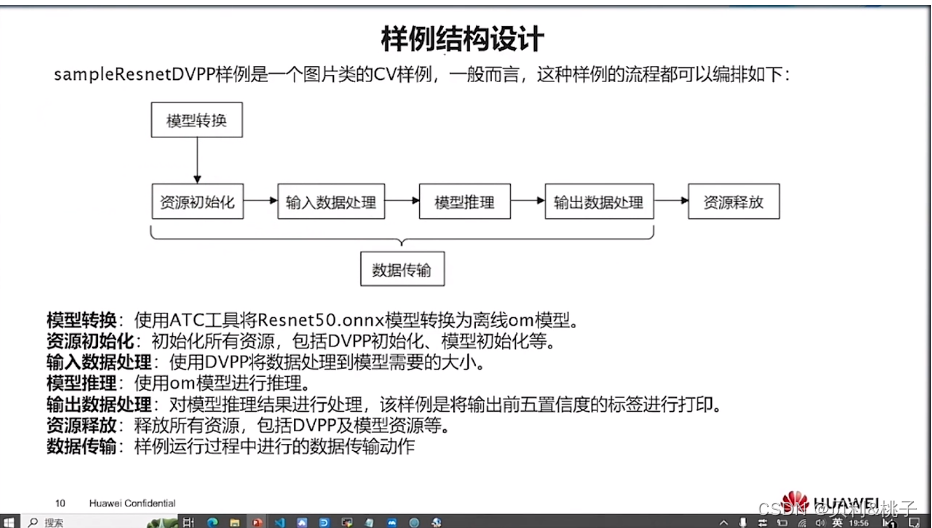

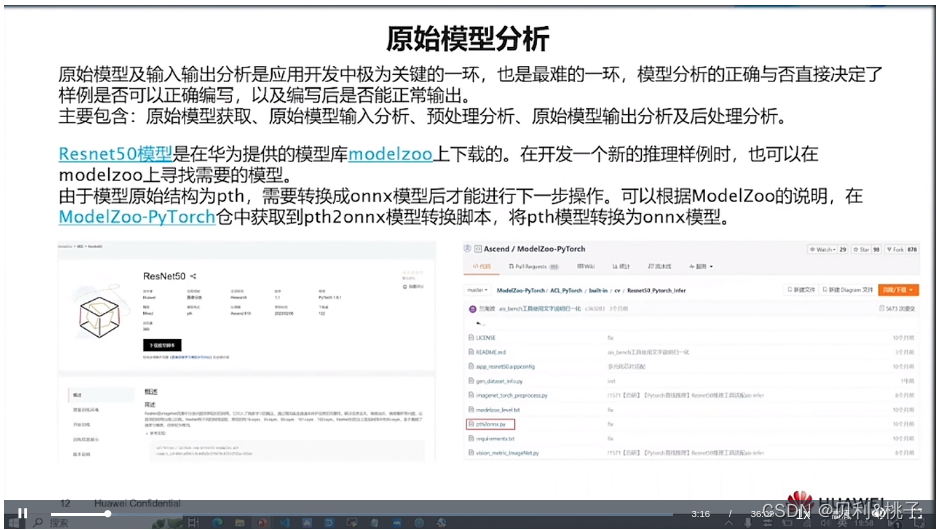
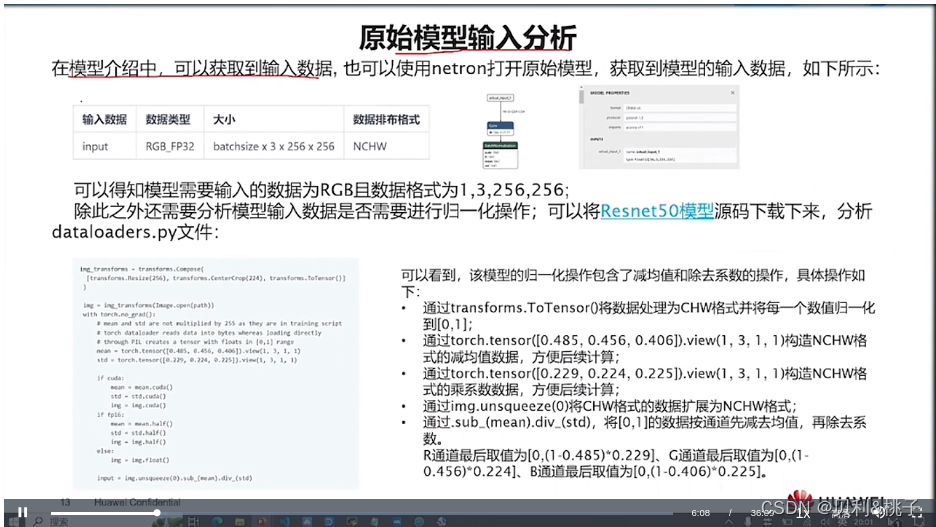






- C&C++语言
-
- 更高效的开发、测试和部署:
- 高可用性和可靠性:
- 支持多种精度计算:
- 高算力和高能效:
- 灵活性和可扩展性:







