代码解析
参考资料
- 建议大家在阅读前有一定Transformer模型基础,可以先看看Transformer论文,论文下载链接
- 阅读Informer时序模型论文,重点关注作者针对Transformer模型做了哪些改进,论文下载链接
- Informer时序模型Github地址,数据没有包含在项目中,需要自行下载,这里提供下载地址 (包含代码文件和数据)
参数设定模块(main_informer)
- 值得注意的是'--model'、'--data'参数需要去掉required参数,否则运行代码可能会报'--model'、'--data'错误
- 修改完参数后运行该模块,保证代码运行不报错的情况下进行debug
参数含义
- 下面是各参数含义(注释)
# 选择模型(去掉required参数,选择informer模型) parser.add_argument('--model', type=str, default='informer',help='model of experiment, options: [informer, informerstack, informerlight(TBD)]') # 数据选择(去掉required参数) parser.add_argument('--data', type=str, default='WTH', help='data') # 数据上级目录 parser.add_argument('--root_path', type=str, default='./data/', help='root path of the data file') # 数据名称 parser.add_argument('--data_path', type=str, default='WTH.csv', help='data file') # 预测类型(多变量预测、单变量预测、多元预测单变量) parser.add_argument('--features', type=str, default='M', help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate') # 数据中要预测的标签列 parser.add_argument('--target', type=str, default='OT', help='target feature in S or MS task') # 数据重采样(h:小时) parser.add_argument('--freq', type=str, default='h', help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h') # 模型保存位置 parser.add_argument('--checkpoints', type=str, default='./checkpoints/', help='location of model checkpoints') # 输入序列长度 parser.add_argument('--seq_len', type=int, default=96, help='input sequence length of Informer encoder') # 先验序列长度 parser.add_argument('--label_len', type=int, default=48, help='start token length of Informer decoder') # 预测序列长度 parser.add_argument('--pred_len', type=int, default=24, help='prediction sequence length') # Informer decoder input: concat[start token series(label_len), zero padding series(pred_len)] # 编码器default参数为特征列数 parser.add_argument('--enc_in', type=int, default=7, help='encoder input size') # 解码器default参数与编码器相同 parser.add_argument('--dec_in', type=int, default=7, help='decoder input size') parser.add_argument('--c_out', type=int, default=7, help='output size') # 模型宽度 parser.add_argument('--d_model', type=int, default=512, help='dimension of model') # 多头注意力机制头数 parser.add_argument('--n_heads', type=int, default=8, help='num of heads') # 模型中encoder层数 parser.add_argument('--e_layers', type=int, default=2, help='num of encoder layers') # 模型中decoder层数 parser.add_argument('--d_layers', type=int, default=1, help='num of decoder layers') # 网络架构循环次数 parser.add_argument('--s_layers', type=str, default='3,2,1', help='num of stack encoder layers') # 全连接层神经元个数 parser.add_argument('--d_ff', type=int, default=2048, help='dimension of fcn') # 采样因子数 parser.add_argument('--factor', type=int, default=5, help='probsparse attn factor') # 1D卷积核 parser.add_argument('--padding', type=int, default=0, help='padding type') # 是否需要序列长度衰减 parser.add_argument('--distil', action='store_false', help='whether to use distilling in encoder, using this argument means not using distilling', default=True) # 神经网络正则化操作 parser.add_argument('--dropout', type=float, default=0.05, help='dropout') # attention计算方式 parser.add_argument('--attn', type=str, default='prob', help='attention used in encoder, options:[prob, full]') # 时间特征编码方式 parser.add_argument('--embed', type=str, default='timeF', help='time features encoding, options:[timeF, fixed, learned]') # 激活函数 parser.add_argument('--activation', type=str, default='gelu',help='activation') # 是否输出attention parser.add_argument('--output_attention', action='store_true', help='whether to output attention in ecoder') # 是否需要预测 parser.add_argument('--do_predict', action='store_true', help='whether to predict unseen future data') parser.add_argument('--mix', action='store_false', help='use mix attention in generative decoder', default=True) # 数据读取 parser.add_argument('--cols', type=str, nargs='+', help='certain cols from the data files as the input features') # 多核训练(Windows下选择0,否则容易报错) parser.add_argument('--num_workers', type=int, default=0, help='data loader num workers') # 训练轮数 parser.add_argument('--itr', type=int, default=2, help='experiments times') # 训练迭代次数 parser.add_argument('--train_epochs', type=int, default=6, help='train epochs') # mini-batch大小 parser.add_argument('--batch_size', type=int, default=32, help='batch size of train input data') # 早停策略 parser.add_argument('--patience', type=int, default=3, help='early stopping patience') # 学习率 parser.add_argument('--learning_rate', type=float, default=0.0001, help='optimizer learning rate') parser.add_argument('--des', type=str, default='test',help='exp description') # loss计算方式 parser.add_argument('--loss', type=str, default='mse',help='loss function') # 学习率衰减参数 parser.add_argument('--lradj', type=str, default='type1',help='adjust learning rate') # 是否使用自动混合精度训练 parser.add_argument('--use_amp', action='store_true', help='use automatic mixed precision training', default=False) # 是否反转输出结果 parser.add_argument('--inverse', action='store_true', help='inverse output data', default=False) # 是否使用GPU加速训练 parser.add_argument('--use_gpu', type=bool, default=True, help='use gpu') parser.add_argument('--gpu', type=int, default=0, help='gpu') # GPU分布式训练 parser.add_argument('--use_multi_gpu', action='store_true', help='use multiple gpus', default=False) # 多GPU训练 parser.add_argument('--devices', type=str, default='0,1,2,3',help='device ids of multile gpus') # 取参数值 args = parser.parse_args() # 获取GPU args.use_gpu = True if torch.cuda.is_available() and args.use_gpu else False数据文件参数
- 因为用的是笔记本电脑,这里只能用最小的数据集进行试验,也就是下面的WTH数据集
# 数据参数 data_parser = { 'ETTh1':{'data':'ETTh1.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]}, 'ETTh2':{'data':'ETTh2.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]}, 'ETTm1':{'data':'ETTm1.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]}, 'ETTm2':{'data':'ETTm2.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]}, # data:数据文件名,T:标签列,M:预测变量数(如果要预测12个特征,则为[12,12,12]), 'WTH':{'data':'WTH.csv','T':'WetBulbCelsius','M':[12,12,12],'S':[1,1,1],'MS':[12,12,1]}, 'ECL':{'data':'ECL.csv','T':'MT_320','M':[321,321,321],'S':[1,1,1],'MS':[321,321,1]}, 'Solar':{'data':'solar_AL.csv','T':'POWER_136','M':[137,137,137],'S':[1,1,1],'MS':[137,137,1]}, }- 下面是模型训练函数,这里不进行注释了
数据处理模块(data_loader)
- 从main_informer.py文件中exp.train(setting),train方法进入exp_informer.py文件,在_get_data中找到WTH数据处理方法
data_dict = { 'ETTh1':Dataset_ETT_hour, 'ETTh2':Dataset_ETT_hour, 'ETTm1':Dataset_ETT_minute, 'ETTm2':Dataset_ETT_minute, 'WTH':Dataset_Custom, 'ECL':Dataset_Custom, 'Solar':Dataset_Custom, 'custom':Dataset_Custom,}- 可以看到WTH数据处理方法为Dataset_Custom,我们进入data_loader.py文件,找到Dataset_Custom类
- __init__主要用于传各类参数,这里不过多赘述,主要对__read_data__进行说明
def __read_data__(self): # 数据标准化 self.scaler = StandardScaler() # 利用pandas将数据读入 df_raw = pd.read_csv(os.path.join(self.root_path, self.data_path)) # 如果指定了排除项 if self.cols: cols=self.cols.copy() # 移除标签列 cols.remove(self.target) else: # 提取数据列名;移除标签列;移除日期列 cols = list(df_raw.columns); cols.remove(self.target); cols.remove('date') # 日期列+特征列+标签列(即:调整列顺序) df_raw = df_raw[['date']+cols+[self.target]] # 划分训练集 num_train = int(len(df_raw)*0.7) # 划分测试集 num_test = int(len(df_raw)*0.2) # 划分验证集 num_vali = len(df_raw) - num_train - num_test # 计算数据起始点 border1s = [0, num_train-self.seq_len, len(df_raw)-num_test-self.seq_len] border2s = [num_train, num_train+num_vali, len(df_raw)] border1 = border1s[self.set_type] border2 = border2s[self.set_type] # 若预测类型为M(多特征预测多特征)或MS(多特征预测单特征) if self.features=='M' or self.features=='MS': # 取除日期列的其他所有列 cols_data = df_raw.columns[1:] df_data = df_raw[cols_data] # 若预测类型为S(单特征预测单特征) elif self.features=='S': # 取特征列 df_data = df_raw[[self.target]] # 将数据进行归一化 if self.scale: train_data = df_data[border1s[0]:border2s[0]] self.scaler.fit(train_data.values) data = self.scaler.transform(df_data.values) else: data = df_data.values # 取日期列 df_stamp = df_raw[['date']][border1:border2] # 利用pandas将数据转换为日期格式 df_stamp['date'] = pd.to_datetime(df_stamp.date) # 构建时间特征 data_stamp = time_features(df_stamp, timeenc=self.timeenc, freq=self.freq) self.data_x = data[border1:border2] if self.inverse: self.data_y = df_data.values[border1:border2] else: # 取数据特征列 self.data_y = data[border1:border2] self.data_stamp = data_stamp- 需要注意的是time_features函数,用来提取日期特征,比如't':['month','day','weekday','hour','minute'],表示提取月,天,周,小时,分钟。可以打开timefeatures.py
文件进行查阅
- 同样的,对__getitem__进行说明
def __getitem__(self, index): # 随机取得标签 s_begin = index # 训练区间 s_end = s_begin + self.seq_len # 有标签区间+无标签区间(预测时间步长) r_begin = s_end - self.label_len r_end = r_begin + self.label_len + self.pred_len # 取训练数据 seq_x = self.data_x[s_begin:s_end] if self.inverse: seq_y = np.concatenate([self.data_x[r_begin:r_begin+self.label_len], self.data_y[r_begin+self.label_len:r_end]], 0) else: # 取有标签区间+无标签区间(预测时间步长)数据 seq_y = self.data_y[r_begin:r_end] # 取训练数据对应时间特征 seq_x_mark = self.data_stamp[s_begin:s_end] # 取有标签区间+无标签区间(预测时间步长)对应时间特征 seq_y_mark = self.data_stamp[r_begin:r_end] return seq_x, seq_y, seq_x_mark, seq_y_mark def __len__(self): # 返回数据长度 return len(self.data_x) - self.seq_len- self.pred_len + 1 def inverse_transform(self, data): return self.scaler.inverse_transform(data)Informer模型架构(model)
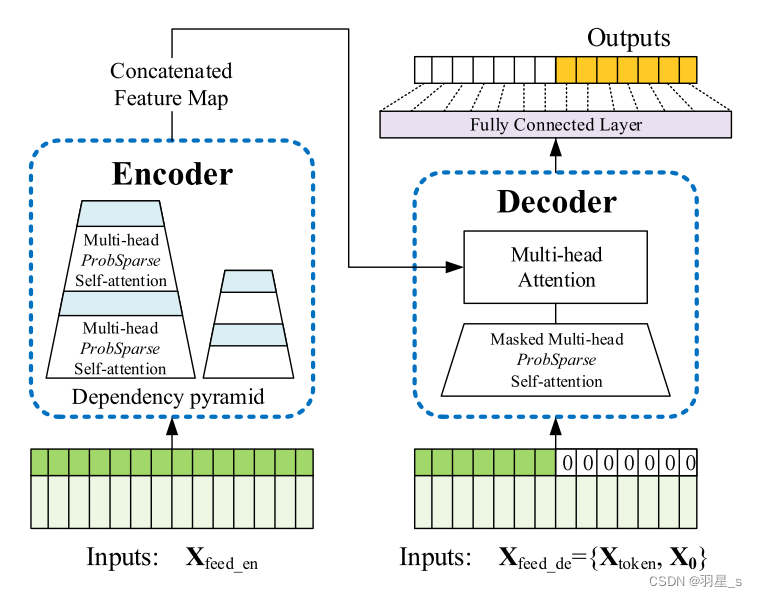
- 这里贴上Informer模型论文中的结构图,方便大家对照理解。
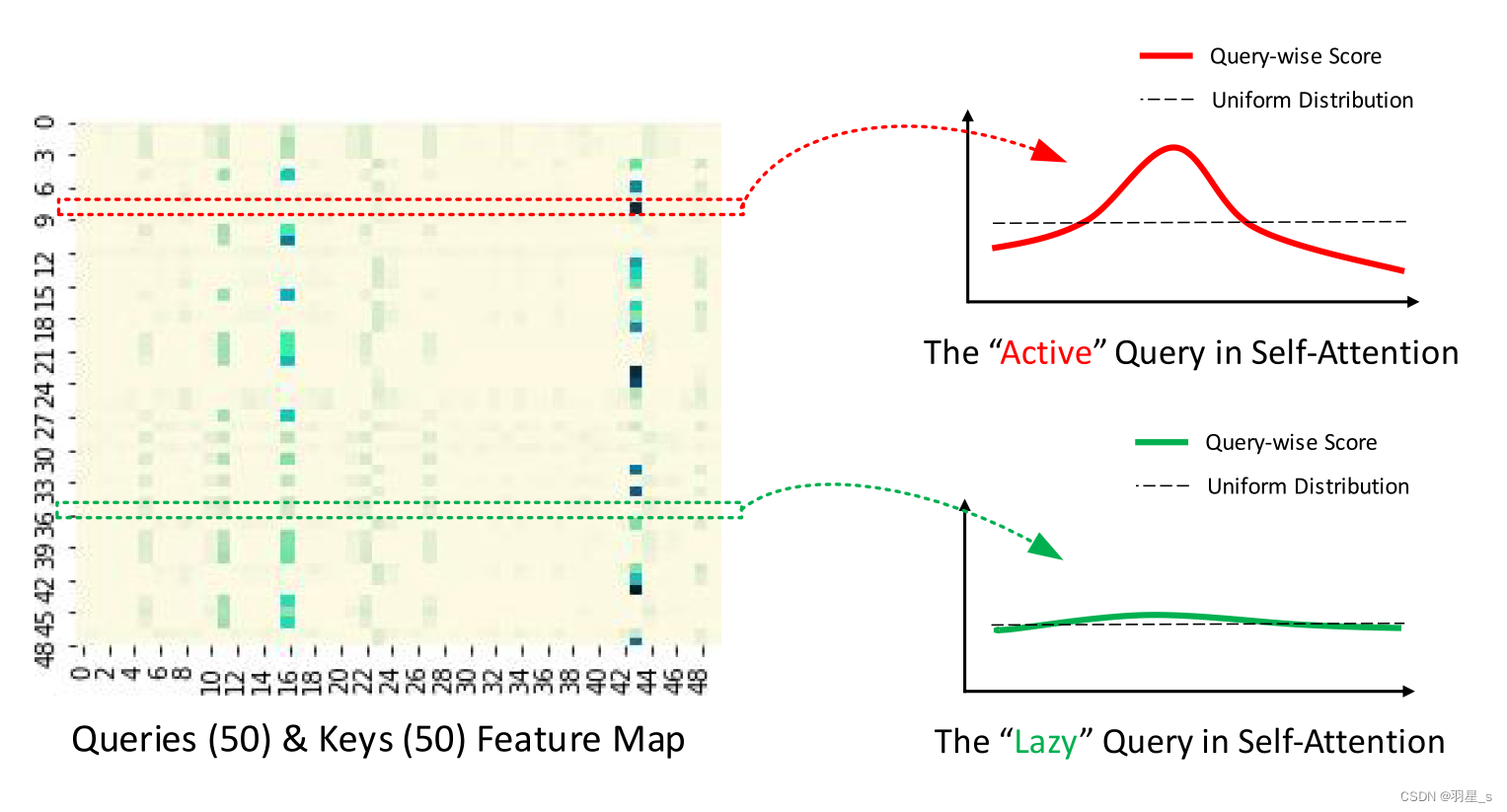
- K值选取原因与筛选方法
- 先进入exp_informer.py文件,train函数中包含有网络架构函数。
def train(self, setting): # 数据加载器 train_data, train_loader = self._get_data(flag = 'train') vali_data, vali_loader = self._get_data(flag = 'val') test_data, test_loader = self._get_data(flag = 'test') path = os.path.join(self.args.checkpoints, setting) if not os.path.exists(path): os.makedirs(path) # 记录时间 time_now = time.time() # 训练steps train_steps = len(train_loader) # 早停策略 early_stopping = EarlyStopping(patience=self.args.patience, verbose=True) # 优化器Adam model_optim = self._select_optimizer() # 损失函数(MSE) criterion = self._select_criterion() # 分布式训练(windows一般不推荐) if self.args.use_amp: scaler = torch.cuda.amp.GradScaler() # 训练次数 for epoch in range(self.args.train_epochs): iter_count = 0 train_loss = [] self.model.train() epoch_time = time.time() for i, (batch_x,batch_y,batch_x_mark,batch_y_mark) in enumerate(train_loader): iter_count += 1 # 梯度归零 model_optim.zero_grad() # 训练模型(网络架构) pred, true = self._process_one_batch( train_data, batch_x, batch_y, batch_x_mark, batch_y_mark) # 计算损失 loss = criterion(pred, true) # 加入数组 train_loss.append(loss.item()) # 输出信息 if (i+1) % 100==0: print("\titers: {0}, epoch: {1} | loss: {2:.7f}".format(i + 1, epoch + 1, loss.item())) speed = (time.time()-time_now)/iter_count left_time = speed*((self.args.train_epochs - epoch)*train_steps - i) print('\tspeed: {:.4f}s/iter; left time: {:.4f}s'.format(speed, left_time)) iter_count = 0 time_now = time.time() if self.args.use_amp: scaler.scale(loss).backward() scaler.step(model_optim) scaler.update() else: # 反向传播 loss.backward() # 更新梯度 model_optim.step() # 打印时间信息 print("Epoch: {} cost time: {}".format(epoch+1, time.time()-epoch_time)) train_loss = np.average(train_loss) vali_loss = self.vali(vali_data, vali_loader, criterion) test_loss = self.vali(test_data, test_loader, criterion) # 打印损失信息 print("Epoch: {0}, Steps: {1} | Train Loss: {2:.7f} Vali Loss: {3:.7f} Test Loss: {4:.7f}".format( epoch + 1, train_steps, train_loss, vali_loss, test_loss)) # 早停策略 early_stopping(vali_loss, self.model, path) if early_stopping.early_stop: print("Early stopping") break adjust_learning_rate(model_optim, epoch+1, self.args) # 保存模型 best_model_path = path+'/'+'checkpoint.pth' # 导入模型 self.model.load_state_dict(torch.load(best_model_path)) return self.model- 注意模型训练那一块_process_one_batch,进入该方法
def _process_one_batch(self, dataset_object, batch_x, batch_y, batch_x_mark, batch_y_mark): # 将数据集放入GPU中 batch_x = batch_x.float().to(self.device) batch_y = batch_y.float() batch_x_mark = batch_x_mark.float().to(self.device) batch_y_mark = batch_y_mark.float().to(self.device) # decoder输入 if self.args.padding==0: # 创建一个全0数组,维度为batch,预测序列长度,特征数,本例中为[32,24,12] dec_inp = torch.zeros([batch_y.shape[0], self.args.pred_len, batch_y.shape[-1]]).float() elif self.args.padding==1: dec_inp = torch.ones([batch_y.shape[0], self.args.pred_len, batch_y.shape[-1]]).float() # 维度变为[32,72,12](72 = 24 + 48),48是预测中有标签的数据量 dec_inp = torch.cat([batch_y[:,:self.args.label_len,:], dec_inp], dim=1).float().to(self.device) # encoder - decoder if self.args.use_amp: with torch.cuda.amp.autocast(): if self.args.output_attention: outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0] else: outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark) else: if self.args.output_attention: outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0] else: # 运行到这一步,model中包含了网络架构 # output维度[batch,预测序列长度,预测特征数] outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark) if self.args.inverse: outputs = dataset_object.inverse_transform(outputs) # 如果预测类型为多特征预测单特征(取结果最后一列) f_dim = -1 if self.args.features=='MS' else 0 batch_y = batch_y[:,-self.args.pred_len:,f_dim:].to(self.device) return outputs, batch_y- 可以看到outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark),model中包含Informer的核心架构(也是最重要的部分)
- 打开model.py文件,找到Informer类,直接看forward
def forward(self, x_enc, x_mark_enc, x_dec, x_mark_dec, enc_self_mask=None, dec_self_mask=None, dec_enc_mask=None): # x_enc[batch,序列长度,特征列],x_mark_enc[batch,序列长度,时间特征列] # x_enc.shape:(32,96,12),x_mark_enc.shape:(32,96,4) enc_out = self.enc_embedding(x_enc, x_mark_enc) # enc_self_mask是数据中需要忽略的样本,本项目中为空 enc_out, attns = self.encoder(enc_out, attn_mask=enc_self_mask) # 解码器embedding操作 # x_dec维度[batch,有标签+无标签序列长度,特征列](32,72=48+24,12) dec_out = self.dec_embedding(x_dec, x_mark_dec) # 解码器decoder操作 dec_out = self.decoder(dec_out, enc_out, x_mask=dec_self_mask, cross_mask=dec_enc_mask) # 利用全连接层输出结果512-->12 dec_out = self.projection(dec_out) # dec_out = self.end_conv1(dec_out) # dec_out = self.end_conv2(dec_out.transpose(2,1)).transpose(1,2) if self.output_attention: return dec_out[:,-self.pred_len:,:], attns else: # 截断,只取后面24个需要预测的 return dec_out[:,-self.pred_len:,:] # [B, L, D]编码器Embedding操作
- Embedding操作,在embed.py文件中
class DataEmbedding(nn.Module): def __init__(self, c_in, d_model, embed_type='fixed', freq='h', dropout=0.1): super(DataEmbedding, self).__init__() self.value_embedding = TokenEmbedding(c_in=c_in, d_model=d_model) self.position_embedding = PositionalEmbedding(d_model=d_model) self.temporal_embedding = TemporalEmbedding(d_model=d_model, embed_type=embed_type, freq=freq) if embed_type!='timeF' else TimeFeatureEmbedding(d_model=d_model, embed_type=embed_type, freq=freq) self.dropout = nn.Dropout(p=dropout) def forward(self, x, x_mark): # 12个特征列利用卷积层映射为512 + position_embedding + 4个时间特征利用全连接层映射为512 x = self.value_embedding(x) + self.position_embedding(x) + self.temporal_embedding(x_mark) # 输出正则化后的embedding return self.dropout(x)Encoder模块
- Encoder模块,在encoder.py文件中
class Encoder(nn.Module): def __init__(self, attn_layers, conv_layers=None, norm_layer=None): super(Encoder, self).__init__() self.attn_layers = nn.ModuleList(attn_layers) self.conv_layers = nn.ModuleList(conv_layers) if conv_layers is not None else None self.norm = norm_layer def forward(self, x, attn_mask=None): # x [B, L, D] attns = [] if self.conv_layers is not None: for attn_layer, conv_layer in zip(self.attn_layers, self.conv_layers): # 遍历注意力架构层 x, attn = attn_layer(x, attn_mask=attn_mask) # 对x做maxpool1d操作,将512-->256 # 也就是结构中的金字塔,为了加速模型训练提出 x = conv_layer(x) attns.append(attn) # # 遍历注意力架构层 x, attn = self.attn_layers[-1](x, attn_mask=attn_mask) attns.append(attn) else: for attn_layer in self.attn_layers: x, attn = attn_layer(x, attn_mask=attn_mask) attns.append(attn) if self.norm is not None: # 执行标准化操作 x = self.norm(x) return x, attns- 进入EncoderLayer类,找到注意力计算架构
class EncoderLayer(nn.Module): def __init__(self, attention, d_model, d_ff=None, dropout=0.1, activation="relu"): super(EncoderLayer, self).__init__() d_ff = d_ff or 4*d_model self.attention = attention self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1) self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.dropout = nn.Dropout(dropout) self.activation = F.relu if activation == "relu" else F.gelu def forward(self, x, attn_mask=None): # 传入3个x,分别用于计算Q、K、V new_x, attn = self.attention( x, x, x, attn_mask = attn_mask ) # 残差连接 x = x + self.dropout(new_x) y = x = self.norm1(x) y = self.dropout(self.activation(self.conv1(y.transpose(-1,1)))) y = self.dropout(self.conv2(y).transpose(-1,1)) return self.norm2(x+y), attn- 注意代码中的new_x, attn = self.attention(x, x, x,attn_mask = attn_mask)
注意力层
- 注意力层在attn.py文件中,找到AttentionLayer类
class AttentionLayer(nn.Module): def __init__(self, attention, d_model, n_heads, d_keys=None, d_values=None, mix=False): super(AttentionLayer, self).__init__() d_keys = d_keys or (d_model//n_heads) d_values = d_values or (d_model//n_heads) self.inner_attention = attention self.query_projection = nn.Linear(d_model, d_keys * n_heads) self.key_projection = nn.Linear(d_model, d_keys * n_heads) self.value_projection = nn.Linear(d_model, d_values * n_heads) self.out_projection = nn.Linear(d_values * n_heads, d_model) self.n_heads = n_heads self.mix = mix def forward(self, queries, keys, values, attn_mask): # 取出batch,序列长度,特征数12(即B=32,L=96,_=12) B, L, _ = queries.shape # 同样的S=96 _, S, _ = keys.shape # 多头注意力机制,这里为8 H = self.n_heads # 通过全连接层将特征512-->512,映射到Q,K,V # 512是在进行Embedding后特征数量 # 同时维度变为(batch,序列长度,多头注意力机制,自动计算) queries = self.query_projection(queries).view(B, L, H, -1) keys = self.key_projection(keys).view(B, S, H, -1) values = self.value_projection(values).view(B, S, H, -1) # 计算注意力 out, attn = self.inner_attention( queries, keys, values, attn_mask ) if self.mix: out = out.transpose(2,1).contiguous() # 维度batch,序列长度,自动计算值 out = out.view(B, L, -1) # 连接全连接512-->512 return self.out_projection(out), attn- 注意代码中self.inner_attention,跳转到ProbAttention类
- 其中_prob_QK用于选取Q、K是非常模型核心,要认真读,贴一下公式:
M ‾ ( q i , k ) = m a x j { q i k j T d } − 1 L k ∑ j = 1 L k q i k j T d \overline{M}_{(q_i,k)} = \mathop{max} \limits_{j} \{\frac{q_ik_j^{T}}{\sqrt{d}}\}-\frac{1}{L_{k}}\sum^{L_k}_{j=1}\frac{q_ik_j^{T}}{\sqrt{d}} M(qi,k)=jmax{d qikjT}−Lk1j=1∑Lkd qikjT
- _get_initial_context计算初始V值,_update_context更新重要Q的V值
class ProbAttention(nn.Module): def __init__(self, mask_flag=True, factor=5, scale=None, attention_dropout=0.1, output_attention=False): super(ProbAttention, self).__init__() self.factor = factor self.scale = scale self.mask_flag = mask_flag self.output_attention = output_attention self.dropout = nn.Dropout(attention_dropout) def _prob_QK(self, Q, K, sample_k, n_top): # n_top: c*ln(L_q) # 维度[batch,头数,序列长度,自动计算值] B, H, L_K, E = K.shape _, _, L_Q, _ = Q.shape # 添加一个维度,相当于复制维度,当前维度为[batch,头数,序列长度,序列长度,自动计算值] K_expand = K.unsqueeze(-3).expand(B, H, L_Q, L_K, E) # 随机取样,取值范围0~96,取样维度为[序列长度,25] index_sample = torch.randint(L_K, (L_Q, sample_k)) # real U = U_part(factor*ln(L_k))*L_q # 96个Q与25个K做计算,维度为[batch,头数,Q个数,K个数,自动计算值] K_sample = K_expand[:, :, torch.arange(L_Q).unsqueeze(1), index_sample, :] # 矩阵重组,维度为[batch,头数,Q个数,K个数] Q_K_sample = torch.matmul(Q.unsqueeze(-2), K_sample.transpose(-2, -1)).squeeze(-2) # 分别取到96个Q中每一个Q跟K关系最大的值 M = Q_K_sample.max(-1)[0] - torch.div(Q_K_sample.sum(-1), L_K) # 在96个Q中选出前25个 M_top = M.topk(n_top, sorted=False)[1] # 取出Q特征,维度为[batch,头数,Q个数,自动计算值] Q_reduce = Q[torch.arange(B)[:, None, None], torch.arange(H)[None, :, None], M_top, :] # factor*ln(L_q) Q_K = torch.matmul(Q_reduce, K.transpose(-2, -1)) # factor*ln(L_q)*L_k return Q_K, M_top # 计算V值 def _get_initial_context(self, V, L_Q): # 取出batch,头数,序列长度,自动计算值 B, H, L_V, D = V.shape if not self.mask_flag: # 对25个Q以外其他Q的V值,使用平均值(让其继续平庸下去) V_sum = V.mean(dim=-2) # 先把96个V全部使用平均值代替 contex = V_sum.unsqueeze(-2).expand(B, H, L_Q, V_sum.shape[-1]).clone() else: # use mask assert(L_Q == L_V) # requires that L_Q == L_V, i.e. for self-attention only contex = V.cumsum(dim=-2) return contex # 更新25个V值 def _update_context(self, context_in, V, scores, index, L_Q, attn_mask): B, H, L_V, D = V.shape if self.mask_flag: attn_mask = ProbMask(B, H, L_Q, index, scores, device=V.device) scores.masked_fill_(attn_mask.mask, -np.inf) # 计算softmax值 attn = torch.softmax(scores, dim=-1) # 对25个Q更新V,其他仍然为平均值 context_in[torch.arange(B)[:, None, None], torch.arange(H)[None, :, None], index, :] = torch.matmul(attn, V).type_as(context_in) if self.output_attention: attns = (torch.ones([B, H, L_V, L_V])/L_V).type_as(attn).to(attn.device) attns[torch.arange(B)[:, None, None], torch.arange(H)[None, :, None], index, :] = attn return (context_in, attns) else: return (context_in, None) def forward(self, queries, keys, values, attn_mask): # 取出batch,序列长度,头数,自动计算值 B, L_Q, H, D = queries.shape # 取出序列长度(相当于96个Q,96个K) _, L_K, _, _ = keys.shape # 维度转置操作,维度变为(batch,头数,序列长度,自动计算值) queries = queries.transpose(2,1) keys = keys.transpose(2,1) values = values.transpose(2,1) # 选取K的个数,模型核心,用于加速 # factor为常数5,可以自行修改,其值越大,计算成本越高 U_part = self.factor * np.ceil(np.log(L_K)).astype('int').item() # c*ln(L_k) u = self.factor * np.ceil(np.log(L_Q)).astype('int').item() # c*ln(L_q) U_part = U_part if U_part 0.396307). Saving model ... Updating learning rate to 5e-05 iters: 100, epoch: 3 | loss: 0.2556470 speed: 12.6569s/iter; left time: 37375.7115s iters: 200, epoch: 3 | loss: 0.2456252 speed: 4.7655s/iter; left time: 13596.0810s iters: 300, epoch: 3 | loss: 0.2562804 speed: 4.7336s/iter; left time: 13031.4940s iters: 400, epoch: 3 | loss: 0.2049552 speed: 4.7622s/iter; left time: 12634.1883s iters: 500, epoch: 3 | loss: 0.2604980 speed: 4.7524s/iter; left time: 12132.7789s iters: 600, epoch: 3 | loss: 0.2539216 speed: 4.7413s/iter; left time: 11630.3915s iters: 700, epoch: 3 | loss: 0.2098076 speed: 4.7394s/iter; left time: 11151.7416s Epoch: 3 cost time: 3628.159082174301 Epoch: 3, Steps: 763 | Train Loss: 0.2486252 Vali Loss: 0.4155475 Test Loss: 0.3301197 EarlyStopping counter: 1 out of 3 Updating learning rate to 2.5e-05 iters: 100, epoch: 4 | loss: 0.2175551 speed: 12.6253s/iter; left time: 27649.4546s iters: 200, epoch: 4 | loss: 0.2459734 speed: 4.7335s/iter; left time: 9892.9213s iters: 300, epoch: 4 | loss: 0.2354426 speed: 4.7546s/iter; left time: 9461.6300s iters: 400, epoch: 4 | loss: 0.2267139 speed: 4.7719s/iter; left time: 9018.9749s iters: 500, epoch: 4 | loss: 0.2379844 speed: 4.8038s/iter; left time: 8598.7446s iters: 600, epoch: 4 | loss: 0.2434178 speed: 4.7608s/iter; left time: 8045.7994s iters: 700, epoch: 4 | loss: 0.2231207 speed: 4.7765s/iter; left time: 7594.6586s Epoch: 4 cost time: 3649.547614812851 Epoch: 4, Steps: 763 | Train Loss: 0.2224283 Vali Loss: 0.4230270 Test Loss: 0.3334258 EarlyStopping counter: 2 out of 3 Updating learning rate to 1.25e-05 iters: 100, epoch: 5 | loss: 0.1837259 speed: 12.7564s/iter; left time: 18203.3974s iters: 200, epoch: 5 | loss: 0.1708880 speed: 4.7804s/iter; left time: 6343.6200s iters: 300, epoch: 5 | loss: 0.2529005 speed: 4.7426s/iter; left time: 5819.1675s iters: 400, epoch: 5 | loss: 0.2434390 speed: 4.7388s/iter; left time: 5340.6568s iters: 500, epoch: 5 | loss: 0.2078404 speed: 4.7515s/iter; left time: 4879.7921s iters: 600, epoch: 5 | loss: 0.2372987 speed: 4.7986s/iter; left time: 4448.2748s iters: 700, epoch: 5 | loss: 0.2022571 speed: 4.7718s/iter; left time: 3946.2739s Epoch: 5 cost time: 3636.7107157707214 Epoch: 5, Steps: 763 | Train Loss: 0.2088229 Vali Loss: 0.4305894 Test Loss: 0.3341273 EarlyStopping counter: 3 out of 3 Early stopping >>>>>>>testing : informer_WTH_ftM_sl96_ll48_pl24_dm512_nh8_el2_dl1_df2048_atprob_fc5_ebtimeF_dtTrue_mxTrue_test_0> train 24425 val 3485 test 6989 iters: 100, epoch: 1 | loss: 0.4508476 speed: 4.7396s/iter; left time: 21228.7904s iters: 200, epoch: 1 | loss: 0.3859568 speed: 4.7742s/iter; left time: 20906.0895s iters: 300, epoch: 1 | loss: 0.3749838 speed: 4.7690s/iter; left time: 20406.5500s iters: 400, epoch: 1 | loss: 0.3673764 speed: 4.8070s/iter; left time: 20088.4627s iters: 500, epoch: 1 | loss: 0.3068828 speed: 4.7643s/iter; left time: 19433.6961s iters: 600, epoch: 1 | loss: 0.4173551 speed: 4.7621s/iter; left time: 18948.4516s iters: 700, epoch: 1 | loss: 0.2720438 speed: 4.7609s/iter; left time: 18467.4719s Epoch: 1 cost time: 3639.997560977936 Epoch: 1, Steps: 763 | Train Loss: 0.3788956 Vali Loss: 0.3947107 Test Loss: 0.3116618 Validation loss decreased (inf --> 0.394711). Saving model ... Updating learning rate to 0.0001 iters: 100, epoch: 2 | loss: 0.3547252 speed: 12.6113s/iter; left time: 46863.7093s iters: 200, epoch: 2 | loss: 0.3236437 speed: 4.7504s/iter; left time: 17177.4475s iters: 300, epoch: 2 | loss: 0.2898968 speed: 4.7720s/iter; left time: 16778.2666s iters: 400, epoch: 2 | loss: 0.3107039 speed: 4.7412s/iter; left time: 16195.8892s iters: 500, epoch: 2 | loss: 0.2816701 speed: 4.7244s/iter; left time: 15666.2476s iters: 600, epoch: 2 | loss: 0.2226012 speed: 4.7348s/iter; left time: 15227.0618s iters: 700, epoch: 2 | loss: 0.2239729 speed: 4.8806s/iter; left time: 15208.0025s Epoch: 2 cost time: 3635.6160113811493 Epoch: 2, Steps: 763 | Train Loss: 0.2962583 Vali Loss: 0.4018708 Test Loss: 0.3213752 EarlyStopping counter: 1 out of 3 Updating learning rate to 5e-05 iters: 100, epoch: 3 | loss: 0.2407307 speed: 12.5584s/iter; left time: 37084.8281s iters: 200, epoch: 3 | loss: 0.2294409 speed: 5.1105s/iter; left time: 14580.3263s iters: 300, epoch: 3 | loss: 0.3180184 speed: 5.9484s/iter; left time: 16376.0364s iters: 400, epoch: 3 | loss: 0.2101320 speed: 5.7987s/iter; left time: 15384.0189s iters: 500, epoch: 3 | loss: 0.2701742 speed: 5.5463s/iter; left time: 14159.6749s iters: 600, epoch: 3 | loss: 0.2391748 speed: 4.8338s/iter; left time: 11857.4335s iters: 700, epoch: 3 | loss: 0.2280931 speed: 4.7718s/iter; left time: 11228.1147s Epoch: 3 cost time: 3975.2745430469513 Epoch: 3, Steps: 763 | Train Loss: 0.2494072 Vali Loss: 0.4189631 Test Loss: 0.3308771 EarlyStopping counter: 2 out of 3 Updating learning rate to 2.5e-05 iters: 100, epoch: 4 | loss: 0.2260314 speed: 12.7037s/iter; left time: 27821.0994s iters: 200, epoch: 4 | loss: 0.2191769 speed: 4.7906s/iter; left time: 10012.3575s iters: 300, epoch: 4 | loss: 0.2044496 speed: 4.7498s/iter; left time: 9452.0362s iters: 400, epoch: 4 | loss: 0.2167130 speed: 4.7545s/iter; left time: 8985.9758s iters: 500, epoch: 4 | loss: 0.2340788 speed: 4.7329s/iter; left time: 8471.8863s iters: 600, epoch: 4 | loss: 0.2137127 speed: 4.7037s/iter; left time: 7949.1748s iters: 700, epoch: 4 | loss: 0.1899967 speed: 4.7049s/iter; left time: 7480.8388s Epoch: 4 cost time: 3624.2080821990967 Epoch: 4, Steps: 763 | Train Loss: 0.2222918 Vali Loss: 0.4390603 Test Loss: 0.3350959 EarlyStopping counter: 3 out of 3 Early stopping >>>>>>>testing : informer_WTH_ftM_sl96_ll48_pl24_dm512_nh8_el2_dl1_df2048_atprob_fc5_ebtimeF_dtTrue_mxTrue_test_1
- 注意力层在attn.py文件中,找到AttentionLayer类
- 注意代码中的new_x, attn = self.attention(x, x, x,attn_mask = attn_mask)
- 进入EncoderLayer类,找到注意力计算架构
- Encoder模块,在encoder.py文件中
- Embedding操作,在embed.py文件中
- 注意模型训练那一块_process_one_batch,进入该方法
- 这里贴上Informer模型论文中的结构图,方便大家对照理解。
- 需要注意的是time_features函数,用来提取日期特征,比如't':['month','day','weekday','hour','minute'],表示提取月,天,周,小时,分钟。可以打开timefeatures.py
- 从main_informer.py文件中exp.train(setting),train方法进入exp_informer.py文件,在_get_data中找到WTH数据处理方法
- 下面是模型训练函数,这里不进行注释了
- 因为用的是笔记本电脑,这里只能用最小的数据集进行试验,也就是下面的WTH数据集
- 下面是各参数含义(注释)