目录
- Track1
- MOT17数据集
- 数据集介绍
- 训练集
- det
- gt
- COCO数据输入格式和YOLO数据输入格式和VOC数据输入格式
- 数据集可视化脚本
写在前面:本篇博文的目的是1. 理清MOT17数据集中文件及其内容的含义;2. COCO数据输入格式和YOLO数据输入格式和VOC数据输入格式的区别;3. 提供一个数据集可视化脚本,可以选中某个数据集,将该数据集中的groundtruth可视化在jpg上并生成视频播放。
Track1
数据格式的含义:
MOT17数据集
数据集下载: https://pan.baidu.com/s/1TtKOUdcACLXBzS9L3lmE0A?pwd=67ey 提取码: 67ey
参考博客:多目标跟踪数据集 :mot16、mot17数据集介绍以及多目标跟踪指标评测
数据集介绍
如下所示,该数据集中的文件结构如图所示。MOT17有21个训练集和21个检测集。
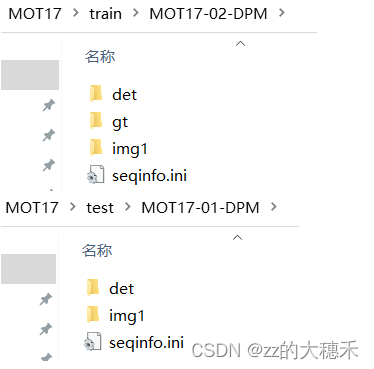
训练集
det
训练集中/det 文件夹中是针对检测的信息,该目录下只有一个det.txt文件,每行一个标注,代表一个检测的物体。
每一行标注的含义如下:第一个代表第几帧,第二个代表轨迹编号(因为检测结果只看检测框质量,不看id,故为id=-1。),bb开头的4个数代表物体框的左上角坐标及长宽。conf代表置信度,最后3个是MOT3D用到的内容,2D检测总是为-1.
, -1, , , , , , , ,
gt
训练集中/gt 文件夹中是针对追踪的信息,该目录下只有一个gt.txt文件,每行一个标注,代表一个检测的物体。
每一行标注的含义如下:第一个代表第几帧,第二个值为目标运动轨迹的ID号,bb开头的4个数代表物体框的左上角坐标及长宽,第7个值为目标轨迹是否进入考虑范围内的标志,0表示忽略,1表示active。第八个值为该轨迹对应的目标种类(种类见下面的表格中的label-ID对应情况),第九个值为box的visibility ratio,表示目标运动时被其他目标box包含/覆盖或者目标之间box边缘裁剪情况。
, , , , , , , ,
COCO数据输入格式和YOLO数据输入格式和VOC数据输入格式
参考博客:VOC/YOLO/COCO数据集格式转换及LabelImg/Labelme/精灵标注助手Colabeler标注工具介绍
VOC标签格式,标注的标签存储在xml文件
YOLO标签格式,标注的标签存储在txt文件中
COCO标签格式,标注的标签存储在json文件中
数据集可视化脚本
yolo格式的可视化
import cv2 import os label_path = '*.txt' pic_path = '*.bmp' img_gray = cv2.imread(pic_path) width = img_gray.shape[1] height = img_gray.shape[0] label = [] if os.path.exists(label_path): label = [] with open(label_path, 'r') as label_f: for line in label_f.readlines(): txt_list = line.split(' ') print('txt_list',txt_list) norm_x = float(txt_list[1]) norm_y = float(txt_list[2]) norm_w = float(txt_list[3]) norm_h = float(txt_list[4]) xmin = int(width * (norm_x - 0.5 * norm_w)) ymin = int(height * (norm_y - 0.5 * norm_h)) xmax = int(width * (norm_x + 0.5 * norm_w)) ymax = int(height * (norm_y + 0.5 * norm_h)) label.append(ymin) label.append(xmin) label.append(ymax) label.append(xmax) # [x1, x2, y1, y2]--> [212, 324, 296, 390] print('label',label) cv2.rectangle(img_gray, (label[1], label[0]), (label[3], label[2]), (120, 255, 120), 1) cv2.imshow('vis', img_gray) cv2.waitKey(0)