

随着互联网的迅猛发展,网络早已融进人们日常生活的方方面面,我们的个人隐私在互联网时代几乎已经不是秘密。在数据时代,如何保护自己的隐私呢?差分隐私又是什么?小编用一篇文章带领大家了解什么是差分隐私,背后技术原理以及如何在MindSpore中实现差分隐私。
如果大家看不懂也没关系,本周末晚八点(2020.6.7 20:00),MindSpore抖音直播间(抖音号:MindSpore梯度森林会)将会为大家详细讲解!
差分隐私的背景
20 世纪90 年代,美国马萨诸塞州发生了著名的隐私泄露事件。该州集团保险委员会(GIC)发布了“经过匿名化处理的”医疗数据,用于公共医学研究。在数据发布之前,为了防止隐私泄露问题,特地删除了数据中所有的个人敏感信息,例如身份证号、姓名、住址。然而在1997 年,卡内基梅隆大学的博士Latanya Sweeney将匿名化的GIC数据库(包含了每位患者生日、性别、邮编)与选民登记记录相连后,成功破解了这份匿名数据,并找到了当时的马萨诸塞州州长William Weld的医疗记录。
30年后,在2018年又发生了多起隐私数据泄露事件。Facebook用户隐私数据泄露被罚款16亿美元,圆通10亿快递信息泄露,万豪酒店5亿用户开房信息泄露,华住酒店5亿条用户数据疑似泄露,国泰航空940万乘客数据等等,隐私泄露问题层出不穷,隐私保护当是重中之重。
隐私保护的目的
我们希望,数据使用隐私保护技术后,可以安全发布,攻击者难以去匿名化,同时又最大限度的保留原始数据的整体信息,保持其研究价值。当前的研究热点主要在两个方面:
-
隐私保护技术能提供何种强度的保护,能够抵御何种强度的攻击;
-
如何在保护隐私的同时,最大限度地保留原数据中的有用信息。
差分隐私的基本概念
差分隐私是Dwork在2006年针对统计数据库的隐私泄露问题提出的一种新的隐私定义,目的是使得数据库查询结果对于数据集中单个记录的变化不敏感。简单来说,就是单个记录在或者不在数据集中,对于查询结果的影响微乎其微。那么攻击者就无法通过加入或减少一个记录,观察查询结果的变化来推测个体的具体信息。
举个例子,当不使用差分隐私技术时,我们查询A医院数据库,查询今日就诊的100个病人患病情况,返回10人患肺癌,同时查询99个病人患病情况,返回9个人患肺癌,那就可以推测剩下1个人张三患有肺癌,这个就暴露了张三的个人隐私了。使用差分隐私技术后,查询A医院的数据库,查询今日就诊的100个病人患病情况,返回肺癌得病率9.80%,查询今日就诊的99个病人患病情况,返回肺癌得病率9.81%,因此无法推测剩下1个人张三是否患有肺癌。
在机器学习中,机器学习算法一般是用大量数据并更新模型参数,学习数据特征。理想情况下,这些算法学习到一些泛化性较好的模型。然而,机器学习算法并不会区分通用特征还是个体特征。当我们用机器学习来完成某个重要的任务,例如肺癌诊断,发布的机器学习模型可能在无意中透露训练集中的个体特征,恶意攻击者可能从发布的模型获得关于张三的隐私信息,因此使用差分隐私技术来防止机器学习模型泄露个人隐私数据是十分必要的。
差分隐私的定义

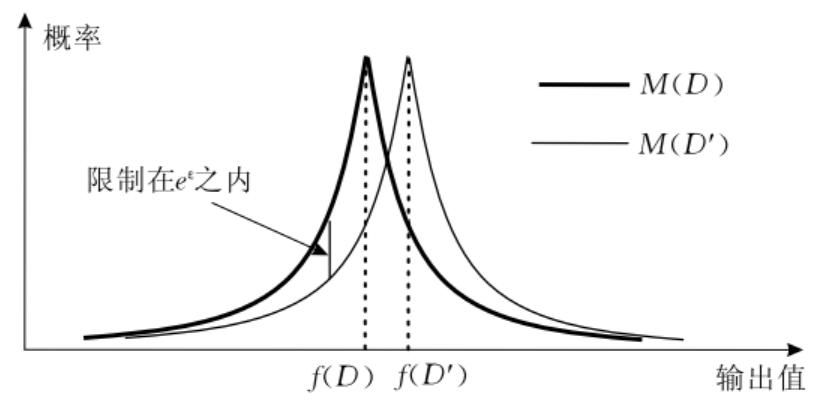
图1 随机算法在邻近数据集上的概率
差分隐私有两个重要的优点:
-
差分隐私假设攻击者能够获得除目标记录以外的所有其他记录信息,这些信息的总和可以理解为攻击者能够掌握的最大背景知识,在这个强大的假设下,差分隐私保护无需考虑攻击者所拥有的任何可能的背景知识。
-
差分隐私建立在严格的数学定义上,提供了可量化评估的方法。因此差分隐私保护技术是一种公认的较为严格和健壮的隐私保护机制。
如何实现差分隐私
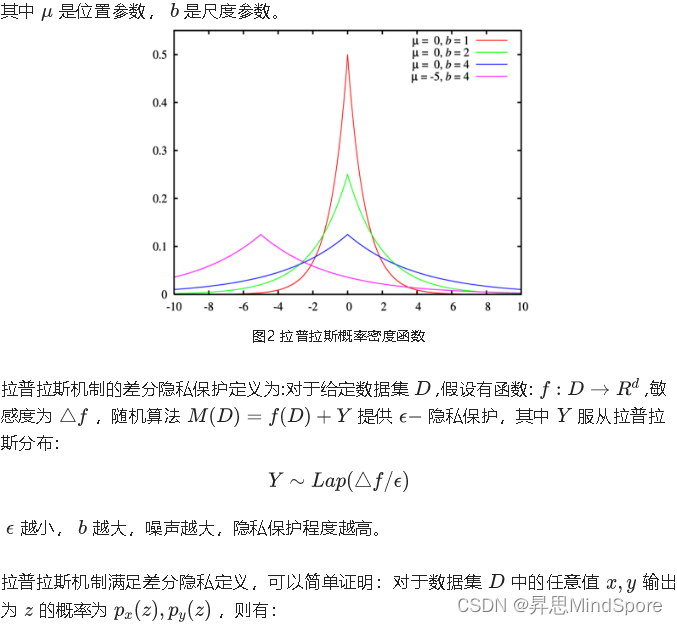
差分隐私如此优秀,那具体怎么实现呢?一个很自然而然的想法是“加噪声”。差分隐私可以通过加适量的干扰噪声来实现,目前常用的添加噪音的机制有拉普拉斯机制和指数机制。其中拉普拉斯机制用于保护数值型的结果,指数机制用于保护离散型的结果。
那什么叫适量的噪声,多少才是合适的,如何衡量呢?加入噪声的量和数据集是有关系的,年龄数据集的数据间差异就没有工资数据集的数据差异大,要添加的噪声的量就不一致。敏感度是决定该加多少噪声的重要因素。
敏感度
敏感度指数据集中删除任意一条记录对查询结果产生的最大影响。在差分隐私中有两种敏感度,全局敏感度和局部敏感度。


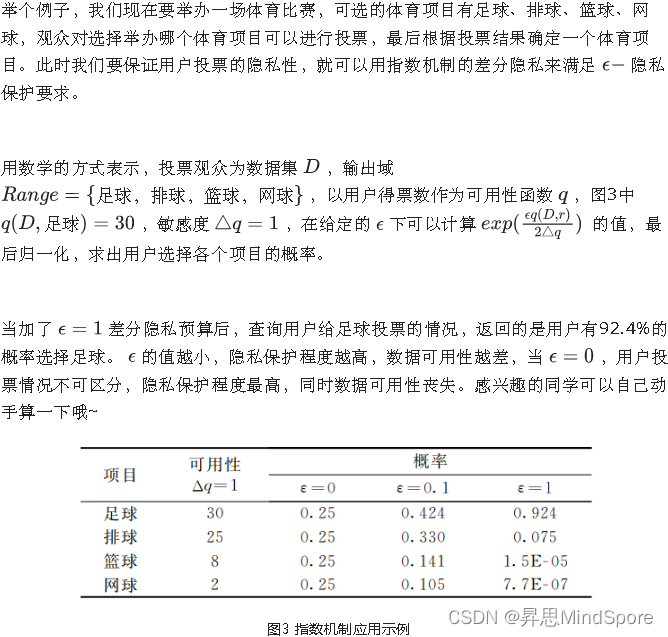

差分隐私的应用
看了以上的数学推到是不是头昏眼花了呢,其实简单来说,差分隐私的本质是"加噪",任何需要隐私保护的算法都可以使用差分隐私,由于差分隐私的串并联原理,只要算法中的每一个步骤都满足差分隐私要求,那么这个算法的最终结果将满足差分隐私特性。因此,差分隐私可以在算法流程中的任意步骤。
其实差分隐私在1977年就提出了,但是真正让它声名大噪的是2016年苹果软件工程副总裁克雷格•费德里希(Craig Federighi)在WWDC大会上宣布苹果使用本地化差分隐私技术来保护IOS、MAC用户隐私。在多个场景中成功部署差分隐私,在保护用户隐私的同时,提升用户体验。
例如,使用差分隐私技术收集用户统计用户在不同语言环境中的表情符号使用情况,改进QuickType对表情符号的预测能力。根据用户键盘输入学习新单词、外来词,更新设备内字典改善用户键盘输入体验。又例如,根据使用差分隐私技术收集用户在Safari应用使用中高频的高内存占用型、高耗能型域名,在IOS和macOS High Sieera系统里在这些网站加载时提供更多资源,以提升用户浏览体验。另外,谷歌也利用本地化差分隐私保护技术从Chrome浏览器每天采集超过1400万用户行为统计数据。
除了工业界的工程应用,差分隐私的学术研究更为广泛。目前推荐系统、社交网络分析、知识迁移、联邦学习等场景下都有差分隐私的踪迹。
MindSpore中的差分隐私实现
在MindArmour的差分隐私模块Differential-Privacy中,实现了差分隐私优化器。目前支持基于高斯机制的差分隐私SGD、Momentum优化器,同时还提供RDP(R'enyi Differential Privacy)用于监测差分隐私预算。
这里以LeNet模型为例,说明如何在MindSpore上使用差分隐私优化器训练神经网络模型。
本例面向CPU、GPU、Ascend 910 AI处理器你可以在这里下载完整的样例代码






