OCR部分
OCR,即光学字符识别,是一种将纸质文档上的文字转化为计算机可编辑文本的技术。它利用图像处理技术和模式识别算法,对扫描或拍摄的文档图片进行分析,提取出其中的文字信息。OCR技术广泛应用于文档数字化、自动化数据录入等领域,极大地提高了工作效率和准确性。随着深度学习等人工智能技术的发展,OCR技术的识别精度和效率也在不断提升,为各行业的数字化转型提供了有力支持
Tess4j部分
引入Tess4j的依赖
Tess4j是一个Java的OCR接口,可以实现识别图片中的文字的功能。使用Tess4j,需要先引入依赖:
- Gradle-Groovy:在build.gradle的dependencies下写入如下代码:
implementation 'net.sourceforge.tess4j:tess4j:5.8.0'
- Gradle-Kotlin:在build.gradle.kts的dependencies下写入如下代码:
implementation("net.sourceforge.tess4j:tess4j:5.8.0")- Maven:在pom.xml的dependencies下写入如下代码:
net.sourceforge.tess4j tess4j 5.8.0注意,Tess4j的最新版本是5.8.0,建议使用最新版本,因为老版本的识别准确率较低
下载语言包
想要让Tess4j支持中文,需要下载中文的语言包:
tessdata/chi_sim.traineddata at main · tesseract-ocr/tessdata · GitHub
使用方法
使用Tess4j实现OCR,需要先进行以下操作:
- 创建Tesseract对象
- 设置语言包的路径(目录的路径)
- 设置识别语言(中文是字符串"chi_sim")
- 调用doOCR方法执行OCR
val instance = Tesseract() instance.setDatapath("./src/main/resources/traineddata") instance.setLanguage("chi_sim") val con = instance.doOCR(File("./src/main/resources/static/t1.png"))来看一下执行结果:
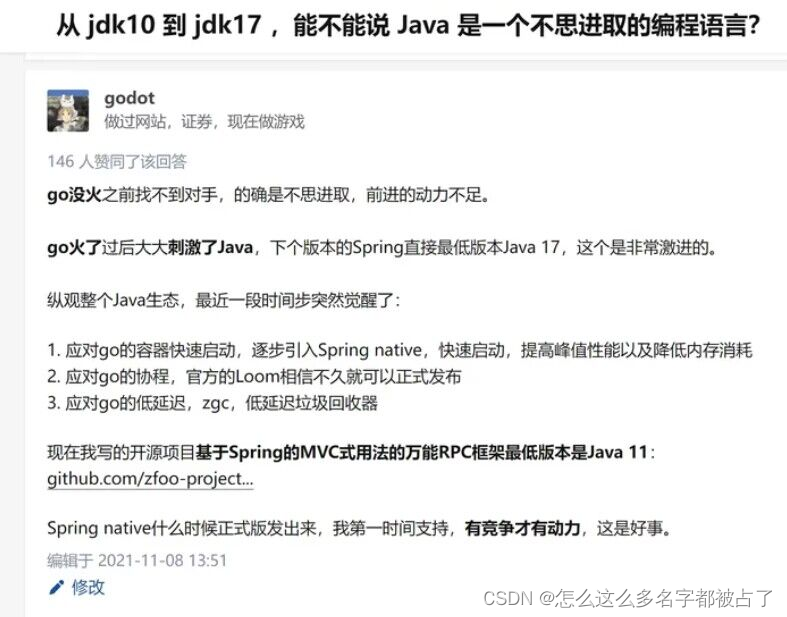 测试图片
测试图片
识别效果:
从 jdk10 到 jdk17 , 能 不 能 说 Java 是 一 个 不 思 进 取 的 缩 程 语 言 ? 髓 godot 例 江 网 站 , 证 荫 , 现 在 体 洁 成 146 人 贾 同 了 诗 @ 90 没 火 之 前 技 不 到 对 手 , 的 确 是 不 思 进 职 , 前 进 的 动 力 不 足 . g 火 了 过 后 大 大 刺 激 了 Java, 下 个 版 本 的 Spring 直 接 冉 何 版 本 lava 17, 这 个 是 非 常 漱 进 的 纠 反 整 个 Java 生 忘 , 最 近 一 殴 时 间 步 失 然 觉 醒 了 1 应 对 go 的 容 霸 快 速 启 动 , 诶 步 引 入 Spring native, 快 速 启 动 , 提 高 峰 值 性 能 以 及 降 低 内 存 消 耗 2, 应 对 go 的 协 程 , 官 方 的 Loom 相 信 不 久 就 可 以 正 式 发 市 3 应 对 go 的 伽 延 近 ,zgc, 佑 延 泉 坪 坂 回 收 躁 现 在 我 与 的 开 深 页 目 基 于 5pring 的 MVC 式 用 法 的 万 能 RPC 桂 梢 最 佑 版 本 是 Java 11: githubcoryzfoo-project. Spring native 什 么 时 候 正 式 版 发 出 来 , 我 第 一 的 间 支 持 , 有 站 争 才 有 动 力 , 这 是 好 事 编睬 于 2021-11-08 13.51 少 修 改
可以看到,它的识别效果还是不错的,但是仍然有些错误。当然可以通过提高图片的清晰度解决
Spring Boot部分
我们先来理一下思路:
- 控制器:提供一个接口,接收一个文件,返回一个字符串,为图片的识别结果
- 配置类:提供一个初始化过的Tesseract的Bean
- 服务:提供OCR服务,接收一个文件,返回一个字符串,为图片的识别结果
那么就开始吧,注意要引入依赖:
OCRConfig
package com.example.ocr.config import net.sourceforge.tess4j.Tesseract import org.springframework.beans.factory.annotation.Autowired import org.springframework.context.annotation.Bean import org.springframework.context.annotation.Configuration import org.springframework.core.io.ResourceLoader @Configuration class OCRConfig { @Autowired lateinit var resourceLoader: ResourceLoader @Bean fun getTess(): Tesseract { val path = resourceLoader.getResource("classpath:/traineddata").file.path val tesseract = Tesseract() tesseract.setDatapath(path) tesseract.setLanguage("chi_sim") return tesseract } }代码中我们创建了一个tess的Bean,构造了一个tesseract对象,并设置其语言包路径和识别语言。注意path是你存储语言包的路径。这里面我将语言包存储在了resources的traineddata包下,并使用resourceLoader.getResource()方法读取了这个路径
OCRService
package com.example.ocr.service import net.sourceforge.tess4j.Tesseract import org.springframework.beans.factory.annotation.Autowired import org.springframework.stereotype.Service import org.springframework.web.multipart.MultipartFile import javax.imageio.ImageIO @Service class OCRService { @Autowired lateinit var tesseract: Tesseract fun doOCR(file: MultipartFile): String{ val image = ImageIO.read(file.inputStream) return tesseract.doOCR(image) } }代码中我们先自动注入的一个tesseract实例(我们刚才配置的),然后定义doOCR方法,接受一个图片,返回识别结果的字符串。这个方法先通过ImageIO将MultipartFile对象转换为BufferedImage对象,并将其传入到tesseract.doOCR()方法中,返回结果
OCRController
package com.example.ocr.controller import com.example.ocr.service.OCRService import org.springframework.beans.factory.annotation.Autowired import org.springframework.web.bind.annotation.RequestMapping import org.springframework.web.bind.annotation.RestController import org.springframework.web.multipart.MultipartFile @RestController class OCRController { @Autowired lateinit var ocrService: OCRService @RequestMapping("/ocr") fun ocr(@RequestBody file: MultipartFile): String{ return ocrService.doOCR(file) } }控制器中直接调用写好的服务即可
测试结果
用postman调用接口:
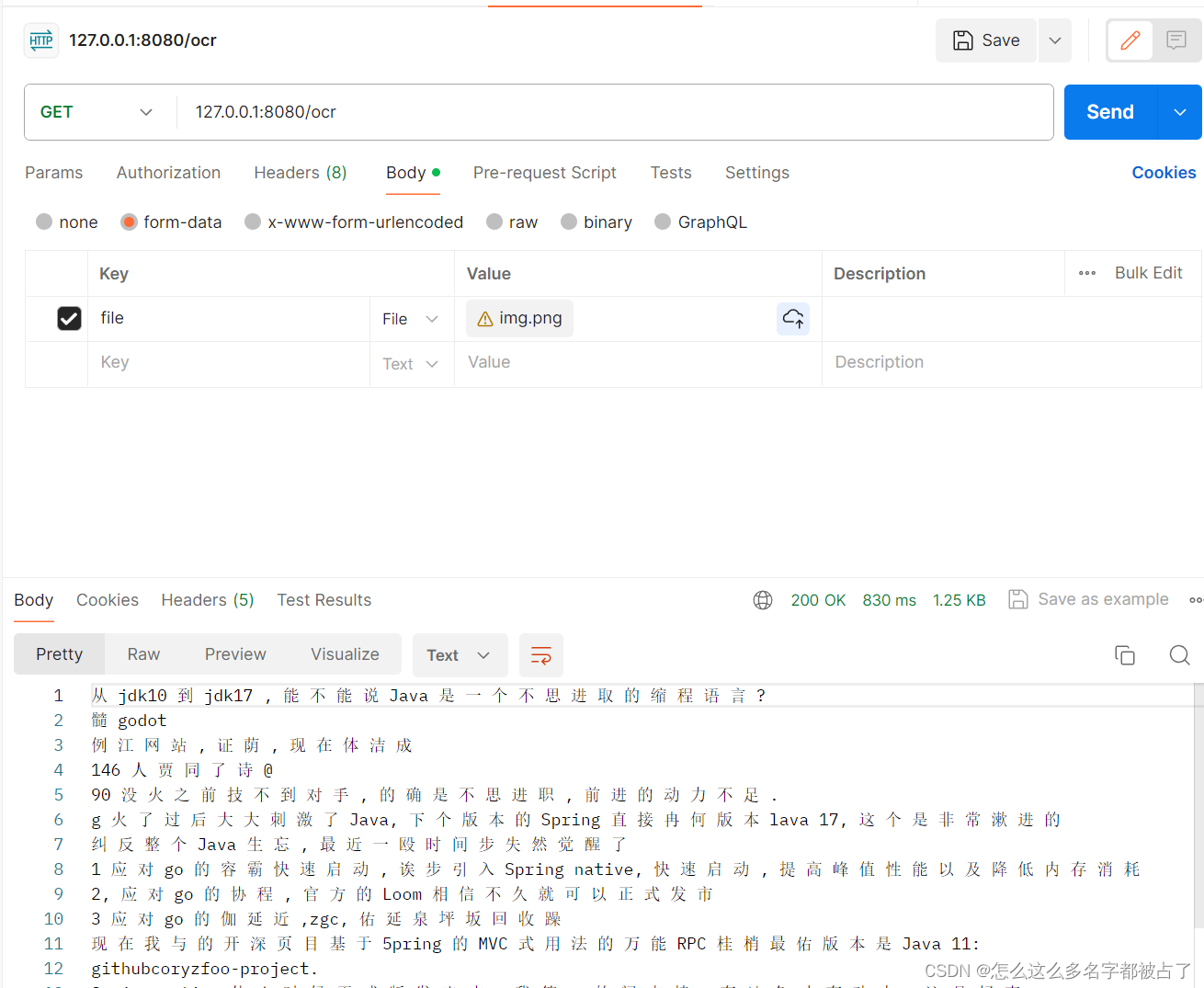
可以看到,这个接口没有问题
- Maven:在pom.xml的dependencies下写入如下代码:
- Gradle-Kotlin:在build.gradle.kts的dependencies下写入如下代码: