1、Spark是不提供文件管理系统的,但也不是只能依附在Hadoop上,它同样可以选择其他的基于云的数据系统平台,但spark默认的一般选择的还是hadoop3数据处理速度Spark,拥有Hadoop MapReduce所具有能更好地适用于数据挖掘与机;展望未来,会有更多创新将发生在云计算领域尽管在未来几年内,云服务商推出的新产品可能会继续成为重磅新闻,但云技术的真正创新将是性能和成本优化 Spark和Ray,一个是开源于2010年,专为大规模数据处理而设计。
2、云服务器以 简单高效安全可靠弹性强 等特性被越来越多的用户追崇,对于云服务器主要承载几个侧面的工作,功能层面为企业提供IaaS层硬件资源,包含数据的分布式存储分布式计算等资源层面提供资源整合动态管理,为PaaS层面提供相关;由于大数据类型实例规格采用了本地存储的架构,云服务器ECS在保证海量存储空间高存储性能的前提下,可以为云端的Hadoop集群Spark集群提供更高的网络性能机器学习和深度学习等AI应用 通过采用GPU计算型实例,您可以搭建基于。
3、4按着套餐来购买,配置的我们都用默认,暂时不要操心,等后续我们熟练了,以后买的时候再挑剔 #1605云服务器系统方面,我们选择WindowsServer2008的,Windows的系统,操作和我们的电脑基本一样,方便我们熟悉Linux;第一步收集Xshell登录信息登录阿里云管理中心,点击“云服务器ECS”和“实例”即可看到服务器信息页面点击“管理”如图所示,查看该信息中的公有IP地址第二步进入命令界面打开Xshell4,点击“用户认证”,输入;选择云主机来搭建网站,可以根据用户自己的需求来安装程序或插件,非常方便2拥有自由的磁盘空间 我们在购买网站空间时,也许选择了无线空间的共享主机,但事实上还是有限制的,比如文件数量的限制等而云服务器按照空间大小;1首先,云服务器使用Xshell 6工具远程登陆服务器2其次,关闭firewallsystemctlstopfirewalldservicesystemctldisable firewalld3最后,下载云服务器安装v2ray脚本,即可完成云服务器搭建v2节点的操作;不需要实战教程是基于yarn的spark集群,不需要像standlone模式,给每台服务器安装spark,使用spark的主从结构服务,一切资源调度都是通过yarn来完成;它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,意味着您不需要购买和维护昂贵的服务器硬件同时,Hadoop还会索引和跟踪这些数据,让大数据处理和分析效率达到前所未有的高度Spark,则是那么一个。
4、步骤1选择服务器 不同网站类型需要的ECS配置不同,请您确认网站规模与访问人数一般情况下,小型网站只需要选择基础配置即可步骤2部署网站 步骤3购买和备案域名 步骤4解析域名 至此,自助建站操作已完成,接下来您;问题一什么是云服务器? 云服务器就是在多台传统物理机集群虚拟出来的服务器,存储量大,安全,能弹性所需配置,热迁移,均衡负载等特点只要涉及到互联网IT这个行业都能用到云服务器 问题二云服务器到底是什么作用,能用来干什么。
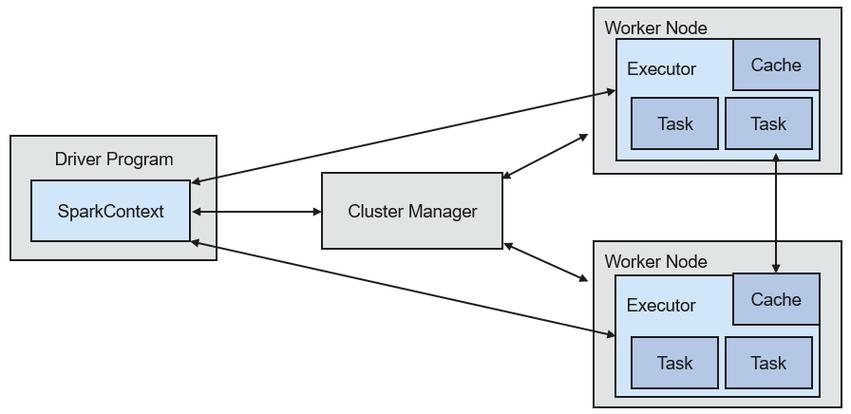
5、Dockercompose中的 sparkmaster , sparkworker 组成Spark集群 sparkmaster 与 minio1 建立容器链接,后续需要Spark读写MinIO存储部署成功后访问;第一步收集Xshell登陆信息登陆阿里云管理中心,点击“云服务器ECS”,点击“实例”,看到服务器信息页面,点击“管理”如图在此信息中查看公网IP地址第二步进入命令界面打开 Xshell 4 ,点击“用户身份验证”;企业如果想快速应用Spark 应该如何去做,具体的技术选型应该根据自己的业务场景,Docker Container因为在提升云的资源利用率和生产效率方面的优势而备受瞩目,高性能FPGA***在大数据平台上应用等项目,再去调整相关的参数去优化这些性能瓶颈,一。